1 简 介
随着科学技术的迅速发展,许多科学问题的解决需要不同研究方向的科研工作者合作完成,从而提高科研效率,推动重大技术难题的攻克。因此,如何促进科研合作团队的组建引起了国内外学者的关注。其中,科研合作预测成为一种重要的研究领域。科研合作预测通常将科研工作者抽象为一个节点,将他们之间的合作关系抽象为一条边,形成一个科研合作网络,基于这个网络,进行链接预测。链接预测是一个重要的社会网络分析问题,在链接预测任务中,目标既包括预测未来可能产生的新链接,也包括目前尚未发现的链接;对应到科研合作预测当中,目标是预测未来可能会发生合作的科研工作者。
目前基于链接预测的科研合作推荐通常是基于网络节点信息、兴趣模型和传统特征工程等方面进行,一定程度上取得了显著的成果,但仍存在以下几个问题:
(1)现有的研究仍多是基于邻居节点或路径等传统的链接预测方法,在复杂网络中,这些预测指标难以准确地表示出网络结构,并且其计算复杂度呈现指数增长,不仅达不到理想的预测效果,也无法适应大数据环境下的科研合作预测。
(2)科研合作预测一般在较小规模的学术论文合著网络上进行,但随着数据集规模的扩大,合作网络的结构逐渐变得复杂。另一方面,由于存在一些合著较少的科研合作者,网络图的度分布呈现幂律分布的形式,大量的科研工作者出现在其长尾部分,使得科研合作预测主要集中在合著较多的作者上,一些处于网络边缘部分的作者没有得到足够的重视。因此,需要在一个没有对节点的度设定阈值的网络上,对所有的研究者进行科研合作预测研究。
(3)机器学习算法为大规模科研网络的研究提供了必要的模型和工具。但是,一些涉及机器学习的科研合作预测研究把工作重心放到了针对特定的数据人工设计出有价值的特征上,随着数据规模扩大,特征工程需要耗费更多的人力,对特征设计者在专业领域知识方面的要求也越来越高,这说明传统的机器学习方法在很大程度上依赖于特征的设计。因此,如何自动抽取出科研工作者之间的特征成为一个亟待解决的问题。
(4)随着社交网络研究的兴起,将网络表示学习应用到科研合作预测是必然的趋势。网络表示学习可以将网络中的节点表示为低维向量,虽然近几年有学者尝试将网络表示学习应用到科研合作预测中,但仅仅是将学习到的网络表示基于向量相似度指标来计算出科研工作者之间的语义相似度,而没有将得到的向量表示作为机器学习的特征输入;同时,这些研究大多只着眼于将单个网络表示学习模型应用于科研合作预测,而没有尝试提出并应用新模型。
鉴于此,本文将基于现有的网络表示学习模型,提出一种融合节点位置信息和网络结构信息的科研合作推荐模型。该模型对大规模的科研合作网络进行特征自动提取,并与机器学习算法相结合,提高科研合作预测的效果,进而为相关研究提供借鉴。
2 相关研究
2.1 网络表示学习
在有关网络的研究中,一个重要的问题就是如何准确地表示网络信息。传统的网络表示一般使用高维的稀疏向量,但是高维的向量将会花费更多的运行时间和计算空间。随着表示学习技术在自然语言处理等领域的发展和广泛应用, 研究者们转而探索将网络中的节点表示为低维稠密的向量表示的方法。现有的研究工作主要划分为两类,即基于矩阵特征向量计算的方法和基于深度学习的方法。
基于矩阵特征向量计算的方法也称为谱聚类算法,这一类算法通过计算关系矩阵的前k个特征向量或奇异向量来得到k维的节点表示。这类方法与降维技术相似,但其计算复杂度高,模型效果不理想,难以应用于大规模的网络分析。
近年来,由于深度学习技术在图像识别、语音处理和自然语言处理等多个领域都取得了巨大的成就,因此,Perozzi
等[1] 首次将深度学习应用在网络分析当中,提出了DeepWalk算法。算法通过建立随机游走的模型,将网络图转化为节点序列,再利用神经语言模型Skip-Gram训练节点向量。Grover等[2] 则设计了node2vec算法,这种算法结合了深度优先和广度优先的搜索策略,设计了带参数的随机游走方法,通过调整参数来控制搜索空间,使得取样过程更具有灵活性。从本质上看,DeepWalk和node2vec算法都是属于基于节点位置信息的网络表示学习方法,通过自然语言处理模型得到节点的上下文语境信息,从而学习节点的向量表示;局限在于,此二者的目标函数并未说明保存网络何种属性。以LINE[3] 和SDNE[4] 为代表的融合网络结构信息的网络表示学习方法,则明确地提出了一个保存网络结构的目标优化函数。其中,LINE模型提出了节点的两种相似性,一种是一阶相似性,代表节点之间直接链接的关系;另外一种是根据共同邻居的结构定义,引入了二阶相似性来保存网络图的全局结构。相较于LINE中使用的浅层模型,SDNE模型引入了深层模型,设计了一个半监督的架构,从而获取到高度非线性的网络结构,并且解决了网络的稀疏性问题。这些方法在社交网络、语言网络和引文网络等复杂网络上的成功应用,对科研合作预测和推荐研究有着重大的启示意义。2.2 链接预测
Liben-Nowell和Kleinberg最早提出链接预测问题,他们使用了相似性度量的方法对合著网络进行链接预
测[5] 。现有的链接预测方法可分为两类,一类是基于节点相似度,另一类是基于学习的方法。基于节点相似度的方法通过计算未发生链接的节点对之间的相似度,给这些节点对评分,分数越高说明未来发生链接的概率越高,按照分数降序排列,排名较前的节点对未来最可能发生链接。这类算法包括Common Neighbors(CN)[6] 、Admic/Adar(AA)[7] 、Jaccard Coefficient(Jaccard)[8] 和Preferential Attachment(PA)[9] 等基于邻居结点的算法,以及Shortest Path(SP)[10] 、Katz、FriendLink[11] 、Random Walk with Restart(RWR)[12] 等基于路径的算法。基于学习的方法相当于二分类任务,可以通过分类器和概率模型等机器学习方法实现。这类方法把未发生链接的节点对当作一个实例,实例包括特征和标签,特征包括相似度特征和社交网络中的特征,如属性的文本信息和领域知识。输出结果中,可能存在链接的节点对标签为正,否则为负。近年来,随着网络表示学习的兴起,链接预测的研究也进入新的阶段。基于相似度的研究主要用学习到的节点表示为节点和边构建特征向量表示,一般使用一对节点表示的内积或余弦相似度来计算测试数据中节点对的得分,所得分值用于预测网络中丢失的边,或者未来可能会出现的边。若基于机器学习的方法,则输入的特征为学习到的顶点表示。SDNE和node2vec中进行的链接预测实验都证明,相较于传统的Common Neighbor等链接预测方法,基于网络表示学习的链接预测算法的性能更好。
2.3 科研合作推荐
因链接预测的良好性能,国内外学者逐渐将其结合到科研合作网络推荐方法中。现有的科研合作推荐研究主要针对知识创造主体间的合作关系构建合作网络,其中,合著论文为其基本表现形式。在合著网络中,节点代表作者,边代表作者间的合作关系,合著网络中的科研合作推荐就是对尚未产生联系的节点之间未来产生链接的可能性进行预测。Yan
等[13] 较早地将链接预测方法应用到科研合作推荐之中, 将CN算法、AA算法、Jaccard算法、PA算法和Katz算法等应用到图书馆学情报学领域的科研合作推荐之中。刘萍等[14] 运用社会网络理论,在社区划分的基础上,构建基于LDA的作者兴趣模型,然后对作者的相关文献进行分析,实现科研合作推荐的目的。吕伟民等[15] 则尝试运用极端随机树机器学习算法训练分类,并用遍历算法求取分类结果的最优权重值,选取TOP准确度的预测作为合作推荐结果。余传明等[16] 则提出一种新的融合基于邻居节点和基于路径的网络特征的科研合作推荐模型,并从个人、机构、区域三个层面进行实证研究。张金柱等[17] 则基于深度学习的网络表示学习,并结合向量相似度指标计算研究者间的语义相似度,实现科研合作预测和推荐。上述研究在多个领域的科研合作中取得了一定成果,但尚未将网络表示学习系统地应用于改进科研合作推荐。3 问题定义与研究方法
3.1 问题定义
3.1.1 金融领域科研合作推荐
金融领域科研合作推荐的定义为:给定一个现有的科研合作网络
3.1.2 科研合作网络
科研合作网络可被定义为图
本文所选取的四种基线方法中,DeepWalk仅适用于不加权网络,其他三种模型均可用于加权和不加权网络。为了更好地对比基线模型和融合模型在同一类网络图上的效果,本文所使用的科研合作网络为不加权的无向网络。
3.1.3 网络表示
给定网络图
3.1.4 链接预测
给定已观测到的边,即图
因此链接预测问题的定义为:给定网络图
3.2 研究方法
本文提出的金融领域科研合作推荐模型可分为三个部分(如图1所示)。第一部分是网络顶点的特征学习,参见第3.2.1节。在该部分中,将把一个科研合作网络分别输入到两类网络表示学习模型中,从模型中输出得到顶点表示;按照一定的比例把两个向量x和y融合成新的向量z,作为顶点的表示。第二部分是边的表示学习,参见第3.2.2节,该部分选取了一种二元运算对顶点的网络表示进行计算,得到节点对的网络表示。第三部分是利用机器学习算法进行链接预测,参见第3.2.3节。在该部分中,将把第二部分获得的节点对的向量表示特征,输入到逻辑分类器中并进行训练,输出的标签表示该节点对在未来的一段时间内是否存在链接关系。
3.2.1 顶点的表示学习模块
通过本文第2.1节中对网络表示学习的分析,可以将几种经典的深度学习的网络表示方法分为两类,一类是基于节点信息的模型,包括DeepWalk和node2vec算法;另一类是融合了网络结构的模型,包括LINE和SDNE算法。
基于节点信息的两种模型的核心可分为随机游走生成器和网络表示更新两个部分。首先采用一定的取样策略,将网络图转化为节点序列;然后将节点序列输入到Skip-Gram语言模型中,在该模型中,最大化目标节点和邻居节点在序列窗口中的共现概率,使用随机梯度下降进行节点表示的更新。
与DeepWalk、node2vec相同,融合网络结构的两种模型的核心部分也在于如何利用相邻节点信息定义节点的上下文信息,不同之处在于,DeepWalk、node2vec是利用随机游走来定义邻域,而LINE和SDNE两个模型是基于共同邻居的信息表示上下文信息的概率分布。这两种模型都定义了两种相似性:对任意一对节点对
本文采用加权平均优化法,针对两种类型的网络表示学习模型输出的节点的潜在表示,构造集成式模型(Integrated Model of Local and Global Information,LGIM),表示为
式中,
3.2.2 边的表示学习模块
通过集成式模型可以得到网络节点丰富的向量表示,既包括随机游走捕捉到的邻域信息,又包括共同邻居定义的邻居结构信息。但是,在链接预测任务中,往往涉及节点对的预测,而不是单一节点的预测。例如,本文研究的科研合作预测目标就是预测两个作者未来可能发生合作的概率,而不是作者本身。
给定两个节点
3.2.3 链接预测模块
链接预测实际上是一个二分类问题。机器学习中分类算法有很多,常用的分类器包括逻辑回归模型,决策树和支持向量机。由于在实际的科研合作推荐任务中,推荐模型不仅需要对学者推荐目标对象,有时还需要根据其可能感兴趣的程度,对所推荐对象进行排序。所以,评估推荐模型时一般会同时考虑推荐的准确性和排序能力。因此,链接预测的方法应该对观测样本进行概率值输出,才可以对推荐结果进行排序。决策树算法的局限就在于无法输出观测样本的概率值,只能给出直接的分类结果,不适用于本文的推荐模型。虽然支持向量机可以满足推荐结果的排序要求,但其对大规模的训练样本难以实施,因为算法在通过二次规划来求解支持向量时将涉及m阶矩阵计算(m为样本的个数),当m的值很大时,该矩阵的存储和计算将耗费大量的内存和运算时间。科研合作网络一般规模较大,且结构复杂,顶点和边的数目极大,采用SVM进行链接预测可能效率较低。通过综合比对,并结合实验采用的数据,模型使用逻辑回归方法进行链接预测,不仅便于对推荐结果进行排序,而且简单高效。
逻辑回归属于有监督学习算法,在有监督学习中,每个实例都是由特征向量和对应输出标签组成。在本文研究的链接预测问题中,输入数据是节点对的一系列特征,即通过网络表示方法学习到的低维顶点表示,输出标签表示这对节点在未来的一段时间内是否存在链接关系。
4 实 验
4.1 数据集
本文采用的数据集来自中国知网期刊数据库金融类目CSSCI(Chinese Social Sciences Citation Index)选项,共包含2000—2014年的68905篇论文,并据此从个人层面构建科研合作网络。在该科研合作网络中,节点代表论文的作者,边代表作者之间的合作关系。假设有一篇论文发表于2014年,在该论文中有三个合著者author1、author2、author3,则节点author1和author2,author2和author3,author1和author3之间各存在一条边,代表三个作者的合著关系。为更真实地模拟链接预测,数据集将按照时间序列分为两部分,例如,将2000—2013年的数据作为训练集,2014年的数据作为测试集。实验所使用的数据集如表2所示。总集合中的7096条合作链接仅代表存在合作关系的作者对,不包括重复的链接情况。由于本文选取的四种基线方法中,DeepWalk模型仅适用于无加权网络,其他三种模型均可用于加权和不加权的网络,为了更好地对比基线模型和融合模型在同一类网络上的效果,在将合著数据处理为科研合作网络时,仅保留作者之间的合作关系,而没有将作者的合作次数作为边的权重,即本文所使用的科研合作网络是一个无加权网络。
表2 实验数据集
数据集 起止年份 作者数 合作链接数 总集合 2000—2014年 4123 7096 训练集 2000—2009年 4049 6119 2000—2010年 3912 6026 2000—2011年 3725 5326 2000—2012年 3459 4652 2000—2013年 3140 3948 测试集 2010—2014年 3003 3809 2011—2014年 2703 3136 2012—2014年 2289 2416 2013—2014年 1761 1623 2014年 1080 864 实际上,CSSCI期刊是不断变化的,随着一部分新刊物纳入CSSCI收录范围,会导致新的合作关系加入到科研合作网络当中,而一部分旧刊物被剔除,会导致部分合作关系缺失,从而使科研合作网络的局部结构发生一定变化。这种变化对科研合作推荐结果会产生一定的影响。当网络中的原节点之间丢失原有的链接关系时,网络结构发生改变,DeepWalk和node2vec算法都需要重新执行随机游走策略,使用新的随机游走序列进行网络表示学习,LINE和SDNE算法则需要用更新的共同邻居信息来重新执行学习过程,节点的网络表示进而更新。而当网络中的原节点之间产生新的合作关系或新节点与原节点产生合作关系时,本文所选取的算法都体现出一定的自适应性。DeepWalk和node2vec两种算法都可以实现在训练结果的基础上,加入新的随机游走序列,迭代更新学习模型,而不需要重新执行一次学习过程,进而更新局部结构中原节点的表示,同时得到新节点的表示。LINE和SDNE则需要通过更新共同邻居的信息更新原节点的网络表示。而针对新节点的加入,LINE算法提出一个优化目标函数,在不改变原始网络节点向量的基础上,根据新节点的链接关系对新节点进行优化,得到新节点的向量表示;SDNE算法则将新节点的邻接向量输入到其深层模型中,根据已经训练好的模型参数,计算出新节点的向量表示。综上所述,四种模型在原有网络节点的基础上丢失或增加链接,局部网络的节点向量都会改变。而当新节点加入时,基于节点位置信息的两种模型可以迭代地更新学习模型,新节点所在的局部网络中的节点向量会改变;融合网络全局结构的两种模型则在不更新原节点的基础上计算出新节点的向量。因此,根据更新过的原节点向量计算出的边的向量也会发生相应的变化,输入逻辑回归模型的一系列特征值发生变化,将会对推荐结果产生一定的影响。本文仅针对特定时间点下的网络拓扑结构,进行科研合作推荐。
4.2 基线方法
通过综合比对,本文采取以下四种网络学习表示方法作为基线方法。参数设置如表3所示。
表3 基线方法参数设置
方法 参数 DeepWalk 网络表示维度为256;每个节点选择80个随机游走序列;每个随机游走序列长度等于10;Skipgram模型中的滑动窗口大小设置为10 node2vec 网络表示维度为256;通过网格搜索,将取样步骤中返回参数p设置为0.25,输入-输出参数q设置为0.5;为每个节点选择80个随机游走序列;每个随机游走序列长度等于10;Skipgram模型中的滑动窗口大小设置为10 LINE 一阶与二阶网络表示的维度分别为128,级联后的顶点向量维度为256;学习率为0.025;负采样数设为5;批处理大小为128;设置训练样本数为30 0000 SDNE 通过网格搜索,将目标优化函数中,一阶相似度损失项系数α设置为0.6,二阶相似度损失项系数γ设置为0.4,由于采用了负采样,2正则项的系数设置为0;β学习率设置为0.025;维度设置为256;负采样率设置为0.5;批处理大小设置为32;受限玻尔兹曼机的批处理大小设为64 (1)DeepWal
k[1] :该方法利用随机游走和skip-gram模型来生成网络表示。(2)node2ve
c[2] :该算法在DeepWalk基础上,改变随机游走算法,融合深度优先和广度优先的算法,设计出一种有偏的随机游走,使得节点序列数据与DeepWalk有一定差异。(3)LIN
E[3] :算法定义了损失函数来分别保存一阶相似性和二阶相似性,优化损失函数后,算法将一阶和二阶表示级联起来。(4)SDN
E[4] :算法使用深层神经网络对节点表示间的非线性进行建模,整个模型可以被分为两个部分,一个是由Laplace矩阵监督的建模一阶相似度的模块,另一个是由无监督的深层自编码器对二阶相似度关系进行建模。最终SDNE算法将深层自编码器的中间层作为节点的网络表示。4.3 科研合作推荐模型评价指标
在链接预测实验中,验证预测准确率的常用指标是AUC(Area Under Receiver Operating Characteristic Curve)和MAP(Mean Average Precision)。MAP值的计算公式为
式中,u是目标节点;n是网络图中节点的数量;AP(u)表示向目标节点推荐节点的平均准确率。MAP不仅可以说明推荐算法的准确率,还能揭示推荐算法的排序能力,因此使用MAP可以更好地对推荐算法的整体性能进行评估。
另外,本文还使用AUC作为评估标准。假设两个节点之间当前没有链接,但是将来会产生链接,这类链接被称为“缺失链接”;假设两个节点现在不存在链接,将来也不会产生链接,这类链接被称为“错误链接”。AUC实际上就是比较缺失链接的得分和错误链接的得分。
本文中的实验通过引入Python机器学习库scikit-learn计算AUC值与每个目标节点的AP值,进而计算出MAP值。
4.4 基础实验结果与分析
4.4.1 金融领域科研合作链接预测
在链接预测任务中,往往是给定一个网络,移除一定比例的边,然后预测这些遗失的边。而在本文中,为了更好地模拟链接预测的实际应用情况,每组实验都按照一定的年份移除。例如,移除2014年的数据,并确保剩余部分的网络是连接图;使用2000—2013年的数据训练模型,并用模型预测2014年的数据;为了生成负边,随机取样了相同数量的不相连接的节点对。
将2000—2013年的数据作为训练集,2014年的数据作为测试集,分别测试两类模型的效果。图2a和图2b分别显示了两类模型在2000—2013年的数据上训练的结果。由图2可以看出,node2vec算法在AUC上的表现略高于DeepWalk算法,而在MAP的表现上,两种模型效果接近;LINE算法在AUC上的表现明显优于SDNE算法,但在MAP表现上,SDNE算法却优于LINE算法,这在一定程度上说明不同模型学习的特征侧重点不同可能会导致其预测结果的准确率和排名质量不同,基于不同类型的模型进行融合可能会同时提高预测准确率和排名质量。因此,本文对两类模型进行排列组合,按照AUC值达到最大时的融合比例融合两类模型输出的向量,再将新的顶点向量进行二元运算得到边向量,将其作为边的特征,进行逻辑回归模型的训练,并使用训练得到的模型在测试集上检验。表4显示了四种基线方法和融合模型的效果对比。
表4 模型效果对比
评价指标 模型 训练集规模 2000—2009 2000—2010 2000—2011 2000—2012 2000—2013 AUC DeepWalk 0.6041 0.6288 0.6716 0.6954 0.7622 node2vec 0.5979 0.6318 0.6564 0.7095 0.7737 LINE 0.5905 0.6196 0.6521 0.7034 0.7656 SDNE 0.5801 0.6064 0.6155 0.6594 0.7297 LGIM DeepWalk+LINE 0.6044 0.6288 0.6721 0.7044 0.7797 DeepWalk+SDNE 0.6041 0.6288 0.6730 0.6968 0.7704 node2vec+LINE 0.5985 0.6321 0.6576 0.7119 0.7740 node2vec+SDNE 0.5988 0.6318 0.6576 0.7096 0.7764 MAP DeepWalk 0.7194 0.6552 0.5727 0.4456 0.2771 node2vec 0.6969 0.6384 0.5500 0.4323 0.2737 LINE 0.7025 0.6394 0.5528 0.4306 0.2676 SDNE 0.7026 0.6388 0.5531 0.4349 0.2850 LGIM DeepWalk+LINE 0.7035 0.6552 0.5666 0.4288 0.2702 DeepWalk+SDNE 0.7194 0.6552 0.5694 0.4404 0.2771 node2vec+LINE 0.6970 0.6384 0.5500 0.4279 0.2737 node2vec+SDNE 0.6986 0.6384 0.5548 0.4320 0.2746 由表4可以看出,在不同规模的数据集上,融合模型在AUC值上都获得最优效果,其中,LINE与DeepWalk的融合模型、LINE与node2vec的融合效果最好;当使用2000—2013年的数据进行训练时,LINE与DeepWalk的融合模型的AUC值比其基线模型提高2.3%。这说明了将随机游走和共同邻居所包含的网络信息融合在一起进行链接预测,能够提高预测的准确率。采用使AUC达到最大值的最优融合比例时,融合模型的MAP值并没有显著提升,其基本模型仍保持较高的MAP值;以基于DeepWalk和LINE的融合模型为例,不同规模的数据集上,融合模型的MAP值虽然高于LINE模型的MAP值,但却没有超过DeepWalk的MAP值,说明加权平均优化的融合方式虽然可以显著提高模型的预测准确率,却无法同时提高推荐的排名质量。
以基于node2vec和LINE的融合模型为例进行科研合作推荐,得到的推荐排名前10位的合著关系如表5所示。根据本文第4.5节进行的扩展实验,设置最优融合参数和维度,即将node2vec模型的表示融合参数设置为0.6,LINE模型的表示融合参数设置为0.4,维度设置为256,使用训练得到的逻辑回归模型进行链接预测。
表5 集成模型预测出的排名前10位的合著关系
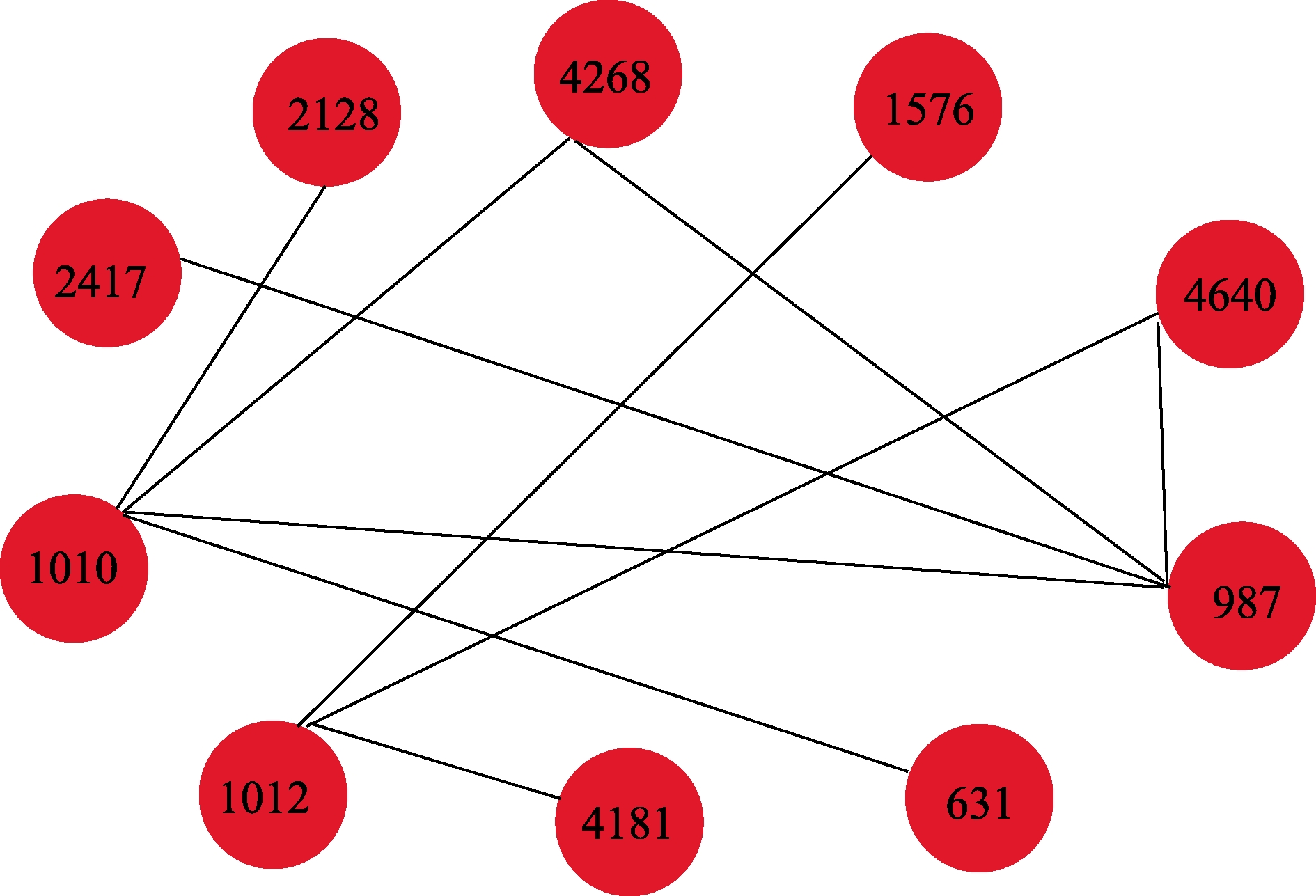
推荐排名 节点编号 姓名 机构编号 机构名称 节点编号 姓名 机构编号 机构名称 1 4640 贾海涛 5 上海财经大学金融学院 1010 何静 12 北京大学经济学院 2 1355 华民 10 武汉大学经济与管理学院 1650 宋泓 9 北京大学光华管理学院 3 4640 贾海涛 5 上海财经大学金融学院 4268 财政部财政科学研究所课题组 5 上海财经大学金融学院 4 3798 傅雄广 5 上海财经大学金融学院 720 林毅夫 15 浙江大学经济学院 5 784 孙英隽 14 天津大学管理学院 3144 师文明 6 中国人民大学经济学院 6 4415 王俊秋 5 上海财经大学金融学院 4795 陈震 5 上海财经大学金融学院 7 2898 马涛 7 复旦大学经济学院 2132 柴瑜 8 中国人民大学财政金融学院 8 1010 何静 12 北京大学经济学院 2417 史美景 7 复旦大学经济学院 9 4756 陈建新 5 上海财经大学金融学院 4432 王小燕 5 上海财经大学金融学院 10 987 邱长溶 13 西南财经大学金融学院 1012 余文建 12 北京大学经济学院 以推荐结果排名第一位的节点对为例,绘制出两个节点的邻居结构图,如图3所示,发现两个节点所在的邻居结构非常相似。例如,两个节点之间都有一个共同邻居,即编号为987的节点,根据二阶相似性的定义,可以得出两个节点的邻居结构相似,说明融合了网络结构特征的推荐模型倾向于向科研工作者推荐与其有共同合著者的作者。
通过对科研工作者所在的机构进行比对分析,发现推荐的作者对许多位于相同的机构内,例如,推荐排名第3位、第6位和第9位均就职于上海财经大学金融学院。从微观上看,这些节点在低维空间中分布较近,形成聚集状,编号4640、1010和4268的节点均分布相近,节点之间的距离不超过2个步长。结果充分说明融合了节点的位置信息的推荐模型可能会向科研工作者推荐与其处于同一集群内的其他作者。
值得一提的是,即使使用同样的数据集,推荐结果排名前10位的合著关系与余传明
等[16] 提出的PHM模型得到的部分推荐结果有较大差异。不同算法可能会产生不同的推荐结果的原因可能是同一个领域的学者会有各自更感兴趣的细分领域,推荐结果仅表明了他们之间潜在的合作的倾向。另一方面,由于不同的算法会捕捉到不同方面的网络特征,推荐结果也可能产生一定的差异。4.4.2 其他研究领域的科研合作链接预测
除金融领域外,本文还从斯坦福大学网络分析平台上选取了一个大型网络数据CA-GrOc,该数据集包含1993年1月—2003年4月,收录在arXiv的广义相对论和量子宇宙论条目下的14496篇文章,其中的论文合著者有5242人,据此构建出物理研究领域的合著网络。将合著网络按一定比例分为训练集与测试集,在训练集上训练4个基线模型,并分别融合两类模型生成的网络节点表示得到四组新的节点表示;使用融合表示进行链接预测,并将AUC作为模型的评估指标,所得评估结果如表6所示。从表6的实验结果可以看出,与在金融领域的实验结果一致,在物理研究领域数据上,利用加权优化后的网络表示进行链接预测,比使用单一模型得到的表示效果更好,说明集成模型可以推广到更多领域的科研合作推荐研究。
表6 模型在CA-GrQc数据集上的评估结果
模型 训练集规模 10% 30% 50% 70% 90% DeepWalk 0.7030 0.8315 0.8917 0.9233 0.9476 node2vec 0.7043 0.8411 0.9011 0.9311 0.9546 LINE 0.7032 0.8388 0.8971 0.9264 0.9503 SDNE 0.7028 0.8378 0.8934 0.9203 0.9409 LGIM DeepWalk+LINE 0.7038 0.8404 0.9002 0.9301 0.9540 DeepWalk+SDNE 0.7039 0.8407 0.9001 0.9298 0.9540 node2vec+LINE 0.7043 0.8412 0.9012 0.9312 0.9546 node2vec+SDNE 0.7051 0.8423 0.9032 0.9325 0.9567 4.5 扩展实验结果与分析
4.5.1 维度对模型效果的影响
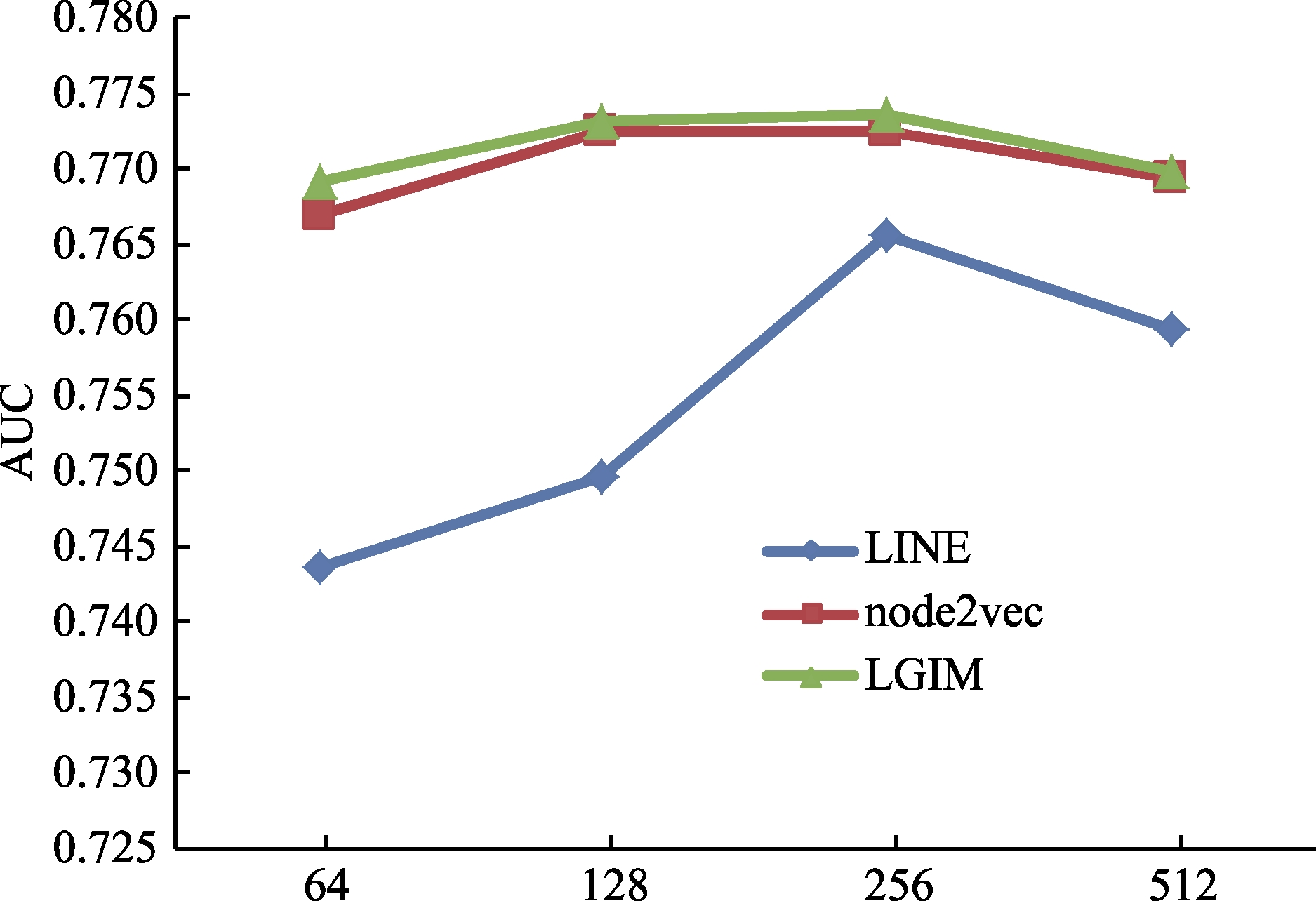
基于节点位置信息和融合网络结构的网络学习表示模型都涉及许多参数。其中,DeepWalk和node2vec共同的参数包括表示的维度,滑动窗口长度,随机游走序列长度,为每个节点选取的随机游走序列个数等,另外,node2vec中还涉及两个控制取样范围的参数;而LINE和SDNE相同的参数则包括表示的维度、学习率等,SDNE还涉及了一阶和二阶相似度损失函数的系数项。综合看来,两类模型中共同的参数只有网络表示的维度d,因此,本节将探究融合模型的维度选取对于链接预测的效果影响。
图4显示了不同维度下集成式模型的效果。由图中可以看出,一开始,随着维度的增大,模型效果提高,这是因为向量的维度越高,意味着更多有用的网络结构信息被编码进向量中。当维度达到256后,模型效果达到最高值,之后随着维度增大而降低,产生这种现象的可能原因包括两个方面:一方面,高维度会引入噪声,从而对模型效果产生影响;另一方面,在逻辑分类器中,网络表示的维度即为输入特征空间的向量维数,过高的特征维数会混淆学习算法,并且导致分类器的过拟合问题,即分类器过于复杂导致其性能下降。从曲线的走势上看,集成模型在维度上的变化基本与单一模型保持一致。实验表明,选择合适的网络表示的空间维度对模型的性能有重要意义。
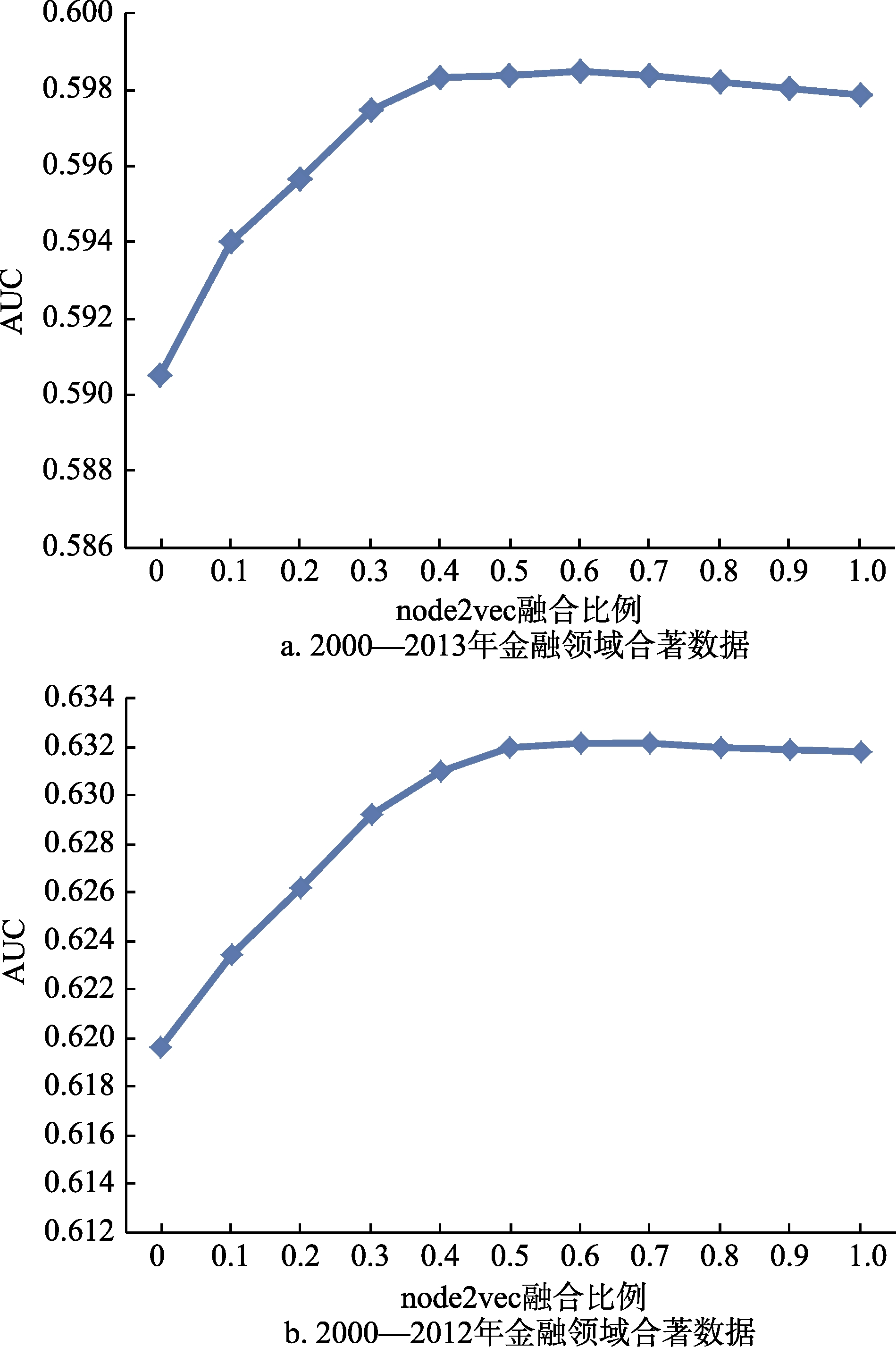
4.5.2 融合参数对模型效果的影响
对集成模型中的融合参数进行调整,所得结果如图5所示。图中以node2vec模型的融合比例
实验结果说明了以下两个结论:①将不同类型的网络表示学习模型集成到一起进行科研合作推荐能够获得更好的效果,因为融合后的网络表示能编码各种不同的网络信息;②在一个集成模型中,对其效果起决定性作用的是效果较好的单一模型,在一定范围内该模型的向量的融合比例越大,集成模型的效果越好。这可能是因为较优模型学习到的网络表示更能体现出顶点在低维空间上的特征,其表示在融合的表示中所占比例越大,输入到逻辑回归分类器中的低维实值向量就越符合顶点在实际网络中的特征,分类器的分类效果越好。
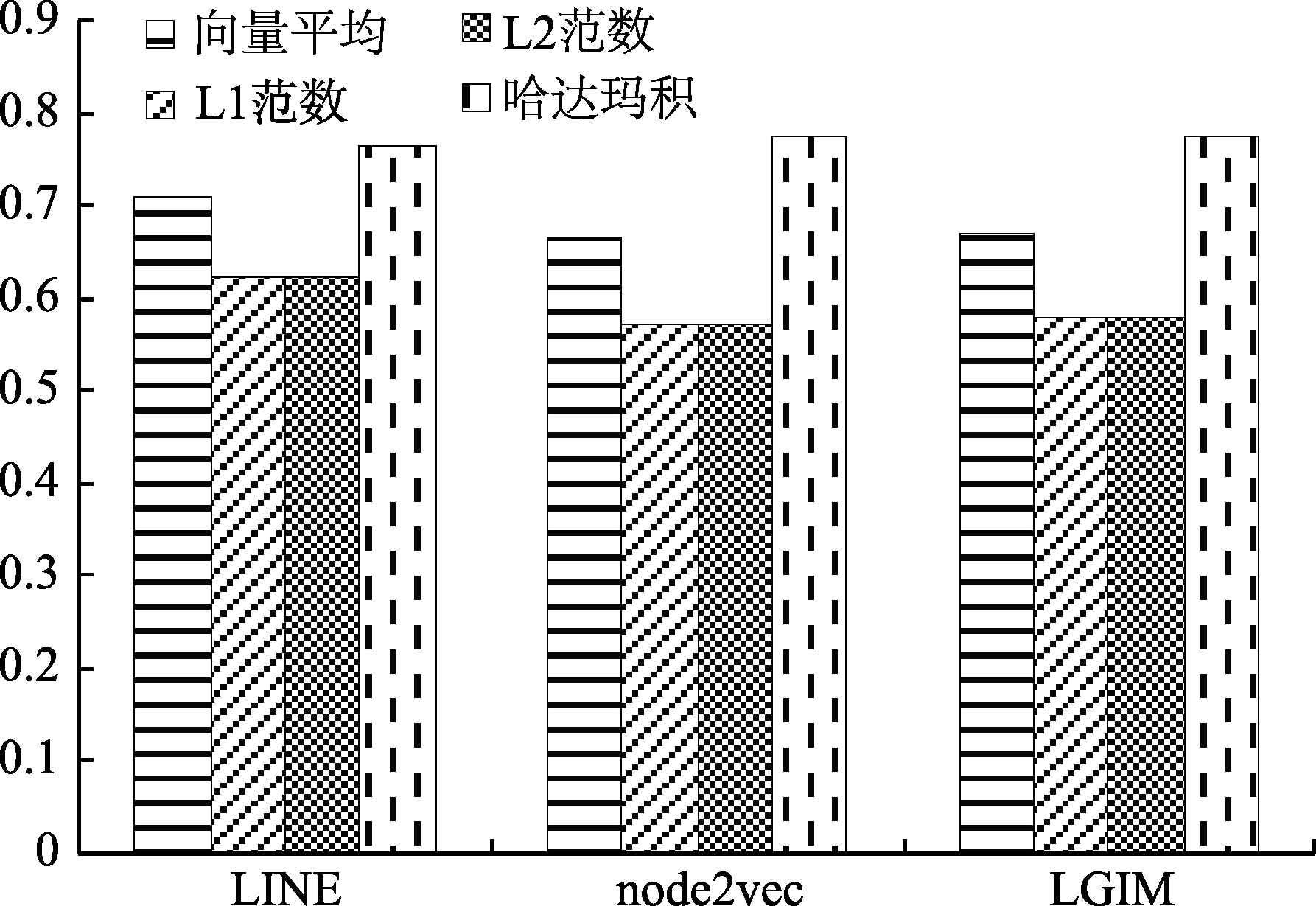
4.5.3 二元运算类型对模型效果的影响
如何根据顶点向量得到边的向量是模型中一个重要的问题。为了探究二元运算类型的选取对于模型效果的影响,本文选取了哈达玛积、向量平均、L1范数和L2范数进行评估。图6显示,在LINE算法、node2vec算法以及集成模型中,使用哈达玛积作为顶点之间的二元运算的效果最为稳定,明显比其他三种运算效果好,向量平均效果次之。因为从几何意义上看,向量平均在向量空间中代表两个顶点之间的中点,若将中点的表示作为边的表示,可能无法代表边的特征。使用L1范数和L2范数效果最差,并且两种运算的效果几乎没有差别。采用范数运算时,得到的值代表两个顶点之间的距离,若将这个值作为特征值输入到分类器中,则无法全面地表示出边的特征,分类效果较差。
4.5.4 模型融合方法对模型效果的影响
采用模型融合技术一般可以提高机器学习任务的准确率,常见的模型融合方法包括加权平均、bagging以及boosting等。bagging方法在训练集中进行子抽样,组成每个基础模型所需要的子训练集,根据每一个模型对预测结果进行投票,每一个模型投票的权重相同。对所有基础模型的预测结果进行综合产生最后的预测结果。boosting方法实现原理是迭代地训练基线模型,每次根据上一个迭代中预测错误的情况修改训练样本的权重,其本质是集合了多个决策树,每棵树是顺序生成,依赖于前一棵树。为了探究模型融合方法对模型效果的影响,本文选取了加权平均、bagging和boosting方法(以Adaboost为boosting方法的代表)进行评估。由于本文基础实验中选择的分类器为逻辑回归模型(LR),为了更好地对比融合模型的效果,bagging和boosting方法中的弱分类学习器仍采用LR模型,其余框架参数均采用sklearn封装算法的默认参数,实验结果如表7所示。
表7 融合方法对模型效果的影响
融合方法 DeepWalk+LINE DeepWalk+SDNE node2vec+LINE node2vec+SDNE weighted average 0.7797 0.7704 0.7740 0.7764 bagging 0.7819 0.7709 0.7953 0.7803 boosting 0.7353 0.7511 0.7135 0.7433 由表7可以看出,bagging方法在三种融合方式中效果最好,加权平均与boosting方法次之。因为boosting方法对于噪音数据和异常数据较为敏感,因此每次在迭代时会赋予噪声点较大的权重,使得后面的模型更加关注被错误分类的样本,出现过拟合现象。在机器学习的应用上,过拟合非常普遍,其根本问题是训练数据量不足以支撑复杂的模型,导致模型学习到数据集上的噪音,bagging方法和加权平均法可以减少对噪音点的考虑,提高决策边界的泛化能力,即使一些模型的错误判断也不会影响最后的结果,从而避免过拟合现象。
4.6 讨 论
本文以金融领域的科研合作网络为实证研究对象,借助基于深度学习的网络表示学习方法,对科研合作网络进行推荐模型研究。
从推荐结果来看,模型由于结合了节点的位置信息和网络的整体结构,得到的推荐结果既在空间中位置相近,同时邻居结构也相似,说明模型倾向于推荐在合著网络中处于同一集群的作者对以及合作关系结构相似的作者对。研究结果一方面表明,科研工作者一般会寻求同一机构内的合作,并且通过共同的合作对象来寻找未来有兴趣开展合作的其他学者,这与余传明
等[16] 在个人层面上进行科研合作推荐研究的结果一致。研究同时表明了合作关系结构相似的科研工作者,即曾与他们发生合作关系的作者有重合,那么这两名作者可能会有共同感兴趣的主题,进而产生合作。这与王玙等[18] 基于社交圈的社交好友推荐研究所得的结果一致,后者的研究表明社交圈重叠越多,用户越有可能成为朋友。合著网络也属于一种社交网络,合作圈重叠越多,科研工作者越有可能发生合作。从模型的影响因素上来看,选择合适的网络表示的维度、表示的融合比例以及计算边的表示采用的二元运算,对模型的推荐效果至关重要。针对本文所用的金融研究领域的数据,网络表示的维度控制为256时,模型达到最优效果,并且该最优维度与单一模型的最优维度保持一致;当效果较好的模型的融合比例控制在0.6附近时,集成模型的表现最好;当选取的二元运算可以全面地表示边在多个维度上的特征时,模型效果最好;当选择bagging和加权平均的融合方法时,模型效果较好。
从模型的应用范围上看,由于不同研究领域的合作网络的拓扑结构呈现较高的一致性,与研究领域并无实质关联,因此,本文提出的推荐模型可以拓展到金融领域以外的更多学科。为证明模型的可推广性,本文选取了物理研究领域的论文合著数据进行验证。其实验结果与金融研究领域的结果一致,通过加权优化得到的网络表示融合了顶点的多种特征信息,因此比单一模型得到的网络表示在链接预测任务中效果更好。然而,最优融合比例的选取与数据集有关,本文选取的金融领域数据中,node2vec模型的融合比例在0.6附近时,集成模型效果最好;在物理领域数据中,node2vec的最优融合比例在0.7~0.9,说明最优融合比例与科研网络的结构有关,适用于特定的科研合作领域。
5 结 语
本文通过分析现有的四种基于深度学习的网络表示学习模型,将其分为两种类型,一种是基于节点位置信息的模型,其网络信息的保存通过随机游走实现;另一种是融合网络结构的模型,其网络信息的保存通过对节点的共同邻居实现。本文通过比较两类模型的效果,选择效果相对较好的模型作为代表,构建一个集成模型,将模型输出的网络表示按照一定的比例级联起来,作为新的顶点表示;利用二元运算,通过顶点表示得到边的表示;最终将边的表示作为特征,训练逻辑回归模型。实验结果表明,集成模型的效果相较于单个模型,在AUC和MAP指标上的表现都更好。本文的不足之处在于,所采用的集成方式还有待深化。未来将从算法本身入手,考虑更深层次的模型融合,并且尝试融合更多类型的网络表示学习模型,以此提高科研合作推荐的效果。
参考文献
- 1
Perozzi B, Al-Rfou R, Skiena S. DeepWalk: Online learning of social representations[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2014: 701-710.
- 2
Grover A, Leskovec J. Node2vec: Scalable feature learning for networks[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2016: 855-864.
- 3
Tang J, Qu M, Wang M Z, et al. LINE: Large-scale information network embedding[C]// Proceedings of the 24th International Conference on World Wide Web. Switzerland: International World Wide Web Conferences Steering Committee, 2015: 1067-1077.
- 4
Wang D X, Cui P, Zhu W W. Structural deep network embedding[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2016: 1225-1234.
- 5
Liben-Nowell D, Kleinberg J. The link-prediction problem for social networks[J]. Journal of the American Society for Information Science and Technology, 2007, 58(7): 1019-1031.
- 6
Chen J, Geyer W, Dugan C, et al. Make new friends, but keep the old: Recommending people on social networking sites[C]// Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. New York: ACM Press, 2009: 201-210.
- 7
Adamic L, Adar E. How to search a social network[J]. Social Networks, 2005, 27(3): 187-203.
- 8
Tan P N, Steinbach M, Kumar V. Introduction to data mining[M]. Boston: Addison Wesley, 2005: 65-84.
- 9
Costa L F, Rodrigues F A, Travieso G, et al. Characterization of complex networks: A survey of measurements[J]. Advances in Physics, 2007, 56(1): 167-242.
- 10
Katz L. A new status index derived from scientometric analysis[J]. Psychometrika, 1953, 18(1): 39-43.
- 11
Papadimitriou A, Symeonidis P, Manolopoulos Y. Fast and accurate link prediction in social networking systems[J]. Journal of Systems and Software, 2012, 8(5): 2119-2132.
- 12
Pan J, Yang H, Faloutsos C, et al. Automatic multimedia cross-modal correlation discovery[C]// Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Ming. New York: ACM Press, 2004: 653-658.
- 13
Yan E, Guns R. Predicting and recommending collaborations: An author-, institution-, and country-level analysis[J]. Journal of Informetrics, 2014, 8(2): 295-309.
- 14
刘萍, 郑凯伦, 邹德安. 基于LDA模型的科研合作推荐研究[J]. 情报理论与实践, 2015, 38(9): 79-85.
- 15
吕伟民, 王小梅, 韩涛. 结合链路预测和ET机器学习的科研合作推荐方法研究[J]. 数据分析与知识发现, 2017, 1(4): 38-45.
- 16
余传明, 龚雨田, 赵晓莉, 等. 基于多特征融合的金融领域科研合作推荐研究[J]. 数据分析与知识发现, 2017, 1(8): 39-47.
- 17
张金柱, 于文倩, 刘菁婕, 等. 基于网络表示学习的科研合作预测研究[J]. 情报学报, 2018, 37(2): 132-139.
- 18
王玙, 高琳. 基于社交圈的在线社交网络朋友推荐算法[J]. 计算机学报, 2014, 37(4): 801-808.
- 1
摘要
为了促进同一学术领域的科研合作团队的组建,提高科研效率,本文基于网络表示学习对多个领域科研合作推荐模型进行研究。将基于节点位置的网络表示学习模型与融合网络结构的网络表示学习模型进行集成,得到新的顶点表示,对两个顶点的表示进行选择二元运算得到边的表示。模型将网络表示学习与机器学习相结合,将节点对的表示作为特征训练逻辑分类器,分类器得到的标签即为链接预测结果。通过对金融和物理领域的论文合作数据进行分析,构建科研合作网络。实验证明,提出的集成模型在AUC值上的表现比单一模型更好,效果最高提升了2.3%;在训练集规模较小的情况下,AUC值仍能达到60%。实验结果表明,该科研合作推荐模型具有可行性,对同一学术领域的科研合作团队的组建能够起到有效辅助作用。
Abstract
This paper researched a scientific collaboration recommendation model in the financial field based on network embedding to promote the formation of a research team in the same research field and improve the efficiency of research. The model integrates two types of network embedding models; one of these is based on the location of vertices, while the other is integrated with network structure. A binary operator for the representation of two vertices was employed to generate a representation of edge. Combining network embedding and machine learning, the model trained a logic regression classifier with the representation of edges as features, and the labels acquired from the classifier were the results of link prediction. By analyzing papers in the financial and physical research fields, several scientific collaboration networks were constructed. The experiments confirm that the proposed integrated model has achieved better performance than single models on the value of AUC, with the efficiency improved by up to 2%; even on a small training set, the value of AUC still reached 60%. The proposed model proved to be feasible in scientific collaboration recommendation, which will effectively promote the formation of a research team in the same field.