- 摘要Abstract

- 关键词Keywords
-
1 引 言
-
2 相关研究
-
3 基于文献知识抽取构建专题知识库的技术路线
-
1)用户需求调研与知识库范围界定
-
2)专题知识模型构建
-
3)文献收集与获取
-
4)文献知识抽取
-
5)开发系统功能
-
6)专题知识服务
-
4 中药活血化瘀专题知识库建设
-
4.1 用户需求和建设目标
-
4.2 中药活血化瘀专题知识模型构建
-
4.3 文献检索和获取
-
4.4 知识抽取
-
4.5 系统实现与原型系统
-
5 系统测试效果评估
-
1)能够快速获得预期研究问题的答案
-
2)为活血化瘀中医药领域研究提供大量有效的事实、知识和文献研究证据
-
3)能够直观地把握研究主题的知识结构和研究状况
-
6 结 语
- 参考文献
1 引 言
随着大数据时代信息激增,科研人员对高效获取和利用领域知识提出了更高的要求。文献是蕴涵科学发现与创新的重要媒介,某领域一段时期的文献代表了这一时期的研究现状和热点,从中可以获取到创新点、主要工作、实验方法、实验结果、性能指标等表征科研成果的关键知
识[1] 。当前科学数据还不能广泛地获取,存在严重的“数据鸿沟”[2] ,因此文献仍是目前科研人员获取领域知识和最新研究的主要途径。科研人员通过对大量文献内容的加工和解析,建立可用的数据集,推进研究并撰写文章发表。PubMed的论文正被不同研究目标的科研人员进行挖掘分析,如百万篇来源文章的图、表被用来挖掘和构建脑成像数据库[3] 。另有研究基于MEDLINE数据库中2000多万篇文章的摘要,发现了E-cadherin(一种细胞黏附分子)和帕金森症之间的某种间接关联[4] 。因此文献作为用户了解一个领域研究内容的有效途径,基于海量文献的数据分析,发掘文献中的知识及知识间隐藏的关联关系,已然成为大数据时代一种新的科研方式。面对庞大的文献量,科研人员目前面临的问题是如何从检索出的大量相关文献中快速找到自己需要的知识。由于在文本处理和数据分析方面欠缺技能经验,科研用户普遍在从文献中提取知识和数据再利用方面遇到困难,因此基于传统文献资源建设的数据库已无法满足科研人员对数据的强烈需求,如何挖掘文献背后的知识以满足用户个性化需求是至关重要
的[5] 。专题知识库是利用信息技术对某一特定主题或领域的知识进行有序化组织、展现和管理的知识应用系统,以其专题特色突出、资源建设标准化、灵活而个性化的服务、专业而深入的知识管理等优势,成为科研用户青睐的工具[6] 。本文提出了基于专题知识模型和文献信息抽取构建专题知识库的技术路线,并以中药活血化瘀领域为例详细阐述了专题知识库的构建过程和服务效果,以提供一种构建专题知识库的行之有效的思路和方案,帮助科研用户从海量文献中快速找到所需关键信息和精准知识。2 相关研究
专题知识库以其较为全面、有序地集成和涵盖了特定领域的重要信息,能够使用户便捷地得到专业而细化的知识,已在多个领域得到研究和应用。随着用户对专题知识库建设要求的日益提升,基于传统数据库构建的专题知识库已无法满足用户的需求,目前一些学者对专题知识库的设计与构建进行了深入研究,引入本体建模、数据挖掘、信息抽取等技术深度揭示领域知识,使专题知识库提供更高层次的知识服
务[7] 。按照专题知识库构建采用的核心技术,目前大致包括两类:(1)领域本体建模:由于本体强大的知识表示和推理机制,基于本体的知识库模型成为新一代知识管理系统的选
择[8] ,因此领域本体作为规范化描述和语义化组织学科领域核心知识的模型,越来越多地应用于专题知识库的建设。钱智勇[9] 以张謇研究专题知识库系统开发为例,采用分层设计思想开发基于本体的专题域知识库系统,实现了完整的本体知识获取、构建、存储和用户服务的过程。王昊等[10] 提出了本体驱动的知识管理系统模型,通过采集外部信息源的知识,构建与完善本体库,并基于自身的概念本体和本体实例库提供知识服务。由于该模型未包含相关领域的资源库,因此许鑫等[11] 在其基础上加入了领域资源标注模块,实现了知识体系、知识片段与领域资源的关联,并提出了更具体的基于本体的专题知识库构建流程。(2)基于模式匹配或规则算法的知识抽取:目前这类技术旨在研究如何在无需人工标注语料的情况下,以自动方式构建复杂领域知识库系统。王迎春
等[12] 针对知识库自动构建对准确率的较高要求,对上下位关系术语的抽取融合了后缀子串匹配、模板自动构建、实质提取三种方法,通过总结航空语料中出现的一些语言描述规则,在属性抽取方面也取得了很好的效果。谈春梅等[13] 采用知识元自动链接的方法,通过提取文本特征项,设计知识点描述句获取算法,解决了网络专题知识库智能构建的知识点挖掘问题。纵观目前基于这两类技术构建专题知识库的研究,总结如下:
(1)一个好的专题知识库应该包含结构化的知识体系、知识片段以及领域资
源[11] ,因此专题知识库拥有一个清晰表达专题概念体系的模式层,能够对数据层的知识和领域资源进行较好的组织和管理。虽然基于规则或机器学习的信息抽取方法简单有效且较为灵活,但是由于缺乏上层知识体系的规范和组织,抽取出来的只是知识片段,而非完整的结构化知识网络。(2)领域本体库以全面而清晰的概念结构和实例体系,采用基于词典的命名实体标注算法,能够对文章中的术语、实体等知识单元进行有效的语义标
注[14] 。然而对于具有重要描述意义的句子以及表达形式多样的数值型信息,仅依赖本体是无法准确地从文献中抽取的。(3)本体知识体系是基于本体建设专题知识库的核心,因此领域本体的质量和规模对标引结果有很大的影响。为了保证本体库的专业性和全面性,领域本体的构建过程从概念框架提出到概念丰富,一般需要权威领域专家的参与,并且本体实例的添加是一项异常烦琐的工作,需要大量的人工标引工
作[14] 。因此建设一个领域本体需要花费较多的时间和人力,更适合满足某一学科领域较大规模且持久性知识管理的建设目标。本研究旨在让专题知识库成为解决用户特定问题的工具,并作为图书馆的一种新型学科服务产品在科研人员中推广,因此专题知识库的资源建设追求的不是大而全,而是深且精,提供一个模式化的建设策略和流程能够实现面向多专题领域的快速定制。针对单独使用上述技术构建专题知识库存在的问题,本文提出一种将知识模式和规则相结合的知识抽取方法,实现专题知识库底层多粒度知识的获取与关联组织,在此基础上提供一系列专题知识服务。
3 基于文献知识抽取构建专题知识库的技术路线
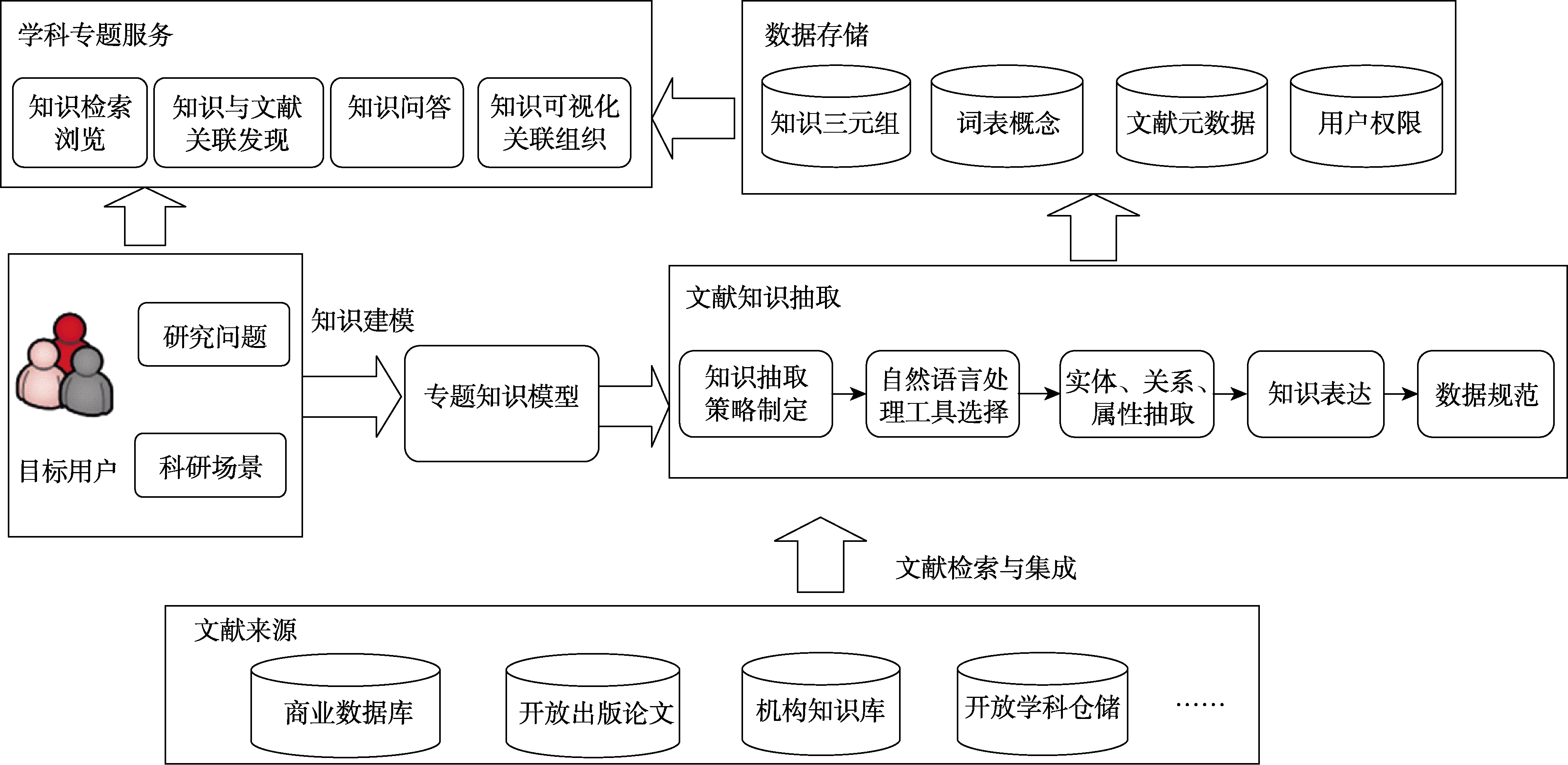
文献是科研人员快速准确地了解本研究领域发展动态和最新研究成果的最直接、有效的途径,因此本研究将文献资源作为专题知识库的知识获取来源。如何快速准确地从文献内容中得到用户需求的知识,是专题知识库资源建设和知识服务的根本。知识抽取是从自然语言文本中抽取预先制定的信息并形成结构化知识的关键技
术[15] 。本文提出了一种以知识模式为指导、多抽取策略相结合的知识抽取方法,紧密结合问题需求和科研过程,抽象研究要素及关系,构建知识模型,通过分析模型各节点的特征及在文献内容中的一般规律,制定知识模型各节点的知识抽取策略。按照相应策略,根据句子成分的相互依赖关系进行句法分析,引入自定义词典识别概念实体,并结合编制的抽取模式规则[16] ,处理实体、关系、数值、句子等多粒度层次关键知识点的抽取,按照知识模型结构组织成三元组实例。由于知识库是一系列具有属性的实体通过关系链接而形成的网状知识结构图谱,因此关于专题知识库建设流程的设计,本文也借鉴了自顶向下构建知识图谱的流程,即模式设计、数据获取、信息抽取、质量控制等流程,以及知识建模、实体识别、规则匹配等技术方法[17] ,设计了构建专题知识库的技术路线,如图1所示,具体实施方案包括:1)用户需求调研与知识库范围界定
知识库范围的界定将会影响到之后知识体系的构建以及文献资源的搜集策略,由于专题知识库一般是面向应用的,因此知识库的范围往往由用户需求和应用场景分析得到。专题知识库旨在关注某一学科细分领域,尤其用于解决具体问题,通过与用户深入沟通关注领域或问题、文献范围、知识需求、期望的服务形式等详细需求,确定专题知识库的主题和定位,并提出系统服务的几个应用场景和所要解决的问题。
2)专题知识模型构建
知识模型即预先定义领域中基本概念及概念关系的模式,是专题库知识抽取、规范、关联与存储的核心依据。本文采用领域知识建模的方法,在领域专家的帮助下,紧密结合用户需求,将相应科研过程和研究问题中的关键知识点抽象为概念类,建立概念之间的关系,从而构建领域概念关联组织模型。参考目标领域的叙词表、标准术语表和权威分类体系,扩展模型中概念类的同义词、上下位类,形成较为完整的知识组织体系。
3)文献收集与获取
按照用户需求和知识库的界定范围,确立领域文献资源的收集途径和策略。关于文献来源,虽然WoS(Web of Science)、PubMed、CNKI等科研用户常用数据库通常会对全文的获取和再利用权益有限制,但是目前科技论文的摘要部分提供了对整篇文献概述性的总结,基本能够涵盖研究的主要工作和关键成果,因此可通过检索和收集数据库中的文献元数据来作为分析的文献资源。如果用户想进一步了解研究思路、实验数据、设备参数等更加详细的研究要素,需要到全文中寻找具体论述,因此可考虑学科领域开放期刊、学科预印本平台等开放仓储以及机构知识库等自建仓储,根据这些资源或平台的开放政策和权限声明,扩展文献全文的获取来源。
4)文献知识抽取
信息抽取是一种自动化地从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成知识表达单元的文本处理技
术[18] 。本文采用基于知识工程的信息抽取方法[19] ,利用专题知识模型作为信息抽取的知识模式,根据知识模型中各节点特征及相应实例在文献中的结构、语法规律,选取合适的自然语言处理工具及编写模式规则处理特定实体、关系及属性的抽取,具体包含以下步骤:①知识模型各节点知识抽取策略制定:信息抽取涉及对实体、关系和属性的抽取,所抽取知识的粒度涉及数值、术语、句子多个层次,因此需要根据抽取目标的特征制定相应的抽取策略。对于有现有词表可利用的概念节点,采用词典匹配的方法识别和标引命名实体;通过判读和总结文献中相应语句的结构模式和语法特征,分别制定抽取规则和正则表达式对句子、数值粒度的概念、属性信息进行抽取;对于需要抽取的关系实例,通过分析句子成分的依赖关系判断和提取标引实体的关系。②自然语言处理工具的选择:首先考虑所处理文献的语种;由于专题库所涉及的领域纷繁多样以及知识粒度具有多个层次,因此要求所选抽取工具能够支持分词、句法分析、实体识别等自然语言处理基本任务,可较为灵活地添加自定义词典和抽取规则,具有广泛的应用领域并能提供较为齐全的词典语料;最后根据测试实验结果,选择某一适宜工具或工具中的某些功能组件。③知识抽取:首先将获取到的全文PDF文档转化为全文本格式,并进行句子级别的切分,然后调用工具的相应功能模块进行分词、句法依赖性分析、实体识别、规则提取等过程,完成特定实体、关系及属性的抽取。④知识表达:把抽取到的实体及关系实例对应到知识模型中相应的概念类别和关系,按照节点、边及节点属性的表示方式,生成“实体—关系—实体”、“实体—属性—属性值”三元组,作为知识的表达方式。⑤数据规范:由于抽取出的结果不可避免地存在噪音数据,因此还应充分考虑人工干预,组织一批具有领域研究背景的人员进行人工判断、纠错、整理等质检和规范流程,以保证知识库质量。5)开发系统功能
本文采用图数据库和关系型数据库相结合的方式实现专题知识库的数据存储。图数据库用于表达知识要素间的关联结构,规范和维护专题知识模型中节点、边、属性及其相互之间的联系,对“实体—关系—实体”、“实体—属性—属性值”三元组所形成的底层知识图谱进行存储和管理。对于词表中概念的存储字段、知识三元组与来源文献的关联、文献元数据信息,以及用户注册、登录及权限信息,则采用关系数据库进行存储。
6)专题知识服务
基于底层知识存储,专题知识库系统能够根据预先设计的服务场景提供一系列知识服务。通过将自然语言查询转换为对图数据库中知识三元组的查询,实现知识检索服务。根据知识与文献的对应关系,用户可得到知识来源的文献元数据信息,对于感兴趣的研究通过全文链接进一步到其他文献数据库中获取查看。本专题知识库面向具体研究问题提供知识问答服务,为用户解决预期问题提供所需答案。关于知识的浏览,不仅是检索知识点本身内容的展示,而且基于知识间的关系,知识得以聚合关联并以图形化方式呈现,使用户可清晰地获得检索主题的知识结构。
4 中药活血化瘀专题知识库建设
4.1 用户需求和建设目标
随着科研人员越来越多地关注于如何从海量数据中快速地发掘精准信息,笔者所在资源建设团队面向中国科学院各研究所提供按需定制的专题数据服务。在开展“大数据定制服务”在线问卷调研过程中,了解到有科研人员希望关注川芎、丹参等临床用于活血化瘀的中药及对应的川芎嗪、丹参酮等活性小分子。因此确定了本专题知识库的建设目标和核心问题,即从大量药理和临床研究的文献中抽取临床疗效、生物靶点和作用机制等方面的数据或研究成果,构建专题知识库以促进需求知识的快速查找、发现与获取,为科研人员在开展活血化瘀领域新研究或临床治疗时提供大量真实有效的知识和文献参考依据。
在深入了解用户需求和确定知识库建设目标后,与用户共同设计和确认了知识库的服务场景及需要解决的研究问题,包括:①查询某药剂或活性小分子能够治疗的疾病,治疗某疾病可用哪些药物或活性小分子及相应的给药方案;②某药剂或活性小分子治疗某疾病时,有哪些表征疗效的实验室检测指标及其变化情况;③某药剂或活性小分子在治疗某疾病时作用的生物靶点;④某药剂或活性小分子治疗某疾病的实验对象、采用的实验方法,以及不同给药方案组的疗效对比情况。针对以上研究问题的查询或提问,获得知识答案的同时,还能够全面了解其他相关知识,直观地了解需求点的知识结构及研究现状,并可追溯来源文献作为论证依据。
4.2 中药活血化瘀专题知识模型构建
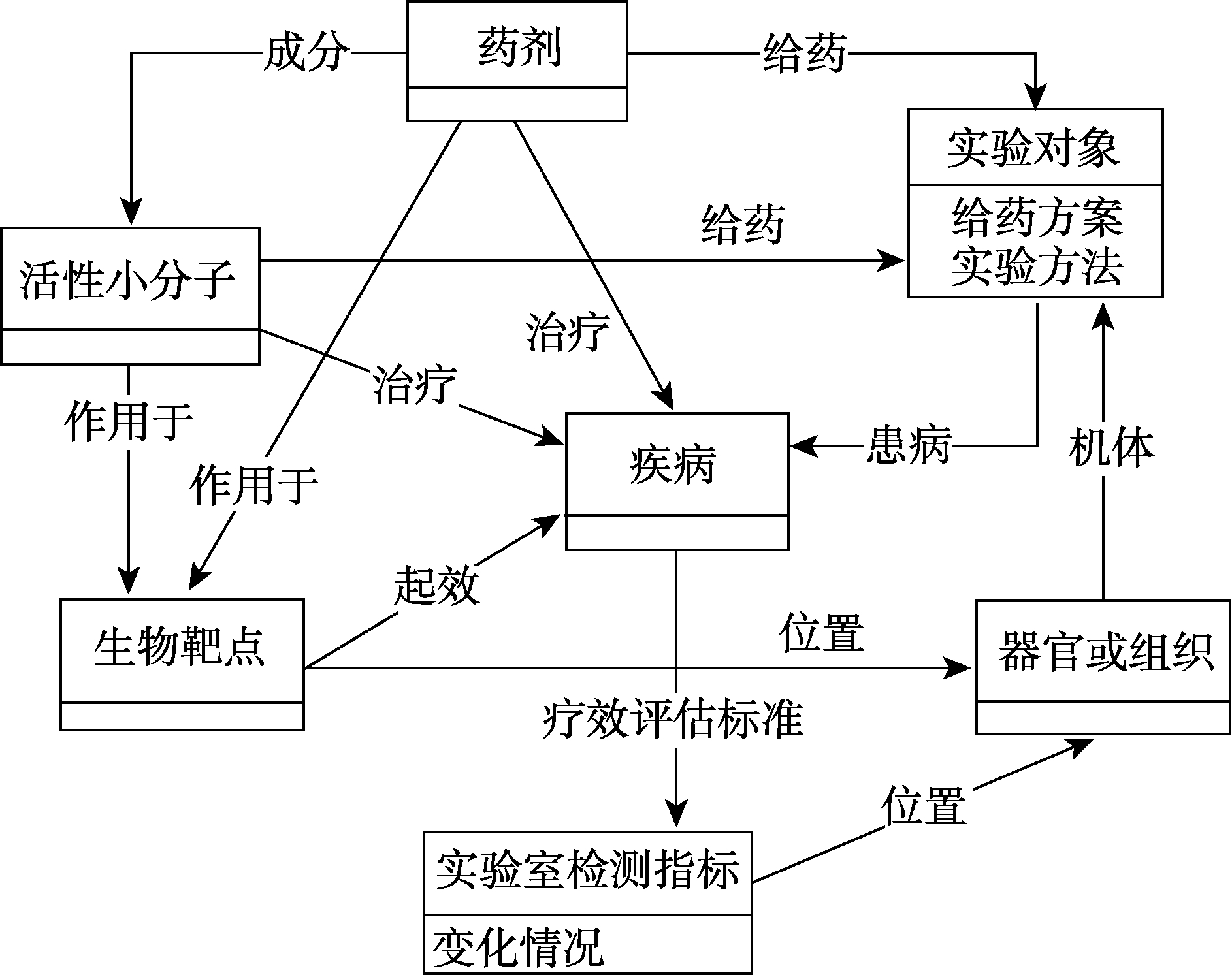
在中医理论体系和领域专业人员的指导下,结合中医临床研究过程和专题库服务目标,采用知识建模的方法,将研究问题和科研场景中的实体和关系进行抽象,构建能够完整表达服务场景的模型,分别包括以下方面:
1)实验过程的实体和关系
为了研究某药剂(该药剂可以是某味完整药物,也可以是中药的某个活性小分子提取物,也可以是多味药物或多个小分子的复合方剂)治疗某疾病的临床疗效,一般会将一定数量的实验对象组成实验组、对照组或治疗组等给药方案组,施以一定的剂量和疗程,或采用某实验方法进行研究。
2)疗效评价的实体和关系
临床实验通过具体检测指标来评价某药剂在治疗某疾病中的疗效,指标既有全身性的,也有在某些器官或机体组织中体现的,指标数值的变化用于表示该药剂的治疗情况。一方面是患者的主观评估,表征患者症状是否改善,比如,疼痛的减轻、生活质量的评分;另一方面是采用化学、物理检测方法获得的客观评价结果,例如,和活血化瘀最直接相关的血液系统评价指标,包括血小板功能、血液流变学、微循环、凝血功能等方面的指
标[20] 。3)药物作用机制的实体和关系
生物靶点是机体与药物结合的部分,包括受体、酶等,由于中药单味药的成分复杂性,与机体生物靶点产生作用的可能是整个药剂也可能是某一个或某几个活性小分子。药剂作用于实验对象,药剂或活性小分子对生物靶点产生作用,导致一系列复杂的生物效应过程,从而对治疗某疾病产生某些实验室检测指标的具体变化。
根据以上对科研场景的完整分析,可大致概括其中所涉及的实体类型,包括疾病、药剂、活性小分子、实验室检测指标、生物靶点、实验对象、器官或组织,其中将给药方案、实验方法作为实验对象的数值属性,以及为实验室检测指标设置数值属性(变化情况),通过对上述科研场景中工作流程的梳理,建立各实体之间的关系,如图2所示,建立能够完整表达研究问题和科研场景的知识模型。
为了保证后续实体抽取的规范性,参考中医药领域专业词表、网络流行标准,为知识模型的关键节点补充分类体系、同义词表。通过调研《中医证病名大辞典》、《中医药主题词表》、《国际疾病分类》等领域权威专著以及医院普遍采用的疾病挂号分类、中草药药物名称等临床标准,经过领域科研人员的审核与完善,确定了疾病、药剂、活性小分子、实验室检测指标、器官或组织节点的知识组织体系。
4.3 文献检索和获取
由于此专题知识库的目标用户重点关注活血化瘀临床和药理领域的中文文献,通过大量查阅和研读此方面的文献,普遍所采用的结构性文摘包含了主要研究工作和研究成果,已基本涵盖了知识模型要素,因此检索来源选取中国知网近10年的文摘数据。关于检索式的确定,多次征求了用户意见并将每次检索结果与用户确认,考虑到有几种活血化瘀临床常用的中药及对应小分子是用户重点关注的,因此除了“活血化瘀”,还要将川芎及川芎嗪、丹参及丹参酮ⅡA等八种中药及对应小分子作为检索词。检索获得近10年文献并导出题名、作者、摘要等题录信息,组织该领域专业人员对文献进行判读,筛选出用户所关注的临床和药理方面的文献。
4.4 知识抽取
通过人工判读和总结活血化瘀临床和药理领域中文文献写作的一般规律和主要研究内容,分析知识模型中各节点及属性、实体间关系的特征,制定抽取策略(表1),其中根据用户在药物对生物靶点作用机制方面的研究需要及关系实例化的必要性,本专题知识库对关系的抽取只关注药剂或活性小分子与生物靶点的作用关系实例。
表1 中药活血化瘀领域知识模型各节点的抽取策略
名称 特征分析 抽取方法 具体策略 疾病、药剂、活性小分子、实验室检测指标、器官组织 具有较完善的学科概念体系 基于词典匹配的实体识别 调研现有词表或术语规范作为抽取词典 实验对象、生物靶点 虽无可复用的词表,但在结构文摘中一般有较强的特征规律 正则表达式 总结其在摘要的文本结构和上下文信息规律 属性 句子、数值 抽取规则+正则表达式 根据各属性值的模式特征、语法特征和行文规律,编写抽取规则和正则表达式 药剂或活性小分子与生物靶点的作用关系 包括增强、抑制、下调、上调、提高、降低等关系值 句法分析 根据句子中成分的依赖性分析,提取标引实体的关系 根据已制定的抽取策略选择适宜的自然语言处理工具,在团队较熟悉的中文处理开源工具中,考虑一方面需要支持分词、词性标注、句法分析、命名实体识别等自然语言处理的基本任务,另一方面需要支持自定义添加用户词典,并在中文分词和实体识别方面有较好的测试结果,因此首先选取了Stanford CoreNLP、中科院NLPIR、HanLP。通过对比和测试这三种工具,发现Stanford CoreNLP由于缺少中文处理的参考文档,在灵活地选择和组合功能组件时缺乏指导依据;NLPIR本地版暂没有开放依存句法分析等功能,只可在网页平台使用。对于关系的抽取,实验了斯坦福大学的Open IE工具直接提取三元组关系,但对于中药活血化瘀这样较为精细的专业领域,关系识别的效果不理想。经过上述对比分析,HanLP面向既定抽取策略具备较完善的自然语言处理功能,而且拥有丰富的指南文档,词典明文发布,自定义使用更加方便和灵活。因此,调用HanLP的中文分词、依存句法分析、实体抽取等功能模块,并通过总结提炼文本特征规律制定抽取规则,对文献中实体、关系及属性进行解析和抽取。基于知识模型完成抽取信息的实体归类、关系建立、统一格式等操作,并组织中医药领域专业人员对抽取结果进行人工抽查、补充和纠错,最终形成按照“实体—关系—实体”、“实体—属性—属性值”组织的知识三元组。
4.5 系统实现与原型系统
为了让系统可以跨平台运行,中药活血化瘀专题知识库原型系统采用Java开发环境,采用Neo4J图数据库和MySQL关系数据库相结合的底层数据存储。系统对专题知识组织体系的管理,一方面维护专题知识模型中节点、边、属性及其相互之间的联系,支持模型节点知识组织体系的构建和维护,提供分类体系、词表的导入以及概念条目的增加、删除等操作;另一方面将概念标识符、优选名称、上位概念和同义词作为概念的存储字段,完整表达每个概念的层级关系及同义词网络。关于底层数据存储,在知识模型的指导下设计存储方式和关系,知识三元组通过图数据库表达和存储,关系数据库则用于存储和管理用户信息、权限信息、来源文献元数据,系统后台支持数据条目的增加、删除以及批量导入等数据更新操作。
专题知识库通过对知识组织体系和知识实例、数据的组织管理,提供了丰富的知识服务。中药活血化瘀专题知识库提供了如下服务:
1)知识检索浏览及来源文献发现
该专题库原型系统的主页面如图3所示,提供了检索点单独检索和组合检索的方式。依据知识模型的节点,检索点设置药剂、活性小分子、疾病、实验室检测指标、生物靶点,用户既可选中某一个检索点,也可将多个检索点组合进行检索。由于知识模型导入了疾病、中药药剂等关键实体的同义词表,因此实现了同义词检索,例如,用户输入关键词“中风”,系统会带着“仆击”、“偏枯”、“卒中”等同义词返回更完整的结果。系统将用户重点关注的几种药剂及其活性小分子、常见疾病的检索链接以及知识关联组织、文献统计分析的可视化链接放在首页,供用户快速获取检索结果和可视化图谱。
返回的检索结果分为“数据”和“循证文献”两部分。由于文献内容已按照知识模型节点形成大量碎片化数据,因此对于返回的数据结果,系统根据知识模型节点设置分面扩展检索的条件和展示字段,也提供了进一步查看来源文献的链接,如图4所示的某条数据检索结果的展示效果;“循证文献”则用于展示匹配用户检索的文献结果,以关键词、来源期刊等文献信息作为扩展检索的条件和展示字段。
2)知识问答
知识问答作为本专题数据库的特色服务,基于存储的知识三元组和知识关系推理,为用户解决特定问题提供所需答案。将预先设计的服务场景转化为具体问题,提供固定问题句式作为提问指导,例如,“丹参用于治疗哪些疾病”,“丹参治疗妊娠高血压综合征有哪些临床评价实验指标”等,用户输入问题后即可获得所关注问题的结果。
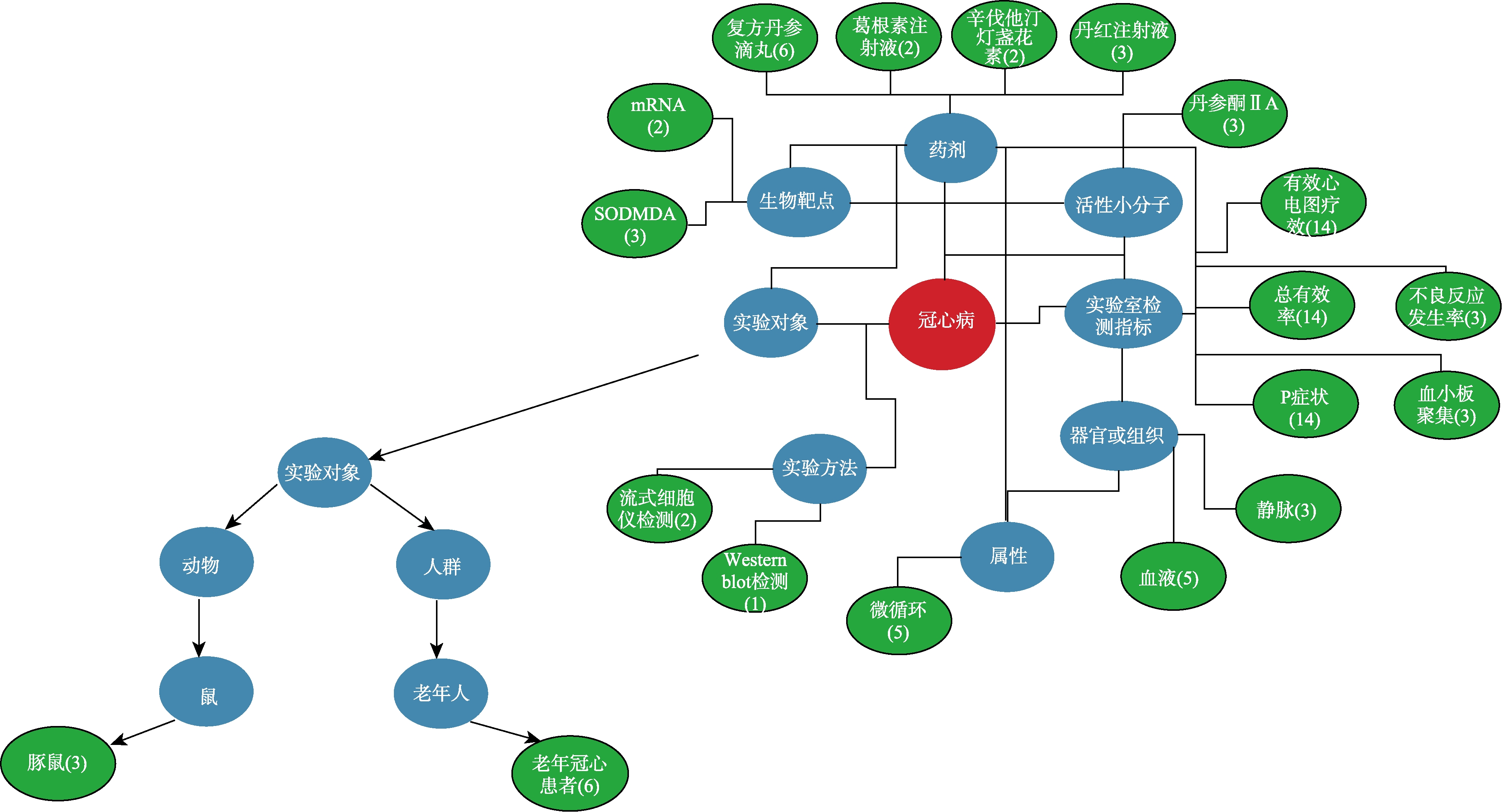
3)知识可视化关联组织
系统在返回检索结果或提问答案时,基于检索点或答案所属实体类型及其在模型中与其他实体的关系,将匹配的知识实例及其来源文献信息进行可视化组织。如图5所示,知识结构图由内及外揭示了三类实体:处于中心的实体表示检索点,用户检索“冠心病”,则“冠心病”就是固定的已知检索点;与检索点相关联的是知识模型中的其他实体,与“冠心病”疾病实例相关联的模型实体有药剂、生物靶点、实验室检测指标等;模型这些节点所匹配的实例及其来源文献数目在最外层表示,点击可对目前检索结果进行扩展检索。图中还可查看模型节点的树状分类结构以及所匹配的实例,如图5中可进一步查看“实验对象”实例分别在分类体系中的位置。
5 系统测试效果评估
根据中医药领域科研人员对系统功能的测试结果,以及目标用户的使用反馈,该专题知识库的资源建设和功能服务已基本实现预期需求,能够快速查询问题答案、获取检索主题相关知识及来源文献信息、轻松梳理检索主题的知识结构和研究现状。与采用传统文献资源建设的数据库相比,本专题知识库的特色与优势在于:
1)能够快速获得预期研究问题的答案
系统的知识问答功能对预期设计的研究问题能够直接给出问题答案。例如,用户提问“丹参治疗妊娠高血压综合征有哪些临床评价实验指标”,系统能够给出答案“P内皮素SODMDA平均动脉压、PELISA”。
2)为活血化瘀中医药领域研究提供大量有效的事实、知识和文献研究证据
本专题知识库采用“知识+文献”的资源建设模式,通过文本内容细粒度解析所形成的知识片段易于用户处理和分析,提供的来源文献信息使用户有据可查。如图5示例,用户想了解表征冠心病疗效的实验室检测指标都有哪些,通过组合检索可匹配到“血小板聚集”、“P症状”等知识结果,用户想进一步了解包含指标“血小板聚集”三篇文献的研究过程,可利用系统提供的文献题录信息到其他文献库中查找。
3)能够直观地把握研究主题的知识结构和研究状况
本专题知识库嵌入知识模型作为知识抽取、组织、存储和展示的依据,将所关注研究问题的关键知识点进行深度解析和关联组织,因此用户可以直观地获得某一研究主题的知识结构和研究进展。正如图5所展示的,围绕“冠心病”所呈现的知识结构,以及由每个模型节点对知识实例和来源文献的组织,使用户能够对“冠心病”这一主题所涉及的知识及研究成果有较为全面的把握。
6 结 语
面对大数据环境下科研方式和资源形态转变带来的挑战,图书馆不能仅停留在数据采集、存储等资源简单堆砌层面的服务,而应在学科精准服务、知识深度加工和重组能力方面展现优势。本文面向活血化瘀中医药领域,基于文献知识抽取建设专题知识库的研究实践,通过对文献的深度解析和再利用,不仅为用户提供了定位于特定研究问题解决的个性化精准服务,也为数据密集型环境下资源建设与学科化、个性化知识服务提供了转型方式。数字科研环境下新型学术交流模式的出现以及开放获取运动的蓬勃发展,推动了科学数据、实验指南、技术标准、数据管理计划、项目报告等具有学术研究价值的科研成果的获取和再利用,因此未来专题知识库的知识获取来源可不局限于论文等正式出版物,基于非文本资源和灰色文献的知识解析、抽取和加工,构建更加丰富的知识仓储,将是专题库知识库未来的发展方向。
参考文献
- 1
Sun H. New type of library service items—Research on service based on bibliometrics[C]//Proceedings of the International Conference on Education Technology, Management and Humanities Science. Atlantis Press, 2015: 201-204.
- 2
黄金霞, 马雨萌. 大数据时代开放信息资源的数据服务能力思考[J]. 数字图书馆论坛, 2016(8): 54-59.
- 3
Yarkoni T, Poldrack R A, Nichols T E, et al. Large-scale automated synthesis of human functional neuroimaging data[J]. Nature Methods, 2011, 8(8): 665-670.
- 4
Tsuruoka Y, Miwa M, Hamamoto K, et al. Discovering and visualizing indirect associations between biomedical concepts[J]. Bioinformatics, 2011, 27(13): i111-i119.
- 5
Oğuz F, Şengün A E. Mystery of the unknown: Revisiting tacit knowledge in the organizational literature[J]. Journal of Knowledge Management, 2011, 15(3): 445-461.
- 6
张鸣. 知识服务方式之一——构建学科专题知识库[J]. 图书馆学刊, 2006, 28(3): 108-110.
- 7
咸珂. 基于本体的健康知识库自动构建方法[D]. 哈尔滨: 哈尔滨工业大学, 2015: 3-6.
- 8
Razmerita L, Angehrn A, Maedche A. Ontology-based user modeling for knowledge management systems[C]// Proceedings of the 9th International Conference on User Modeling. Heidelberg: Springer, 2003: 213-217.
- 9
钱智勇. 基于本体的专题域知识库系统设计与实现——以张謇研究专题知识库系统实现为例[J]. 情报理论与实践, 2006, 29(4): 476-479.
- 10
王昊, 谷俊, 苏新宁. 本体驱动的知识管理系统模型及其应用研究[J]. 中国图书馆学报, 2013, 39(2): 98-110.
- 11
许鑫, 郭金龙. 基于领域本体的专题库构建——以中华烹饪文化知识库为例[J]. 现代图书情报技术, 2013(12): 2-9.
- 12
王迎春, 蔡东风, 叶娜. 基于实体—属性框架的领域知识库构建[J]. 沈阳航空航天大学学报, 2011, 28(2): 69-73.
- 13
谈春梅, 段卫华, 曹松强. 网络专题知识库关键技术的研究与实现[J]. 现代图书情报技术, 2009(4): 70-74.
- 14
郭金龙, 洪韵佳, 许鑫. 中华烹饪文化领域本体构建及其应用[J]. 现代图书情报技术, 2013(12): 10-18.
- 15
丁玉飞, 王曰芬, 刘卫江. 面向半结构化文本的知识抽取研究[J]. 情报理论与实践, 2015, 38(3): 101-106.
- 16
化柏林, 刘一宁, 郑彦宁. 针对学术定义的抽取规则构建方法研究[J]. 情报理论与实践, 2011, 34(12): 5-9.
- 17
刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.
- 18
Cowie J, Lehnert W. Information extraction[J]. Communications of the ACM, 1996, 39(1): 80-91.
- 19
Elloumi S, Jaoua A, Ferjani F, et al. General learning approach for event extraction: Case of management change event[J]. Journal of Information Science, 2013, 39(2): 211-224.
- 20
史载祥, 杜金行. 活血化瘀方药临床使用指南[M]. 北京: 人民卫生出版社, 2014: 126-213.
- 1
摘要
大数据时代科研人员对高效获取和利用领域知识提出了更高的要求,文献作为科研人员快速准确地了解本领域研究状况的有效途径,基于文献的知识发掘已成为一种新的科研方式。专题知识库作为组织和管理某一特定领域知识的工具,能够用于挖掘和展现文献背后的知识以满足用户个性化需求。本文提出了面向特定研究问题的专题知识库建设路线,采用基于知识工程的信息抽取方法,通过抽象研究问题要素构建专题知识模型,将其作为信息抽取的知识模式,制定知识模型各节点的知识抽取策略,对文献中实体、关系及属性进行解析、抽取与关联组织,基于这些结构化知识提供知识检索、浏览、问答、可视化关联组织等一系列知识服务。然后以中药活血化瘀领域建设实践为例,详细阐述了基于文献知识抽取构建专题知识库的实施方案。系统功能测试显示,该专题知识库能够实现知识快速查询、知识与文献关联发现、知识结构梳理等预期服务场景。本研究提供了一种构建专题知识库行之有效的技术路线,能够帮助科研用户快速而准确地定位和获取文献中的深层知识,提供了数据密集型科研环境下学科化资源建设与个性化精准服务的转型方式。
Abstract
Researchers put forward higher requirements for efficient acquisition and utilization of domain knowledge in the big data era. As literature is an effective way for researchers to quickly and accurately understand the research situation in their field, knowledge discovery based on literature has become a new research method. As a tool to organize and manage knowledge in a specific domain, the subject knowledge base can be used to mine and present the knowledge behind the literature to meet users’ personalized needs. This paper designs the construction route of the subject knowledge base for specific research problems. An information extraction method based on knowledge engineering is adopted. First, a subject knowledge model is built through abstraction of the research elements. Then, under the guidance of the knowledge model, the knowledge extraction strategy of each model node is developed to analyze, extract, and correlate entities, relations, and attributes in the literature. Finally, a database platform based on this structured knowledge is developed that can provide a variety of services such as knowledge retrieval, knowledge browsing, knowledge Q&A, and visualization correlation. Taking construction practices in the field of activating blood circulation and removing stasis as an example, this paper analyzes how to construct a subject knowledge base based on literature knowledge extraction. As the system functional test shows, this subject knowledge base can realize the expected service scenarios such as quick query of knowledge, related discovery of knowledge and literature, and knowledge organization. As this study proposes an effective technical route to building a subject knowledge base to help researchers locate and acquire deep knowledge in literature quickly and accurately, it provides a transformation mode of resource construction and personalized precision services in the data-intensive research environment.