1 引 言
伴随着移动互联技术的快速发展,多种自媒体互联网平台(包括博客、微博、贴吧等)逐渐成为社会公众发表观点与信息交流的主要形式之一。用户在线对社会热点事件进行信息交互,从而形成基于事件及其变异的网络舆
情[1] 。网络舆情中隐藏着网民对某些新闻话题的情感倾向,挖掘反馈信息中隐藏的情感倾向能为舆情的研判与监测提供必要的决策依据,在一定程度上影响决策者的决策方向。大数据背景下,网络舆情产生的海量交互数据使得舆情的演化形态多样,突发新闻和热点事件等舆论信息往往使舆情情感转向消极、负面方向,引起网络舆情危机[2] 。因此,挖掘网络舆情话题、判断网民情感极性及其演化等工作,对实现舆情预警、构建和谐网络舆情环境具有十分重要的作用。话题检测与跟
踪[3] (Topic Detection and Tracking,TDT)最早用于获取隐藏的话题并追踪其演化。TDT模型通过数理统计的方法实现文本降维,但无法充分利用原始语料的时间维信息解释文本话题的语义演化过程。1999年,Hofmann[4] 提出基于概率语义的索引模型(Probabilistic Latent Semantic Indexing,PLSI),该模型以隐性语义索引为基础,强调话题文本的语义可解释性,但无法处理海量文本所引起的过拟合问题。Blie等[5] 于2003年提出旨在检索潜在话题的LDA(Latent Dirichlet Allocation)模型,其核心是用低维的话题空间表示多词高维空间。LDA模型是一种多层非监督贝叶斯模型,已被广泛应用于文本信息挖掘领域。进一步地,动态话题模型[6] (Dynamic Topic Models,DTM)将时间状态空间引入LDA模型,依据时间片段记录话题强度的变化,但由于需要话题模型重构,无法进行文本在线处理。为此,Alsumait等[7] 提出OLDA模型(Online Latent Dirichlet Allocation),该模型认为话题分布具有继承性和延续性,把历史事件窗口内的话题分布作为当前时间片内的话题先验知识,在线跟踪话题内容的演化。OLDA模型虽然解决了引入新数据时的话题在线建模问题,但其未有效解决新旧话题混合所引起的话题词分布冗余问题,致使话题检测与演化分析的精准度不高。在话题检测的过程中,增加情感分析能够识别出话题中隐含的情感变化,众多学者对此进行了深入的研究与改进,主要工作包括两个方面:一方面是在LDA模型上增加情感分析参数,将话题识别与情感分析相结合,提出基于LDA的话题情感分析模型,如JST模型(Joint Sentiment Model
)[8] 、WSSM模型(Weakly Supervised Sentiment-topic Model)[9] 以及SSCM模型(Subtopic Sentiment Combing Model)[10] 等。上述模型的思想可总结为:通过构建包含话题和情感的混合模型,将依赖文本的话题挖掘拓展到依赖话题的情感挖掘,依据话题情感相似度计算,分析话题的情感演化过程。此类模型的话题参数依赖于人为主观经验且无法动态调整,无法实现情感的演化追踪。另一方面是在OLDA模型的基础上增加情感参数,以t-1时间片的情感后验作为t时间片的情感先验,动态构建不同时间片的情感分布,如TSSCM模型(Time-based Subtopic and Sentiment-topic Combing Model)[11] 和JMTS模型(Joint Multi-grain Topic Sentiment Model)[12] 。上述模型虽然能够动态识别话题,但没有考虑到不同时间片内的情感遗传强度对话题-情感分布的影响,无法有效解决因新旧话题混合所产生的情感迭代问题。针对以上问题,本文在OLDA模型的基础上引入情感强度,并提出情感迭代思想,构建一种在线话题情感识别模型,该模型使用贝叶斯方法获取动态的话题数,通过情感强度算子的遗传性构造基于时间维的话题-情感分布,并以此建立情感演化通道,高效地识别不同文本的话题情感趋势。
2 相关研究
2.1 LDA模型
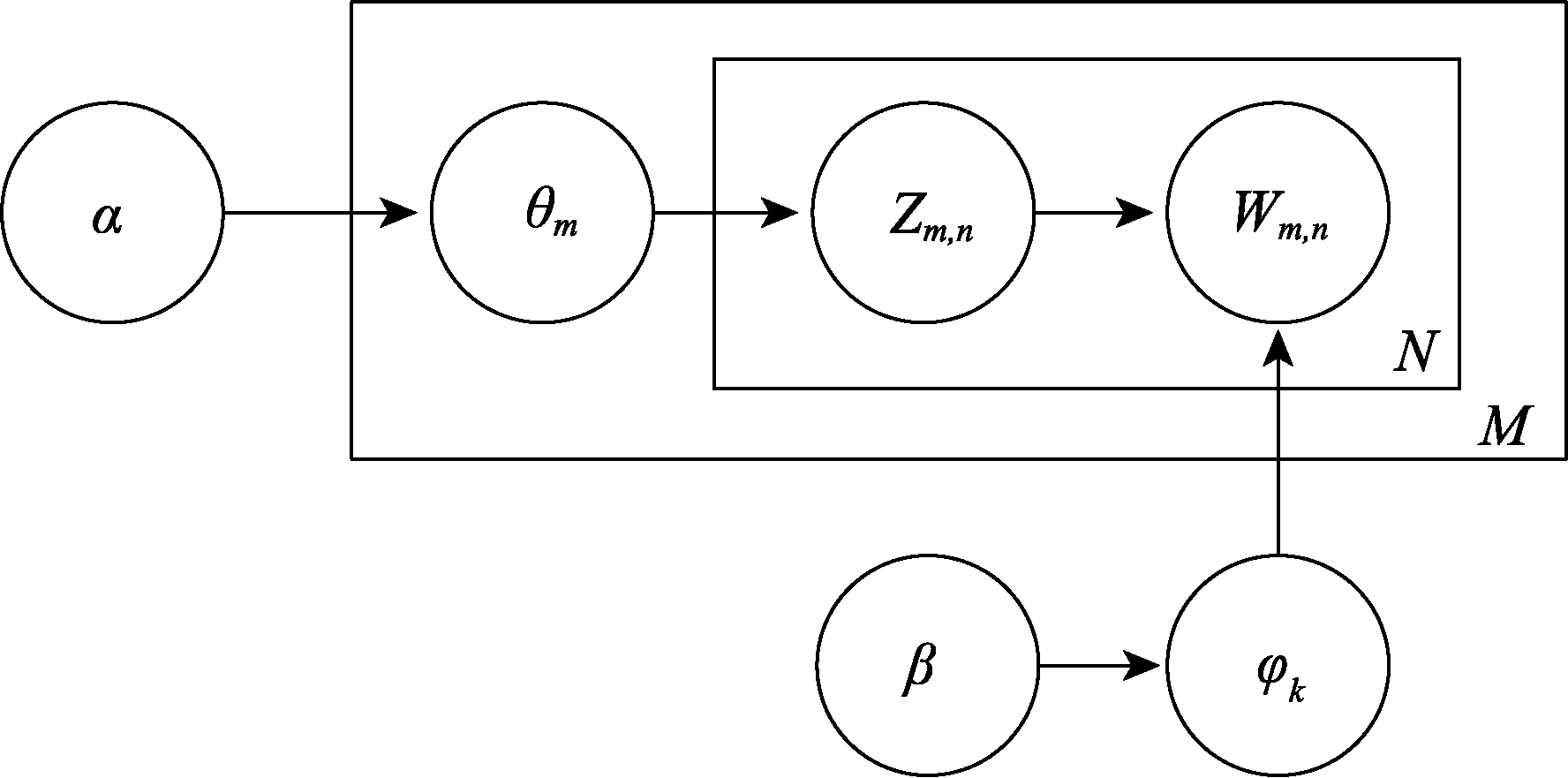
LDA模型通过引入Dirichlet先验参数构造三层贝叶斯概率网络,是一种具备文本隐藏话题生成能力的无监督学习模
型[13,14] 。该模型将文档、话题、词的三层结构关系描述为:多个话题在每个文档中均存在概率依赖,每个话题又是依概率收敛于某个话题词。因此,话题是词表上的一个多项分布,多个话题的混合构成文档,多个特征词的混合构成话题。假设文档d包含的文档数为M,话题数为K,词汇集为V,用户需要设定参数α和β,通过构造文档-话题分布θm (θ={θm(d) | d ∊ D})和话题-词分布φk (φ={φk | k ∊ [1,k]}),得到文档库中第m个文档第n个词汇wm,n,其结构如图1所示。LDA模型的核心过程描述如下:①设定参数α并抽样生成文档-话题分布θm,即θm ~ Dir(α);②从θm分布中抽样生成文档m的第n个词话题Zm,n,即Zm,n ~ Mult(θm);③设定参数β并抽样生成话题Zm,n及其对应的话题-词分布φk,即φk ~ Dir(β);④从φk分布中抽样生成文档m的第n个词wm,n,即wm,n ~ Mult(φm,n)。2.2 OLDA模型
OLDA模型在LDA模型的基础上引入时间粒度,使其具备了在线检测话题差异性和延续性的能
力[15] 。通过动态调整时间片尺寸,满足用户在时间维上对语料分析的粗粒度需求。在处理流文本数据时,该模型认为话题间的连续性依靠先验和后验概率保持,即式中,ηδ是前δ个时间片上的话题-词分布的遗传度,统计前δ个时间窗口
(2)
式中,
式中,
2.3 话题情感建模
在情感分析过程中,通常在情感词典的帮助下抽取文本中的情感特征词并计算其情感极性,总体上可分为两个阶段:①建立情感词表集合;②使用相似度计算(Similarity Calculation)或引导模型(Bootstrapping)等情感分析算法确定情感特征词之间的语义距离,获取情感语义模型。
条目间互信息(Mutual Information,MI)被广泛用于计算条目对(i1, i2)之间的语义距离相似
度[16] 。情感特征词的情感值一般可通过计算其特征权重值获得,而特征权重的赋值依赖于条目词表组合之间的相似度距离。基于MI的情感词表生成模型在索引阶段,通过计算混合文档的初始频率值,获取文本集中的所有情感词,其时间复杂度为O(|d2|)(其中,d为文档大小),空间复杂度为O(|T2|)(其中,T为条目数)。互信息计算公式为式中,p(ti, tj)表示ti和tj共现于相同文档中的概率;p(ti)和p(tj)分别表示文档包含ti和tj的概率。上述概率可利用极大似然估计在初始语料库中获取。
情感词典中的情感极性具有3种:正情感、负情感和中立情
感[17] 。情感倾向分类一般通过设定情感阈值,并将计算出的新条目i1与已知情感条目i2的互信息相比较,若MI(i1, i2)小于该阈值,则将(i1, i2)放入不同的情感倾向性集合。情感词典中往往包含情感词语、转折连词以及否定词等多种词语,为避免在多词融合中出现情感消融现象,在计算新词(情感词、否定词)的特征权重值之前,需要使用转折连词之后的条件分句代替整个语句。采用多特征线性融合方法计算综合情感值,能够有效避免情感倾向的不确定性,其计算公式为
式中,inew表示新词;ipos与ineg分别表示旧词中已分类的正情感词和负情感词;neg是新词所在句的否定标志,当neg=1时,表明新词右侧没有否定词,情感倾向与前方情感特征词一致,当
Oneg (inew)>0时,表示inew具有正倾向,加入正情感词集;SOneg (inew)<0时,表示inew具有负倾向,加入负情感词集;SOneg (inew)=0时,表示没有情感倾向。3 研究方法
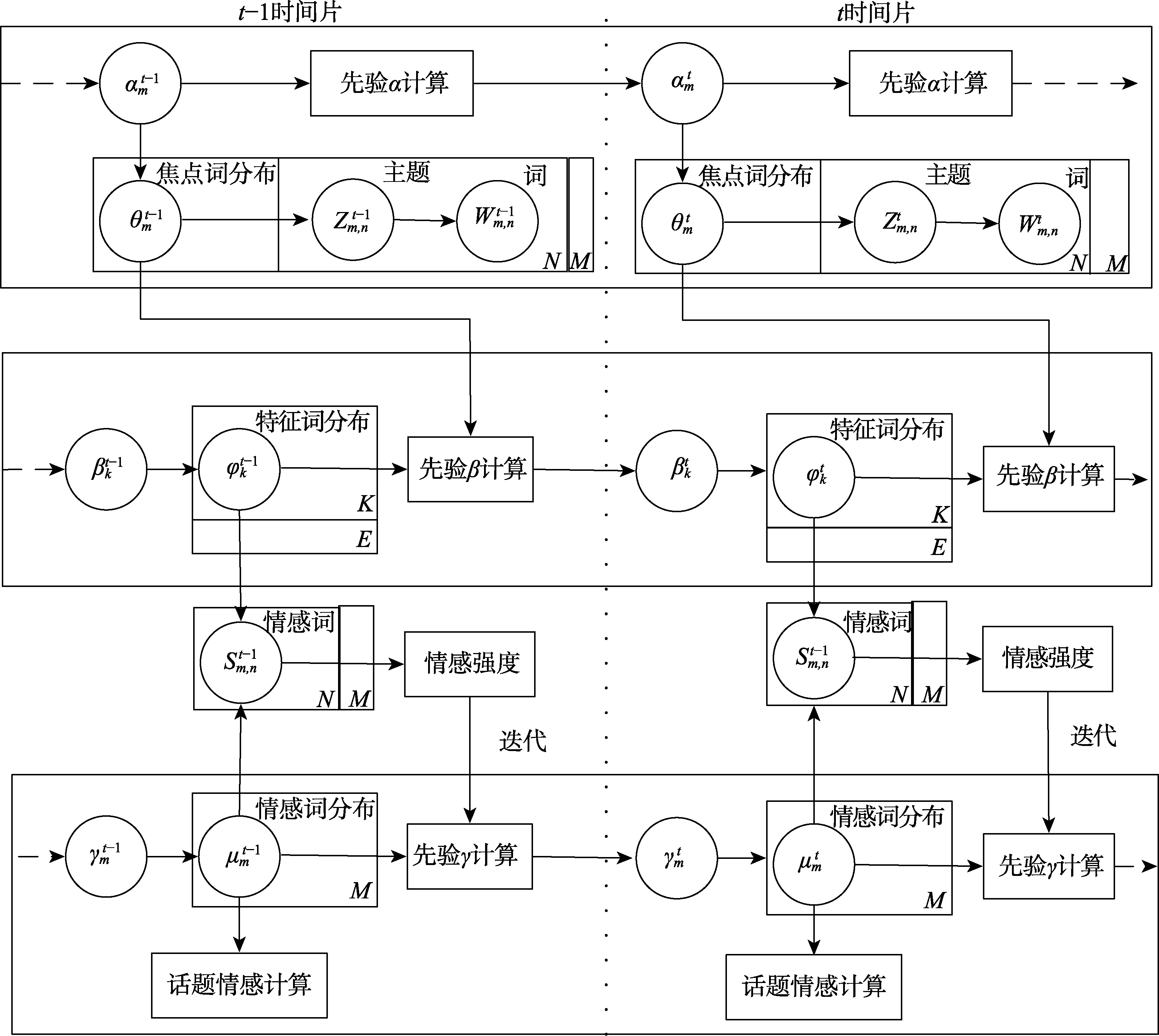
虽然OLDA模型能够识别在线文本流话题,但存在冗余话题词,且无法分类隐藏在话题内的情感倾向,所以本文将情感强度引入OLDA模型,参照OLDA模型中话题分布的遗传度,提出情感迭代思想,在时间维度上检测“情感遗传”和“情感变异”,构建在线话题情感识别模型OTSRM(Online Topic and Sentiment Recognition Mode)。该模型的核心思想是:在线文本流是包含多个特征词以及情感词的混合,t-1时间片内的文档-话题、话题-词以及文档-情感分布均是t时间片内的各自分布的先验,使用情感强度表达话题情感在不同时间片内的遗传强度,即将
3.1 OTSRM模型描述
设t时间片的焦点词Nt包含Kt个特征词和Mt个情感词,该模型首先依据
3.2 情感强度计算
OLDA模型通过话题遗传度w维持前后话题间的延续性,假设t时间片的变量分布仅受t–1时间片的影响,而与之前时间片内的文本信息无关,则可将其视为话题遗传。OTSRM模型参照话题遗传的性质,将情感迭代思想引入情感分析,把t时间片的话题-情感分布μmt视为
情感强度与话题强度类似,能够在时间维度上动态衡量话题情感的稳定程度。描述某个话题的文档一般在少量话题上具有较高的概率分布值,而描述某个话题的情感词也会在一个或少量话题上呈现相对较高的概率分布值。类似地,若某个话题在各个情感词上的概率分布较为平均,则可以判定该文档表达的情感较为均衡且没有明确的情感倾向。本文使用Shannon信息
熵[18] 表示话题的情感集中程度,归一化后的话题情感权重Wmt的计算如公式(7)和公式(8)所示:式中,
式中,Rmt–1表示
经过计算得到各个话题的情感权重之后,话题情感强度J(zkt)的计算公式为
式中,μm,kt–1表示
3.3 迭代模型求解
OTSRM模型以显性变量时间t和词wm,n为初始输入值,以话题变量z和情感变量s为隐变量,采用改进的Gibbs采样算法求解话题分布θ、特征词分布φ以及情感分布μ的联合后验概率函数,计算公式为
式中,(nj,s(di))t表示t时间片文档di中特征词j分配到情感
表1 OTSRM模型算法描述
Input:α, β, γ, t=1 Output:θ, φ, μ 1. GetSet{Dt,Vt}
2. //获取t时间片下的文档数据集及对应分词表
3. IF t=1 Then 4. αt = α, βt = β, γt = γ; 5. Else 6. For k=1 to Kt
7.//计算话题情感权重与情感强度
8. Calculate Wmt,J(zkt)
9. //创建t–1时间片话题与情感矩阵
10. Generate At–1,Bt–1,Rt–1
11. //计算t时间片模型超参
12. Calculate αt,βt,γt
13. //进行Gibbs采样,得到稳定的概率分布
14. Run Gibbs(αt,βt,γt)
15. For eachw∈di
16.//选择话题特征词和情感词
17. Choose a w from φt where w ~Multi(Kt)
18. Choose a w from μt where w ~Multi(St)
19. End For
20. Get θt,φt,μt
21. End For
22. End IF
3.4 话题情感计算
3.4.1 话题相似度计算
度量两个概率分布之间相似度的常用方法是KL距离。相邻时间片内的话题-词分布差异性计算也可采用KL距离表示,但由于KL距离存在非对称性,无法求解对称的话题分布函数。本文将相对熵引入话题的相似度度量,建立基于相对熵的话题相似度计算,具体公式为
式中,p(w)和q(w)分别表示特征词w在话题Zt和Zt–1分布中出现的概率。
3.4.2 话题情感相似度计算
OTSRM模型通过计算不同话题下情感词的最大情感值,建立依赖于情感词集合的话题情感模型。具体计算方式为:首先确定话题z的情感词wi所在的语句位置,判定其所在语句是否存在转折连词和否定词,获取其否定标志neg的值,并将结果代入情感S(wi)的计算,具体为
式中,L(wi)表示修饰程度词数值;S
Oneg (wi)表示wi的综合情感值。最后将话题z下的所有情感词的期望作为其最终的情感值,计算公式为4 实验数据及结果分析
4.1 数据来源及预处理
本文实验数据来源于新浪新闻和腾讯新闻。通过GooSeeke
r[19] 网络爬虫软件筛选了5个网络热点事件作为实证分析案例,具体数据统计信息如表2所示。表2 实验数据集
编号 事件名 文本数 时间跨度 Data1 昆山杀人案 2156 2018.8.27—2018.9.1 Data2 王凤雅事件 1985 2018.5.24—2018.5.31 Data3 奔驰车失控事件 1557 2018.3.15—2018.5.30 Data4 高铁占座事件 2331 2018.8.21—2018.9.3 Data5 长生疫苗事件 2689 2018.7.11—2018.7.22 受限于篇幅,本文仅以Data1为例来说明OTSRM的话题情感演化分析过程。首先,使用中文分词软件NLPIR将文本切分成词语集,同时过滤停用词。然后,将属于相同时间片的报道文本dct及其评论djt所对应的词语集合并成混合词语集Dct,以事件发生之日起(t=1)连续采集6天,并按天划分为6个时间片,统计t=1天评论djt中的情感词频。最后,依次对t时间片的词语集进行建模,并依据OTSRM模型建立在线情感词典。
4.2 结果分析
OTSRM模型在t=1时间片时,将αt、βt、γt 的初值分别设置为0.5、0.1、0.1,话题特征词Wc和情感词Ws设置为15,话题特征的概率生成阈值以及情感阈值均为0.2,并设定Gibbs抽样2000次。
4.2.1 话题识别
OTSRM模型识别出的话题特征词及其对应的概率分布如表3所示,每个话题使用概率较高的前10个特征词表示。
表3 “昆山杀人案”话题特征词识别结果
话题 特征词及其概率 报道时间及其概率 1 昆山 0.013/交通 0.011/砍 0.009/宝马男 0.012/纠纷 0.016/电动车 0.007/死亡 0.017/追 0.019/受伤 0.013/捡起 0.012 t1 0.218,t2 0.257,t3 0.201,t4 0.233,t5 0.246,t6 0.225 2 检察院 0.021/立案 0.022/冲突 0.022/报警 0.022/警情 0.022/急救 0.022/醉酒 0.022/伤害 0.022/控制 0.022/涉嫌 0.020 t2 0.235,t3 0.271,t4 0.203,t5 0.239,t6 0.225 3 纹身 0.021/前科 0.019/涉黑 0.021/见义勇为 0.021/典当铺 0.021/重担 0.020/患病 0.019/困难 0.019/贷款 0.019/天安社0.019 t2 0.243,t3 0.296,t4 0.233,t5 0.277 4 正当 0.032/安全 0.032/过度 0.032/区别 0.032/躲避 0.032/跑 0.032/冷静 0.032/法律 0.032/伤害 0.032/主观 0.032 t3 0.312,t4 0.217,t5 0.296,t6 0.211 5 通报 0.032/正当 0.032/防卫 0.032/撤销 0.032/刑责 0.032/惩恶 0.032/无罪 0.032/免于 0.032/认定 0.032/符合 0.032 t5 0.326,t6 0.203 注:ti表示事件在第i天发生。
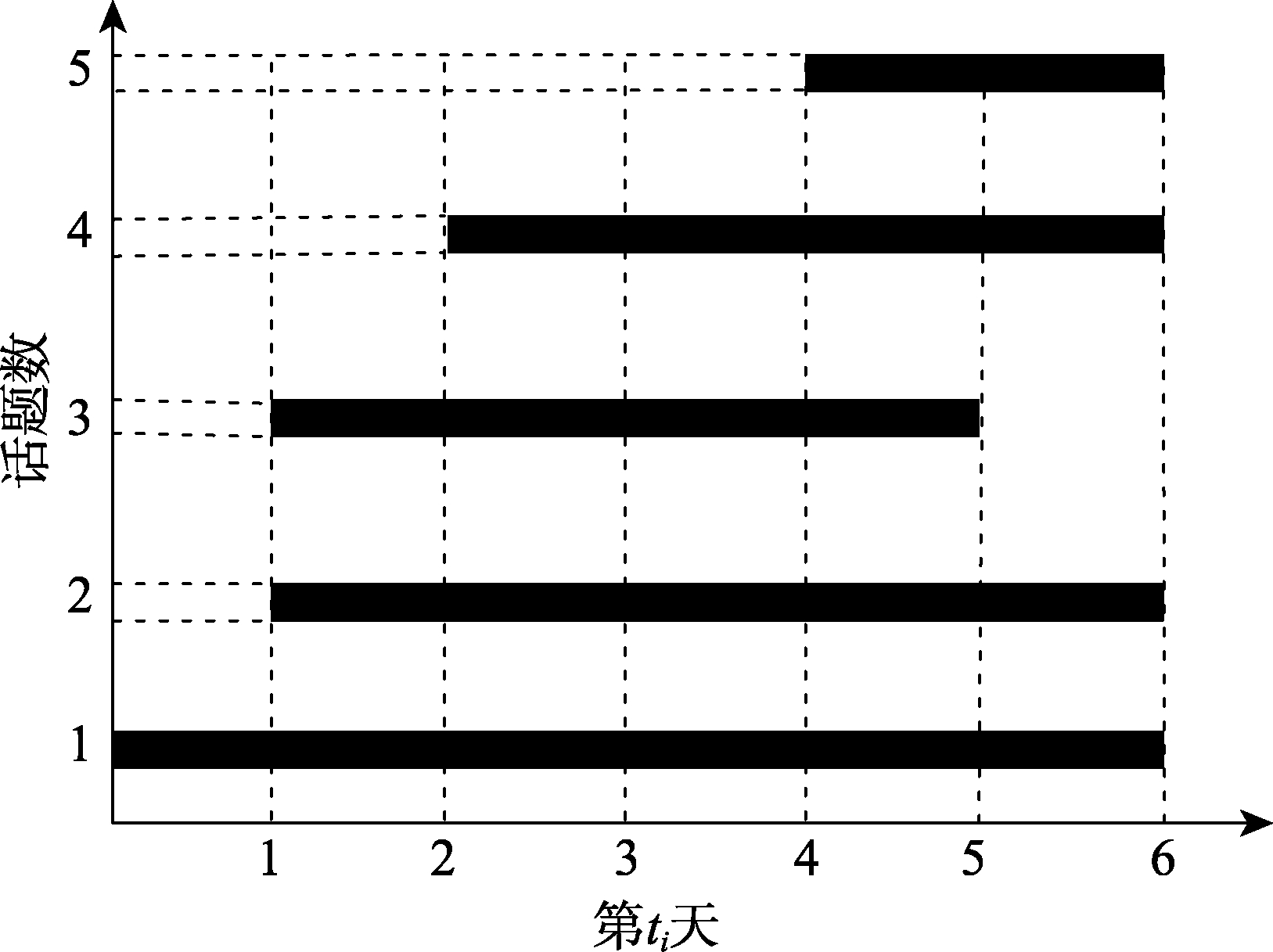
从表3可以看出,昆山杀人案事件包含5个报道话题。话题1:昆山发生由交通纠纷引发的命案,持续时间是t1~t6;话题2:检察机关立案调查,持续时间是t2~t6;话题3:涉事双方背景报道,持续时间是t2~t5;话题4:如何判定正当防卫,持续时间是t3~t6;话题5:警方给案件定性,持续时间是t5~t6。依据表3,可以得到所有话题在不同时间片的演化过程(如图3所示)。
从图3可以看出,不同的话题在时间维度上出现了话题共存,如话题2和话题3在t2~t5时间片内重叠,即“检察机关立案调查”与“涉事双方背景报道”共存于多个新闻报道中,体现了新闻报道视角的多样性。
4.2.2 情感演化分析
依据话题-情感分布,计算t1~t6时间片的情感强度,得到话题-情感矩阵;同时选择话题情感词,并通过公式(18)计算出不同时间片的话题情感值。以话题1为例,表4是识别出的情感结果。受限于篇幅,其他话题识别结果与话题1类似,在此不再赘述。
表4 话题1在t1~t6时间片的情感识别结果
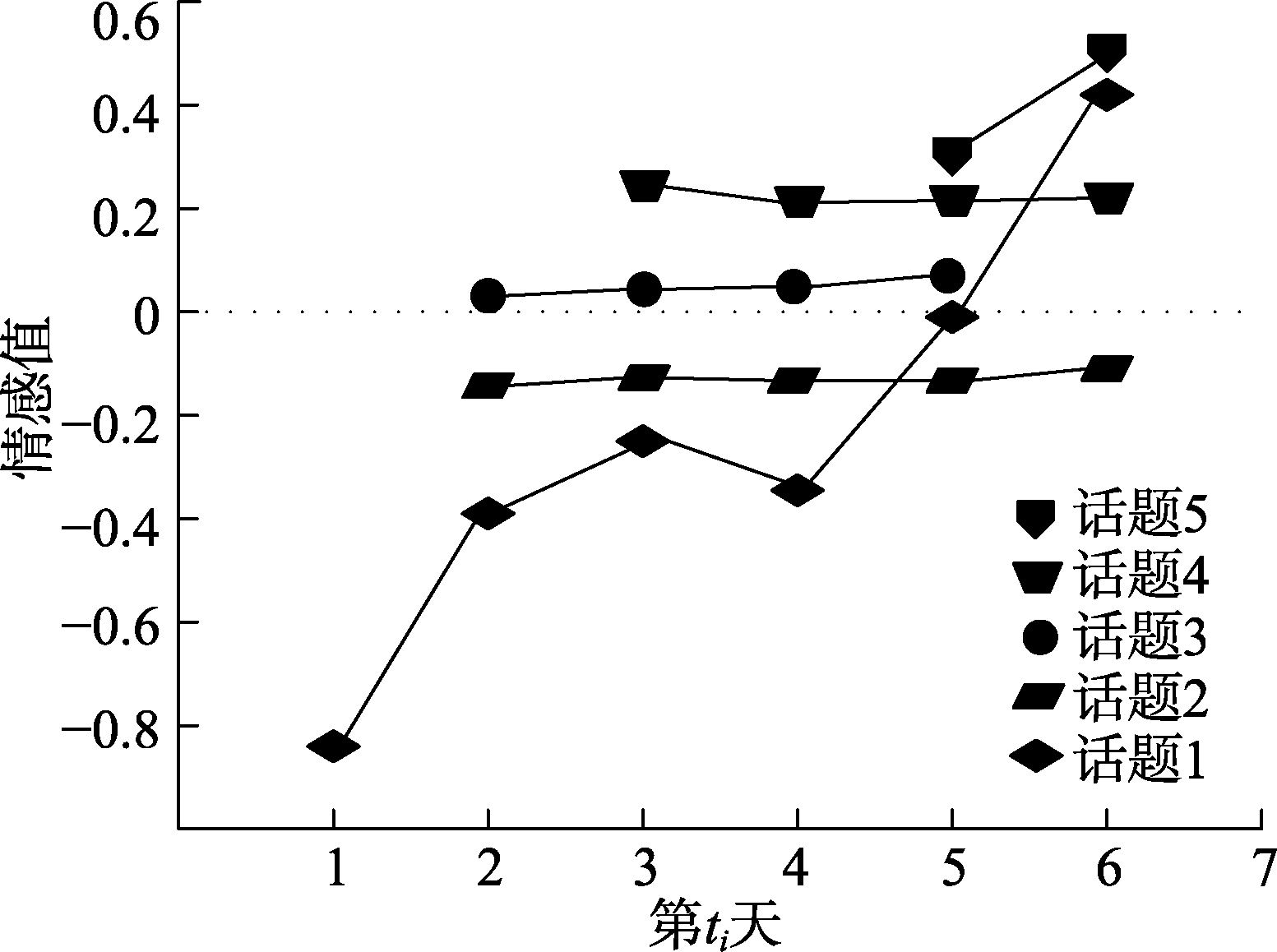
时间 情感词及其概率 情感值 t1 人渣 0.015/活该 0.017/无罪 0.021/解气 0.018/该死 0.026/严惩 0.017/冲动 0.026/勇气 0.013/显摆 0.011/畜生 0.015 -0.78 t2 伤害 0.014/释放 0.022/彻查 0.013/快 0.016/愤怒 0.017/赔偿 0.014/猖狂 0.018/轻判 0.015/期待 0.018/无罪 0.026 -0.42 t3 严打 0.016/失望 0.017/可恶 0.021/死 0.016/可怜 0.017/同情 0.018/释放 0.019/可惜 0.022/重判 0.017/嚣张0.018 -0.26 t4 恶霸 0.031/无奈 0.029/支持 0.036/顶 0.021/无罪 0.032/人渣 0.024/过分 0.024/悲哀 0.027/除害 0.029/坐等 0.033 -0.34 t5 杀 0.031/正当 0.036/无奈 0.027/可恶 0.027/可怜 0.032/判 0.028/解气 0.034/同情 0.031/可恨 0.026/铲除 0.032 0.16 t6 希望 0.027/支持 0.034/点赞 0.029/顶 0.035/正气 0.028/公平 0.032/正义 0.027/伸张 0.029/开心 0.029/挺住 0.027 0.43 为了更加清晰地表现OTSRM模型在Data1上的情感演化识别过程,分别计算出5个话题在不同时间片下的话题情感值,得出动态的评论情感信息演化图,结果如图4所示。
从图4可以看出,话题情感随时间呈现为动态演化。话题1的话题情感波动较大,其原因是在事件初始阶段,网民集中表达了对“宝马男”的谴责与愤怒,体现了强烈的负情感;到t=4时,民众关注的话题逐渐转向对正当防卫判定条件的讨论,表达了对于海明的同情,所表现出的正情感抵消了部分负情感,所以整体情感值为低强度负情感;到t=6时,随着警方将案件定性为正当防卫,民众的正情感达到了最高值,出现了较强的正情感。
话题2和话题3的话题情感在中性情感附近,集中体现了民众纠结与困惑的心态,即对正当防卫与防卫过当的界定条件存在不解,民众都在对最终定论进行猜测,没有明确的情感倾向性。话题4表现出了较为稳定的正情感,民众对正当防卫中弱势一方的同情占主导。话题5表现出了强烈且稳定的正情感,民众的情感与话题1后期的情感倾向相似,都表达了对司法部门维持社会正义的坚定支持。
4.3 模型评价
为了验证OTSRM模型的算法性能,依据上述实验过程,将表2中的其他4个事件的数据集分别代入模型,得到类似的实验结果。另外,本文使用正确率、召回率以及F值3项指标,与文献[8,9,10,11]提供的算法作为对比,进行综合评价。其中,将上述模型的超参αt、βt和γt 的初值分别设置为0.5、0.1和0.1,话题特征词Wc和情感词Ws设置为15,话题特征的概率生成阈值以及情感阈值均为0.2,并设定Gibbs抽样1000次。5种模型在5种数据集上的正确率和召回率分别如表5和表6所示,F值对比结果如图5所示。
表5 情感识别正确率对比
模型 Data1 Data2 Data3 Data4 Data5 JST 66.16 67.09 69.81 71.36 72.95 WSSM 68.82 72.64 65.38 74.91 73.66 SSCM 74.46 75.92 72.65 75.64 74.68 TSSCM 77.68 78.84 76.31 78.88 79.35 OTSRM 78.94 80.13 79.96 81.03 80.62 表6 情感识别召回率对比
模型 Data1 Data2 Data3 Data4 Data5 JST 76.35 74.32 77.45 78.62 76.64 WSSM 77.92 78.94 74.49 79.78 78.26 SSCM 79.81 80.18 79.46 80.46 79.98 TSSCM 81.67 83.94 82.16 83.37 82.21 OTSRM 83.33 84.62 82.77 85.56 84.33 从图5可以得出,TSSCM和OTSRM模型在情感分类上性能明显优于JST、WSSM和SSCM模型,原因是基于OLDA模型的算法综合考虑了不同时间片的话题关联性,依据概率话题动态设置话题数目,达到话题时空建模的目的,而JST、WSSM和SSCM模型的先验话题情感参数受主观经验影响较大,易造成情感挖掘斜偏,从而降低了分类的准确性。TSSCM模型虽然能够动态识别话题,但没有考虑到话题情感强度的传递性,无法有效解决因新旧话题混合所产生的情感迭代问题。本文算法弥补了上述算法的不足,通过引入带有遗传性的情感强度,动态获取不同时间片的话题,建立话题与情感共存的混合模型,有效提高了话题与情感的识别精度。
5 结 语
本文深入分析了话题情感的计算方法,提出一种情感迭代思想,构建了在线话题情感识别模型OTSRM。该模型通过构造情感强度算子,建立基于后验概率的情感演化通道,获取特征词与情感词分布矩阵;再使用相对熵方法计算当前话题焦点的最大情感值,从而动态地表示文本的话题情感演化过程。实验进一步验证了OTSRM模型在话题情感演化分析上具有良好的性能。
参考文献
- 1
黄晓斌, 赵超. 文本挖掘在网络舆情信息分析中的应用[J]. 情报科学, 2009, 27(1): 94-99.
- 2
聂峰英, 张旸. 移动社交网络舆情预警指标体系构建[J]. 情报理论与实践, 2015, 38(12): 64-67.
- 3
Li G, Jiang S, Zhang W, et al. Online Web video topic detection and tracking with semi-supervised learning[J]. Multimedia Systems, 2016, 22(1): 115-125.
- 4
Hofmann T. Probabilistic latent semantic indexing[C]// Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. NewYork: ACM Press, 1999: 50-57.
- 5
Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(9): 993-1022.
- 6
Blei D M, Lafferty J D. Dynamic topic models[C]// Proceedings of the 23rd International Conference on Machine Learning. NewYork: ACM Press, 2006: 113-120.
- 7
Alsumait L, Domeniconi C. On-line LDA: Adaptive topic models for mining text streams with applications to topic detection and tracking[C]// Proceedings of the Eighth IEEE International Conference on Data Mining. IEEE Computer Society, 2008: 3-12.
- 8
Lin C, He Y, Everson R, et al. Weakly supervised joint sentiment-topic detection from text[J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(6): 1134-1145.
- 9
Pavitra R, Kalaivaani P C D. Weakly supervised sentiment analysis using joint sentiment topic detection with bigrams[C]// Proceedings of the International Conference on Electronics and Communication Systems. IEEE, 2015: 889-893.
- 10
周文, 张书卿, 欧阳纯萍, 等. 基于情感依存元组的新闻文本主题情感分析[J]. 山东大学学报(理学版), 2014, 49(12): 1-6, 11.
- 11
Liu Y, Guo Q, Wu X, et al. Evolution identification approach for news public opinion based on TSSCM[J]. Journal of Intelligence, 2017, 36(2): 115-121.
- 12
Alam M H, Ryu W J, Lee S K. Joint multi-grain topic sentiment: Modeling semantic aspects for online reviews[J]. Information Sciences, 2016, 339: 206-223.
- 13
Lim K W, Buntine W. Twitter opinion topic model: Extracting product opinions from Tweets by leveraging hashtags and sentiment lexicon[C]// Proceedings of the 23rd ACM International Conference on Information and Knowledge Management. New York: ACM Press, 2014: 1319-1328.
- 14
黄卫东, 陈凌云, 吴美蓉. 网络舆情话题情感演化研究[J]. 情报杂志, 2014(1): 102-107.
- 15
Rao Y. Contextual sentiment topic model for adaptive social emotion classification[J]. IEEE Intelligent Systems, 2016, 31(1): 41-47.
- 16
Steuer R, Kurths J, Daub C O, et al. The mutual information: Detecting and evaluating dependencies between variables[J]. Bioinformatics, 2002, 18(Suppl 2): S231-S240.
- 17
Haselmayer M, Jenny M. Sentiment analysis of political communication: Combining a dictionary approach with crowdcoding[J]. Quality & Quantity, 2017, 51(6): 2623-2646.
- 18
Moreira C, Wichert A. Finding academic experts on a multisensor approach using Shannon’s entropy[J]. Expert Systems with Applications, 2013, 40(14): 5740-5754.
- 19
GooSeeker. MetaSeeker[EB/OL]. [2016-08-16]. http://www.gooseeker.com/product.
- 1
摘要
舆情话题检测与情感演化分析在舆情监控中起着非常重要的作用,但当前方法存在着情感话题含义不明确、情感态势评估不精确等问题。在OLDA(Online Latent Dirichlet Allocation)模型的基础上引入情感强度,并提出一种情感迭代思想,构建在线话题情感识别模型OTSRM(Online Topic and Sentiment Recognition Mode)。该模型通过增加基于β先验的情感遗传度,建立情感演化通道,获取特征词、情感词2个分布矩阵,最后使用相对熵方法计算话题焦点在相邻时间片段上的最大情感值,从而高效地识别不同文本的话题情感。在5个网络事件数据集上对OTSRM模型进行有效性验证,并与主流模型进行了对比,实验表明OTSRM模型在舆情话题识别与话题情感演化分析方面实现了良好效果。
Abstract
The sentiment evolution of online public topics plays a very important part in the analysis of public opinion, while current methods have problems such as unclear meanings of sentiment topics and inaccurate evaluation of sentiment evolution. This paper introduced sentiment intensity based on the OLDA model and proposed an Online Topic and Sentiment Recognition Mode (OTSRM). By adding sentiment heritability with a β prior parameter, this model established a sentiment evolution channel and obtained two distribution matrices of feature words and sentiment words. Finally, the relative entropy method was proposed to calculate the maximum value of topic sentiment in adjacent time segments, thereby efficiently identifying the topic sentiment of different texts. The effectiveness of OTSRM was validated using five network datasets and compared with other state-of-the-art models. The experiments showed that our approach achieved good results in the recognition of topic sentiment.