1 引 言
微博数据中心发布的《2017微博用户发展报告》显示,截止到2017年9月,微博月活跃用户已达3.76亿,日活跃用户已达1.65
亿[1] 。如何从庞大的微博数据中获得用户感兴趣的信息,是微博检索需要解决的问题。微博检索虽属文本检索范畴,但却不同于传统文本检索,二者在排序原则和搜索数据方面有所不同[2] 。在排序原则方面,微博检索除要考虑查询与文档的内容相似度外,还应考虑其他因素,如时间、兴趣、博文质量等;在搜索数据方面,微博检索面向的是微博文档,其典型特点是长度较短,内容稀疏。基于以上区别,相关学者对传统文本检索方法进行了系列改进,以期获得适合于微博检索的检索方法。微博检索领域应用较多的是查询似然模
型[3] 。结合微博的特点,研究者多从两方面对其进行改进:①对先验概率的改进:Liang等[4] 利用微博文档的爆发特性改进了微博文档的先验概率,使越靠近查询爆发期的微博文档具有越高的先验概率;Li等[5] 基于微博文档的爆发性和邻近性对微博文档的先验概率进行改进,使满足不同查询意图的微博文档具有不同的先验概率;叶施仁等[6] 基于向量空间模型和潜在语义分析,改进了微博文档的先验概率,使与查询主题相关的微博文档具有更高的先验概率。②对语言模型估计的改进:Jiang等[7] 将搜索集中的高质量微博作为平滑项对微博文档的语言模型估计进行改进,提高了微博检索中获取高质量微博的可能性;卫冰洁等[8] 将同属一个Hashtag标签的微博集作为平滑项对微博文档进行扩展,提高了微博文档语言模型估计的准确性;李锐等[9] 将属于同一作者的微博作为平滑项对微博文档的语言模型估计进行改进。在实际微博检索中,符合检索用户兴趣的微博文档应被赋予较高的先验概率,但上述改进文档先验概率的相关研究中未考虑检索用户的兴趣。此外,Tommasel
等[10] 认为扩展微博短文本可以从内容及用户交互两方面入手,但现有改进微博文档语言模型估计的研究尚未混合内容及用户交互两方面信息对微博文档进行估计。基于此,本文对查询似然模型进行改进,提出一个改进的面向微博检索的查询似然检索模型。主要贡献包括:(1)利用微博用户兴趣改进文档先验概率,使符合用户兴趣的微博在检索结果中具有较高的排名,以满足用户的个性化检索需求。
(2)混合内容及用户交互两方面信息,对查询似然模型中的文档语言模型估计进行改进,解决微博长度较短、内容稀疏的问题,提高微博文档语言模型估计的准确性。
2 查询似然模型
Ponte
等[11] 于1998年首次将语言模型应用于信息检索领域,随后查询似然模型逐步成为语言模型在信息检索领域中应用的主流模型。设式中,
在传统查询似然模型中,
法[12] :式中,
式中,
3 查询似然模型在微博检索中的不足分析
传统查询似然模型假设文档先验概率是相等的,忽略了文档先验概率对排序结果的影响。实际检索过程中,由于用户的检索意图与自身兴趣有关,文档先验概率应依据用户兴趣的不同而有所差异。例如,图1为依据新浪用户1004061241148864近期发布的50篇微博生成的词云。从图1可以发现,该用户对“音乐”、“张杰”、“巡演”、“演唱会”、“唱歌”、“鸟巢”等关键词比较感兴趣。对该用户而言,如果待检索微博中某篇微博与该用户的兴趣关键词重合较多,则这篇微博就应被赋予较高的先验概率。然而,现有研究并未基于用户兴趣对微博文档的先验概率进行区分,这不利于实现微博用户的个性化检索需求。
此外,在文档语言模型估计方面,现有研究通过不同平滑方式对文档语言模型的估计做出改进,具有代表性的方法有基于全局信息和基于作者建模两种。下面结合实例对比分析本文提出的混合内容和交互两方面信息进行平滑的有效性。微博用户1004061241148864发表了一篇博文B,内容如下:
“#张杰未LIVE巡回演唱会#八万人鸟巢体育场!内场30秒售完!全部门票2分38秒售完!爱好音乐的星星们也不要急,继续关注其他场次哦!”
表1列出了新浪平台中4条待检索微博示例。
表1 微博相关性示例
微博编号 博文内容 相关性 1 #张杰未LIVE巡回演唱会#哇!八万人鸟巢体育场!内场30秒售完!全部门票2分38秒售完!所以约好的快乐家族和朋友们去看演唱会还会有站票吗? *# 2 #张杰未LIVE巡回演唱会#希望看到谢娜和张杰同台,已经按捺不住激动的心情,鸟巢体育场!我们不见不散! * 3 杰哥新歌mv,我在模仿中... # 4 刚刚路边社消息,中美贸易战第一阶段结束,多进口2000亿美元的货物 — 注:“相关性”表示待检索微博与博文B的相关性描述;“*”表示属于同一个作者,“#”表示博文所属用户间交互密切,“—”表示不存在相关性。
在上述微博示例的基础上,采用基于全局信息、基于作者建模和本文提出的平滑方法分别对博文B进行平滑,平滑结果如表2所示。从表2可以看出,如果采用全局信息进行平滑,微博B的稀疏性虽得到解决,但微博4会引入噪声词,如“路边社”、“中美贸易战”等;采用方法2进行平滑,可在一定程度上实现对微博B的扩展,但没有充分地引入微博B的所有相关词;与前两种方法相比,采用本文提出的方法3进行平滑,结果更为理想,为微博B引入了更多的相关词,且避免了噪声词的引入。
4 微博检索模型
在上述分析的基础上,以传统查询似然模型为理论基础,提出一种基于用户兴趣和混合估计的微博检索模型,该模型的实现涉及文档先验概率的改进和文档语言模型估计的改进。
4.1 基于用户兴趣的文档先验概率计算
为使符合用户兴趣的微博文档具有更高的先验概率,本文依据用户兴趣计算微博文档的先验概率,具体步骤为:首先依据用户对博文的兴趣行为计算用户对博文的兴趣度,其中用户对博文的兴趣行为包括发布、点赞、转发、评论及收藏;然后选取兴趣度大于一定阈值的博文作为用户的兴趣博文,所有兴趣博文构成该用户的兴趣博文库;最后通过计算兴趣博文库对微博文档的覆盖度,计算微博文档的先验概率。
4.1.1 用户对博文的兴趣度
用户对博文的兴趣度是指用户对某一条博文的感兴趣程度,具体通过用户对博文的兴趣行为体现。假设用户
式中,
式中,
4.1.2 基于用户兴趣的文档先验概率
依据用户
式中,
式中,
4.2 混合内容和用户交互的文档语言模型估计
本文基于交互行为和内容相似获得微博的相关微博集,并将其用于平滑初始微博,实现对文档语言模型估计的改进。具体步骤为:首先通过量化搜索集中任意两条微博间的内容相似性及其所属用户间的交互行为,得到任意两条微博文档之间的相关度;然后选取与每一条微博的相关度大于阈值
4.2.1 混合内容和用户交互的微博文档相关度
本文从内容和用户交互两方面衡量微博文档间的相关度。首先计算搜索集中任意两条微博
式中,
1)内容相似度计算
本文首先采用向量空间模
型[15] 将微博文档表示为向量形式,然后运用余弦夹角公式计算任意两条微博的内容相似度,微博式中,
法[16] 计算。微博文档2)用户交互度计算
本文依据用户间的交互行为计算用户间的交互度。用户间的交互行为有别于用户对博文的兴趣行为,强调用户之间的联系。与前文中的兴趣行为相比,用户间的交互行为增加了关注、提及、私信,去掉了发布和收藏。用户
式中,
式中,
4.2.2 文档语言模型估计
依据上述
式中,
式中,
5 实证研究
5.1 实验数据
目前微博检索中比较权威的实验数据集为TREC评测数据
集[17] ,但该数据集不包含微博用户的交互关系,无法满足本文的实验要求,故我们依据小型测试集合的构建方法[18] 构建了一个符合实验需求的小型测试集合。首先采用网络爬虫工具爬取了661845条新浪微博,所爬数据包括:微博的文本内容、微博的发布时间、微博用户及其关注的用户。然后在原始数据的基础上参照TREC的评测要求做出以下预处理:①去除已失效或不存在的微博;②去除长度小于40个字符的微博;③将微博中的繁体字转化为简体字。数据集包括三部分:文档集、查询集及相关判断集。其中,文档集共包含3897篇微博文档,查询集包括隶属于不同检索用户的5个查询,相关判断集包括每个查询的相关文档集和不相关文档集。相关性标注采用Pooling方法[19] 人工标注。5.2 评价标准
本文采用TREC微博检索任务中官方指定的评价指标
式中,
式中,
5.3 实验及分析
实验包括三部分:第一部分为相关参数的设定,第二部分和第三部分为不同模型的检索性能对比。其中第二部分实验在传统查询似然模型的基础上,对比了仅改进先验概率、仅改进文档语言模型估计及二者同时改进的模型性能;第三部分对比了本文最终给出的改进模型与目前主流的改进模型的性能。表3给出了实验涉及的模型简写。
5.3.1 相关参数确定
本文实验涉及的相关参数包括兴趣度阈值
法[23] 进行确定。受实验数据的限制,实验中的兴趣行为仅考虑了发布行为,交互行为仅考虑了关注行为,故实验中的参数确定部分不涉及参数1)兴趣度阈值
本文通过计算不同兴趣度阈值下(
2)调和参数
本文通过计算
表4 不同阈值
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.6 0.42 0.45 0.51 0.49 0.44 0.39 0.32 0.29 0.26 0.7 0.43 0.46 0.54 0.5 0.43 0.39 0.35 0.3 0.27 0.8 0.43 0.49 0.56 0.51 0.49 0.41 0.36 0.34 0.31 0.9 0.42 0.48 0.52 0.51 0.45 0.4 0.33 0.3 0.26 从表4可以看到,当调和参数
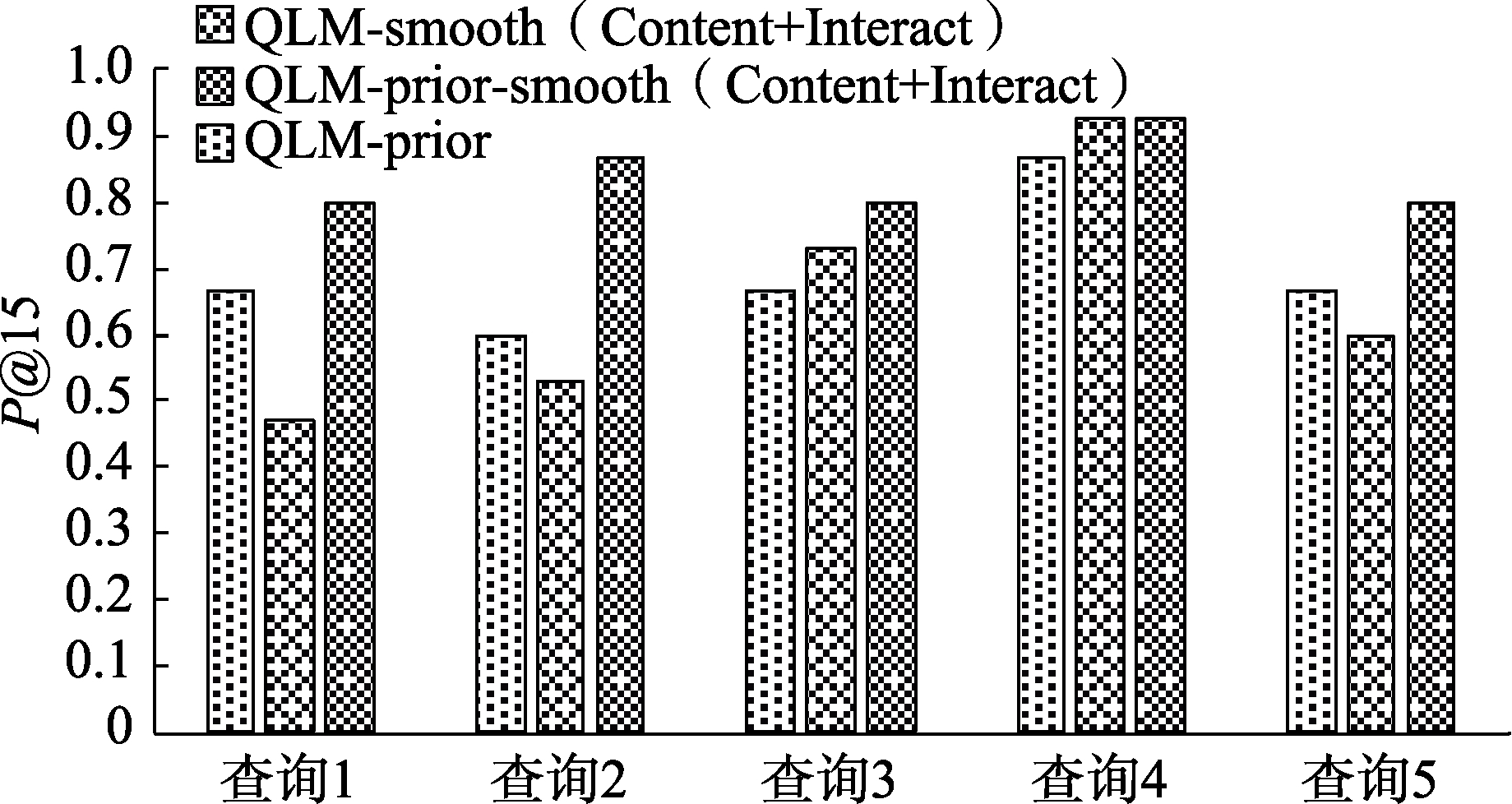
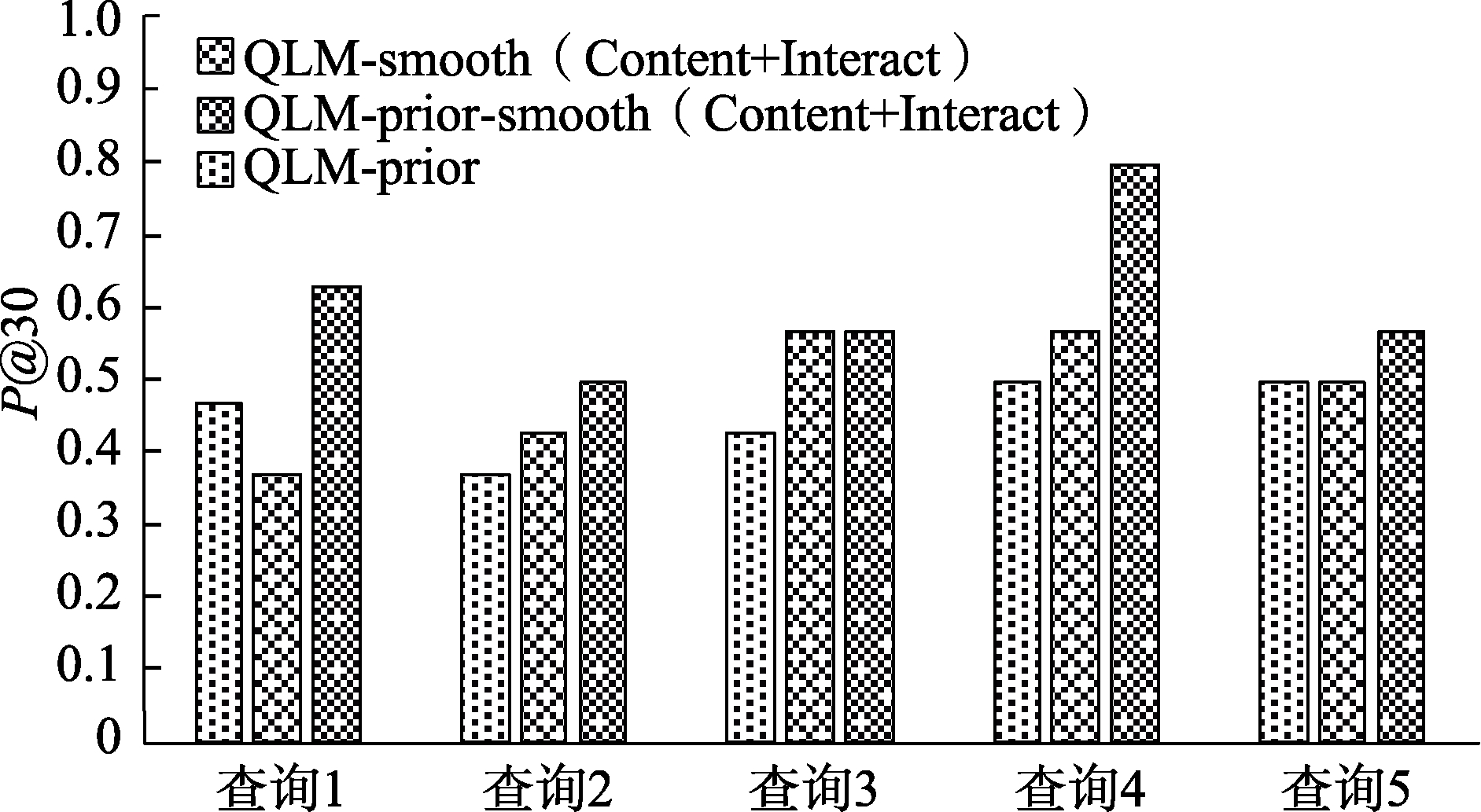
5.3.2 QLM-prior、QLM-smooth(Content+Interact)、QLM-prior-smooth(Content+Interact)检索性能比较
1)查准率比较
为验证QLM-prior、QLM-smooth(Content+Interact)、QLM-prior-smooth(Content+Interact)的查准率,实验首先计算了5个查询在这3个模型上的
从图3和图4可以看出,查询1、查询2及查询5的
为避免单个查询对评价结果造成的偏差,本文又分别计算了5个查询在3个模型上的平均
2)相关文档排名比较
实验通过计算3个模型的MRR值对不同模型中相关文档的排名进行评价。由于MRR依赖于第1篇正确文档的排名,而3个模型的第1篇相关文档均排名第1位,因此仅将第1条相关文档视为正确文档,难以区分不同模型检索性能的好坏。为解决该问题,实验依次对不同模型的前5篇相关文档排名进行评价。表6给出依据3个模型的前5篇相关文档计算得到的MRR-1、MRR-2、MRR-3、MRR-4和MRR-5以及3个模型的平均MRR。
表6 3个模型的MRR值
MRR 模型 QLM-prior QLM-smooth(Content+Interact) QLM-prior-smooth(Content+Interact) MRR-1 1.00 1.00 1.00 MRR-2 0.50 0.50 0.50 MRR-3 0.32 0.29 0.33 MRR-4 0.22 0.18 0.25 MRR-5 0.16 0.15 0.19 平均MRR 0.44 0.42 0.45 从表6可以看出,除3个模型的MRR-1和MRR-2相等外,QLM-prior-smooth(Content+Interact)的MRR-3、MRR-4、MRR-5和平均MRR均高于QLM-prior和QLM-smooth(Content+Interact),这说明与QLM-prior和QLM-smooth(Content+Interact)相比,QLM-prior-smooth(Content+Interact)的相关文档在检索结果中的排名更靠前。
综上所述,QLM-prior-smooth(Content+Interact)在查准率和MRR两个方面均优于QLM-prior和QLM- smooth(Content+Interact)。产生上述结果的原因为:与QLM-prior相比,QLM-prior-smooth(Content+ Interact)混合了内容和用户交互对微博文档的语言模型进行估计,有效解决了微博文档的稀疏性,而QLM-prior没有考虑文档存在的稀疏性问题,导致文档语言模型估计不够准确;与QLM-smooth(Content+Interact)相比,QLM-prior-smooth(Content+Interact)利用用户兴趣改进了文档的先验概率,使得符合用户兴趣的微博可以获得较高的排名。
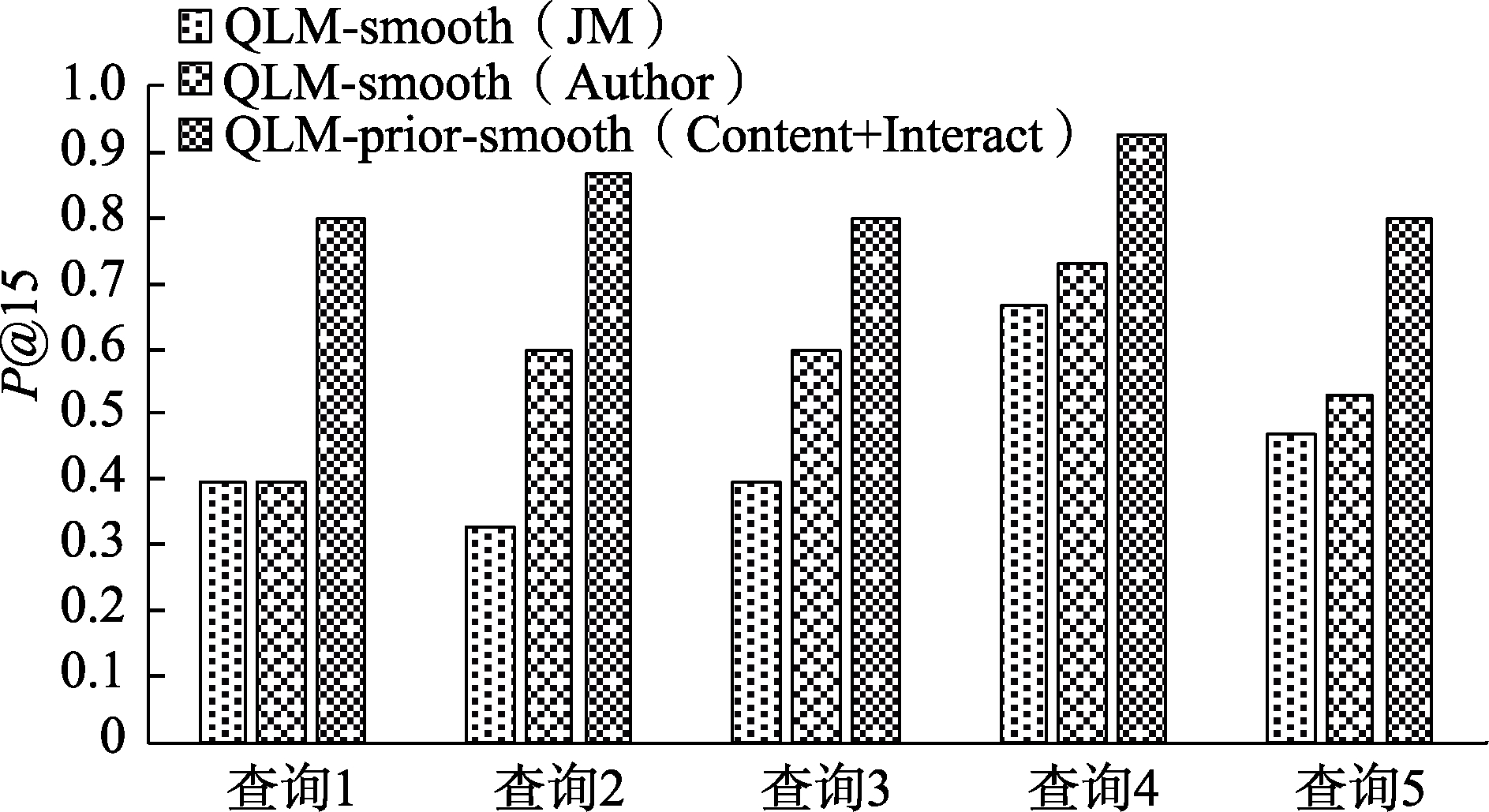
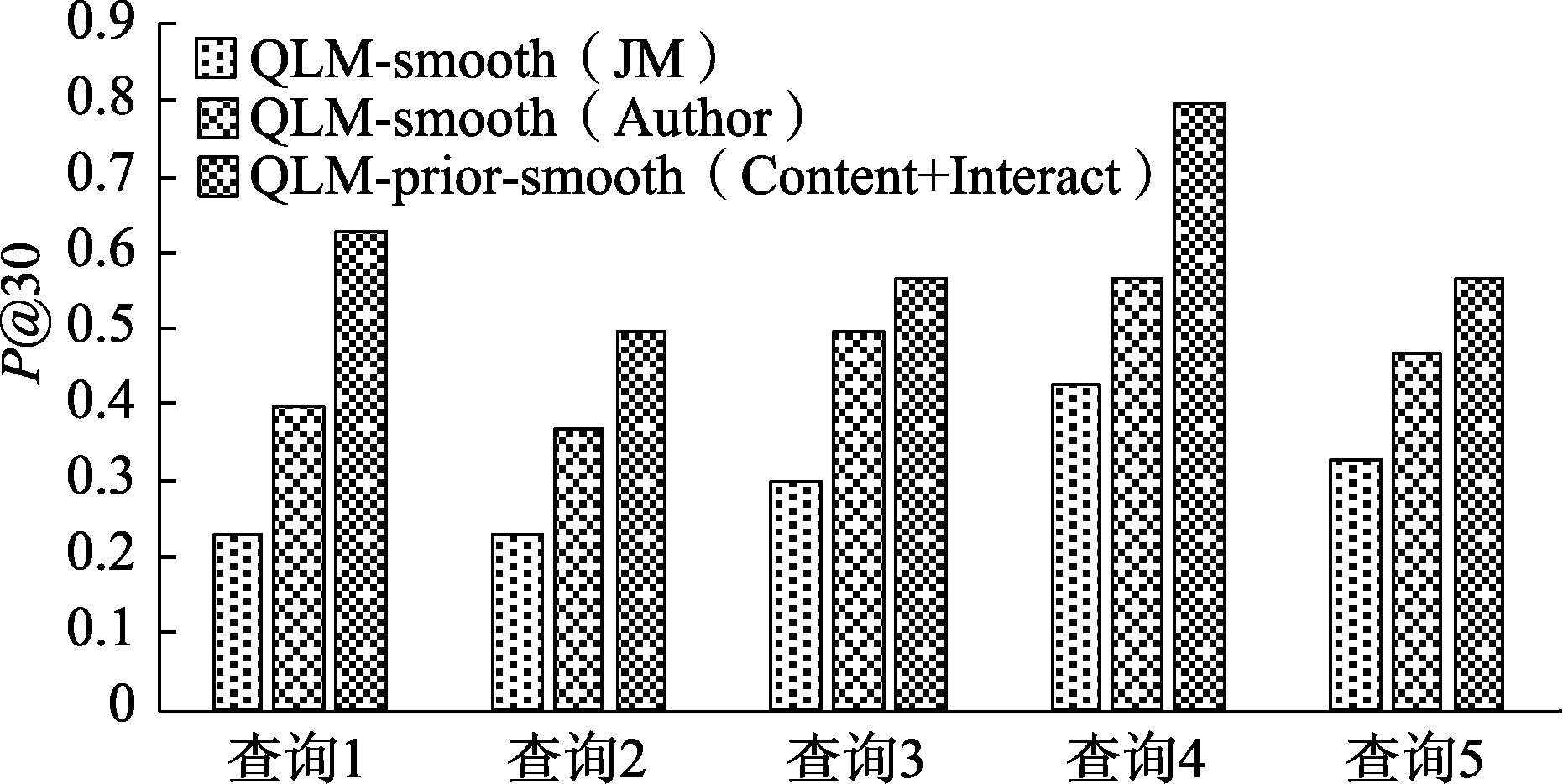
5.3.3 QLM-smooth(JM)、QLM-smooth(Author)、QLM-prior-smooth(Content+Interact)检索性能比较
在上述实验的基础上,实验将本文提出的微博检索模型QLM-prior-smooth(Content+Interact)与目前应用较为广泛的2种改进的查询似然模型QLM-smooth(JM)和QLM-smooth(Author)进行性能比较。
1)查准率比较
为比较3个模型的查准率,实验同样计算了5个查询在这3个模型上的
2)相关文档排名比较
为验证相关文档在检索结果中的排名,实验依据QLM-prior-smooth(Content+Interact)、QLM-smooth(JM)、QLM- smooth(Author)的前5条相关文档的排名和平均MRR来比较3个模型的性能,实验结果如表7所示。
表7 3个模型的MRR值
MRR 模型 QLM-smooth(JM) QLM-smooth(Author) QLM-prior-smooth(Content+Interact) MRR-1 1.00 1.00 1.00 MRR-2 0.45 0.40 0.50 MRR-3 0.21 0.19 0.33 MRR-4 0.13 0.13 0.25 MRR-5 0.11 0.11 0.19 平均MRR 0.38 0.37 0.45 从表7中可以看出,除3个模型的MRR-1相等外,QLM-prior-smooth(Content+Interact)的MRR-2、MRR-3、MRR-4、MRR-5和平均MRR均高于QLM-smooth(JM)和QLM-smooth(Author)。这说明3个模型中,QLM-prior-smooth(Content+Interact)的相关文档在检索结果中的排名更靠前。
综上所述,QLM-prior-smooth(Content+Interact)在查准率和MRR 2个方面均优于其余2个模型,产生这个结果的原因是因为QLM-prior-smooth(Content+Interact)在文档先验概率计算中融合了检索用户兴趣,而其余2个模型均假设文档先验概率相等,忽略了用户兴趣对文档先验概率的影响。此外,QLM-prior-smooth(Content+Interact)中文档语言模型估计有效利用了相关微博集对微博文档进行平滑,具有较少的噪声信息;而QLM-smooth(JM)中文档语言模型估计时采用全局信息对微博文档进行平滑,会引入较多的噪声;QLM-smooth(Author)虽采用同一作者的微博集对微博文档进行平滑,但同属一个作者的微博相关度有限,故也有一定量的噪声引入。
6 结束语
考虑到微博检索的特殊性,论文从两方面对传统查询似然模型进行改进,提出一个基于用户兴趣和混合估计的微博检索模型。该模型通过融入用户兴趣,给出了基于用户兴趣的先验概率计算;通过混合内容和用户交互两方面信息,实现了对微博文档的混合估计。本研究虽然可提高微博检索的性能,但尚有不足之处,未来研究中我们将围绕以下内容展开深入研究:①本文工作针对的是离线形式的微博数据,而实际微博数据是以数据流的形式实时更新的,故未来研究中我们拟结合在线学习思想,挖掘流数据的特征,实现对微博查询似然模型的深入改进,强化查询似然模型在微博检索中的应用。②完善实验数据,采用数据挖掘及数据分析技术,获得用户对博文的各种兴趣行为及用户间的交互行为,提高本文构建的小型数据集的通用性。
参考文献
- 1
微博数据中心. 2017年微博用户发展报告[EB/OL]. [2017-12-25]. http://www.useit. com.cn/thread-17562-1-1.html.
- 2
Teevan J, Ramage D, Morris M R. TwitterSearch: A comparison of microblog search and web search[C]// Proceedings of the Fourth International Conference on Web Search and Data Mining. New York: ACM Press, 2011: 35-44.
- 3
卫冰洁, 王斌. 面向微博搜索的时间感知的混合语言模型[J]. 计算机学报, 2014, 37(1): 229-237.
- 4
Liang S S, de Rijke M. Burst-aware data fusion for microblog search[J]. Information Processing & Management, 2015, 51(2): 89-113.
- 5
Li S, Ning H, Han Z Y, et al. A method for microblog search by adjusting the language model with time[C]// Proceedings of the Eighth International Conference on Internet Computing for Science and Engineering. IEEE, 2016: 25-28.
- 6
叶施仁, 严水歌, 杨长春. 基于VSM和LSA的微博搜索排序方法研究[J]. 情报科学, 2015, 33(7): 98-101, 112.
- 7
Jiang Y C, Xu Y X, Shao L. A personalized microblog search model considering user-author relationship[C]// Proceedings of the First International Conference on Data Science in Cyberspace. IEEE, 2016: 508-513.
- 8
卫冰洁, 史亮, 王斌. 一种融合聚类和时间信息的微博排序新方法[J]. 中文信息学报, 2015, 29(3): 177-183.
- 9
李锐, 王斌. 一种基于作者建模的微博检索模型[J]. 中文信息学报, 2014, 28(2): 136-143.
- 10
Tommasel A, Godoy D. A social-aware online short-text feature selection technique for social media[J]. Information Fusion, 2018, 40: 1-17.
- 11
Ponte J M, Croft W B. A language modeling approach to information retrieval[C]// Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 1998: 275-281.
- 12
Zhai C. A study of smoothing methods for language models applied to information retrieval[J]. ACM Transactions on Information Systems, 2004, 22(2): 179-214.
- 13
Choi J, Croft W B. Temporal models for microblogs[C]// Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM Press, 2012: 2491-2494.
- 14
Li X Y, Croft W B. Time-based language models[C]// Proceedings of the 12th International Conference on Information and Knowledge Management. New York: ACM Press, 2003: 469-475.
- 15
Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1974, 18(11): 613-620.
- 16
Joachims T. A probabilistic analysis of the rocchio algorithm with TF-IDF for text categorization[C]// Proceedings of the Fourteenth International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers, 1996: 143-151.
- 17
Lin J, Mohammed S, Sequiera R, et al. Overview of the TREC 2016 real-time summarization track[C]// Proceedings of the 25th Text Retrieval Conference, Boston, USA, 2016: 38-44.
- 18
徐建民, 王平. 小型中文信息检索测试集的构建与分析[J]. 情报杂志, 2009, 28(1): 13-16.
- 19
Cormack G V, Palmer C R, Clarke L A. Efficient construction of large test collections[C]// Proceedings of International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 1998: 282-289.
- 20
Wang Y S, Huang H Y, Feng C. Query expansion based on a feedback concept model for microblog retrieval[C]// Proceedings of the 26th International Conference on World Wide Web. Geneva: International World Wide Web Conferences Steering Committee, 2017: 559-568.
- 21
陈杰, 刘学军, 李斌, 等. 一种基于用户动态兴趣和社交网络的微博推荐方法[J]. 电子学报, 2017, 45(4): 898-905.
- 22
韩中元, 杨沐昀, 孔蕾蕾, 等. 基于词汇时间分布的微博查询扩展[J]. 计算机学报, 2016, 39(10): 2031-2044.
- 23
Bertsimas D, Gupta V, Kallus N. Data-driven robust optimization[J]. Mathematical Programming, 2018, 167(2): 235-292.
- 1
摘要
随着移动互联技术的进一步发展,微博检索已成为微博服务的重要组成部分。考虑到微博检索与传统文本检索的不同,提出一个改进的微博检索模型。新模型对传统查询似然模型中的文档先验概率和文档语言模型估计进行了改进。在文档先验概率方面,通过量化用户对博文的兴趣获得用户的兴趣博文库,并在兴趣博文库的基础上计算微博先验概率,使得符合检索用户兴趣的微博具有较高的先验概率;在文档语言模型估计方面,混合内容及用户交互两方面信息获得微博的相关文档集,并将其作为平滑项实现对微博文档语言模型的混合估计,有效缓解了微博短文本的数据稀疏问题。实验采用从新浪微博爬取的真实数据对研究内容的有效性进行验证,结果表明与现有研究中较好的改进查询似然模型相比,新模型在P@15、P@30和MRR上均有一定提高。
Abstract
With the further development of mobile internet technology, microblog retrieval has become an important part of microblog service. Considering the difference between microblog retrieval and traditional text retrieval, a new microblog retrieval model is put forward. The new model improves the prior probability and document language model estimation of the query likelihood model. To improve the document prior probability, the user’s interest blog library is obtained by quantifying the interest of users in blogs, and then the prior probability of microblog document is computed based on the proposed interest blog library. On the other hand, the information of blog contents and user interaction are mixed to obtain related blogs, which are used to smooth the original blog and achieve the mixed estimation on document language model, to effectively solve the problem of data sparseness in microblog short text. Experiments adopt the real data crawled from Sina to verify the effectiveness of our model, and experimental results demonstrate that our model outperforms some state-of-the-art models on P@15, P@30, and MRR.