1 引 言
我国自2000年起专利申请数量持续增长,2011年超过美国成为世界上受理发明专利申请最多的国
家[1] 。然而,“多而不优”的问题持续存在。例如,三方授权专利占比较低;在光学、发动机、半导体、医学技术等重要技术领域,维持10年以上的有效发明专利,国外在华专利拥有量是国内的1.9倍[2,3] 。上述变化使得对中国专利政策的讨论从促进增长转移到质量提升。国内学者以定性定量相结合的方法分析专利数量激增、专利质量低下的原因,提出从全面资助到重点培育、数量考核到质量考核的治理对
策[4,5] 。2015年12月国务院发布了《关于新形势下加快知识产权强国建设的若干意见》,明确提出要“实施专利质量提升工程,培育一批核心专利”。2016年年底,国家再次出台的《“十三五”国家知识产权保护和运用规划》将“专利质量提升工程”作为四大工程之一,进一步提出,要完善专利评估机制,尤其要高度重视提升评估工作的前瞻性。目前,对于专利质量的研究集中在两方面:第一,基于专利信息搭建测度指标。例如,张古鹏
等[6] 认为专利的宽度和深度反映了技术的复杂度特征;宋河发等[7] 从发明创造质量、文件撰写质量、审查质量和经济质量四个方面构建了专利质量测度指标体系;杨思思等[8] 则选取了市场应用情况、专利申请规模等七个指标分析生物领域专利的经济价值;李瑞茜[9] 等采用社会网络分析方法,对基于专利共类的关键技术进行识别。另一方面,学者们运用计量模型寻找影响专利质量的显著因素。例如,生存分析模型对专利续费的研究,逻辑回归模型对专利寿命、专利无效宣告的研究等[10,11,12,13] 。截至2016年,我国现存的有效专利(patent in force)已达116万件,并且每年受理超过50万件的专利申
请[14] 。专利申请和授权数量的快速增长,也为专利质量预测等实证分析提供了海量的数据样本资源。然而,传统的统计分析和计量模型并不能充分利用专利数据样本海量、实时更新的优势,无法处理专利特征与专利质量更为复杂的关系和结构[15] 。在此背景下,本文以2010—2011年国家知识产权局受理的近86万件专利申请为样本,提取相关专利信息和引文信息,搭建完整的机器学习模型对专利质量的重要指标之一——后续引证数量进行预测。2 专利特征变量选取与描述
2.1 样本选取
本文的研究数据来自于欧洲专利局(EPO)全球专利统计数据库PATSTAT (2017年秋版)。该数据库包括了全球范围内专利审查机构的原始专利数据(主要来自专利文献著录项目数据库DOCDB)、法律状态数据、在线扩展数据等,涉及的专利信息包括专利申请、公开、申请人、发明人、引文、专利家族、技术分类和优先权信息等。与多个权威专利数据库,如OECD申请人名数据库(HAN)、OECD三方专利家族数据库、NACE-IPC索引等兼容并保持同步更新。已被OECD等机构发布的中国专利相关分析报告广泛使
用[16,17] 。本文选取2010—2011年国家知识产权局所受理的发明专利申请为样本,共获得完整信息的专利数量为85.1250万。依据国家知识产权局发布的专利统计年报中显示,2010—2011年受理的专利申请数量总计91.7589万,数据完整度超过90%。
2.2 专利的后引次数与专利质量
本文选取专利的后引次数(forward citation)为最常用的专利质量评测指标之一,被认为能够有效反映相关专利对技术的影响力以及其经济社会质
量[7,18,19] 。专利申请自申请日满18个月后,如果初审合格,将进入公布程序。公布文档含有专利审查机构确认的先前引用专利信息。在专利统计数据库中,每一个专利的先前引证和后续被引专利的信息都可以被提取及统计,并持续更新。本文的样本专利集中于2010—2011年受理的专利申请,因此不存在由于时间因素导致被引数量出现偏差的情况[20] 。表1提供了后引专利数量的具体分布。可以看出,引用次数最少为0,最多达到179个后续引用,分布极为不均,偏斜度和峰值分别达到5.6以及114.6。其中,43.1%的专利并无接收到任何一个后续专利的引用,仅有1%左右的专利拥有超过13次以上的后续引用。考虑到数据分类分布的极度不平衡,会直接提升机器学习的效率和预测难度,本文根据后续引证专利的数量搭建了两组预测目标:
第一,是否被引用(FWD)。截止到2017年12月,该专利是否有收到后续专利引用。
第二,是否获得高引(FWD_Type)。该变量将后续引用次数分为三个数量级:FWD_Type=0,即无任何后续引用,约占样本数量的43.1%;FWD_Type=1,即含有1~4个后续引用,约占样本数量的46.53%;FWD_Type=2,即含有5个及以上后续引用,被定义为高引用,约占样本数量的10.43%。
2.3 专利特征变量
首先,本文选择了已有文献中常见的专利特征,其中包括:
技术保护范围(nIPC4)。即该专利所涉及的国际专利分类的特定4位IPC分类数量。在专利申请过程中,审查员会依据被保护专利的技术内容将其归为一个或多个技术类别。涉及的4位IPC分类越多,通常被认为该专利的潜在技术质量和市场广度越
高[18] 。同时,该专利涉及的IPC分类(IPC4)也将直接被作为特征变量纳入模型分析。同族专利数量(Family_Size)。同族专利的数量是基于统一优先权专利申请文档,在不同国家或地区多次申请、公布或批准的内容相同或基本相同的专利数量。同族专利的数量被认为能够直接反映出该专利受到保护的地域广度。由于专利申请及保护成本高昂,申请人只会对有质量的专利进行多处申请。在已有文献中,同族专利数量也被认为和专利质量呈显著正相
关[9,19] 。非专利文献的引用数量(nNPL)。非专利文献包括申请专利保护的技术所涉及的科技论文、会议资料、数据库以及其他相关文献。通常,非专利文献的引用数量越高,越能反映专利发明创造与科学知识联系的紧密度,体现出该技术较强的基础性知
识[21,22] 。合作专利(nApplicant/nInventor)。该指标反映专利的申请人或发明人数量。其中,nApplicant衡量的是专利申请文档中申请人的数量。nInventor衡量的是专利申请文档中发明人的数量。
优先权相关(Priority/Priority_Seq)。其中,优先权(Priority)为1,即该专利是在国家知识产权局提出第一次申请;反之,则该专利不是在国家知识产权局提出第一次申请。Priority_Seq是依据申请时间排序,指代国家知识产权局是该专利的第几申请地区。如果优先权为1,则意味着该专利在国家知识产权局提出第一次申请,Priority_Seq也为1。
授权与否 (Grant)。截止到数据搜集年份2017年底,如果该专利已经获得了授权决定,则该变量值为1;如果该专利尚未获得授权决定,该变量为0。值得说明的是,专利获得授权是专利有质量的基本条件。本文将授权与否纳入预测模型,并不是检测授权与否与专利质量的因果关系,而是探究其相关性,即专利获得授权这一信号,能否带来专利引用的增长。
专利申请年份(Filing Year)。专利文档申请的年份,在本样本中为2010年或2011年。
表2为样本专利的特征变量的基本统计描述,包括总样本专利、无后续引用专利子样本,至少有一个后续引用专利子样本的最小值、最大值、均值、方差,以及T检验比较是否存在显著差异。从表2中的数据可以看出,大部分专利质量相关的专利都显示出显著的差异,并且有后续引用的专利样本的均值高于无任何后续引用的专利子样本,如技术保护范围、非专利引用文献等,充分说明了所选特征变量与专利引用指标的高度相关性。值得注意的是,虽然有后续引用的专利子样本显示出较高的平均值,但对应的方差波动也较大,显示出高引用专利样本中存在较大的质量差异。总体上,三个指标在无后续引用的子样本中显示出较高的均值,包括同族专利数量(nFamily)、优先权专利(Priority)以及进入中国的申请顺序(Priority_Seq)。可以初步判断,这一结果是由于进入中国的外国专利的引用数量较少所导致。本文对专利后续引用数量的统计仅限于该中国专利申请的被引用情况,并不涉及其海外同族专利的被引用情况,因此,依据统计描述结果显示,专利审查机构在先前检索阶段可能存在对外国专利引用较少的可能性。
表2 特征变量统计描述
特征变量 总样本 无后续引用样本专利子样本 至少有一个后续引用专利子样本 T检验 均值 方差 均值 方差 均值 方差 技术保护范围(nIPC4) 1.49 0.80 1.45 0.79 1.52 0.80 -40.40 同族专利数量(Family_Size) 2.79 6.34 3.68 8.83 2.12 3.25 114.14 非专利文献引用(nNPL) 0.44 1.05 0.32 0.93 0.52 1.13 -88.60 申请人数量(nApplicant) 1.07 0.42 1.04 0.42 1.09 0.42 -46.41 发明人数量(nInvention) 2.98 2.39 2.62 2.20 3.25 2.50 -120.00 优先权相关(Priority) 0.06 0.23 0.05 0.22 0.06 0.23 -11.45 进入顺序(Priority_Seq) 0.28 0.45 0.38 0.49 0.20 0.40 186.11 授权与否 (Grant) 0.52 0.50 0.45 0.50 0.58 0.49 -110.00 2.4 基于引证专利的特征变量搭建
为了评估专利申请的新颖性,专利申请人及审查员需要进行全面的检索,公布申请专利保护的发明所依赖的相关技术知识,列出所依据的先前引证专利(backward citations)。然而,引证专利数量与专利质量的关系在已有的实证检验中存在一定的争论。一方面,从引证专利被添加的缘由来看,引证专利数量较少,一定程度上代表了申请专利的新颖
性[23] 。但也有文献指出,反向引用数量较多的专利更容易被后续专利引用,反而呈现出高质量特征[24] 。基于已有文献的实证结果,本文首先搭建了样本专利的引证专利数量(nBWD)。如表3所示,我国专利申请文档中,约10%的专利未含有引证信息。引证专利数量大部分集中在4~6个专利数之间。将专利的引证专利信息关联对应的专利引文数据库,获得引证专利的相关信息,本文搭建了引证专利的特征指标,具体解释如下。
授权引证专利(BWD_Grant)。即统计一个专利的引证专利中,有多少是获得授权的专利。专利获得授权是该专利质量的基本体现,因此,对授权引证专利的统计和全部引证专利的统计,更能反映出该专利和已有高质量专利之间的相关性。例如,专利A被检索出需要引用a、b、c三个专利,而只有专利a获得了授权,该专利的引证专利数量为3,但是授权引证专利记为1.
引证专利的时间间隔(BWD_Gap)。即统计一个专利的引证专利的申请年份与该专利申请年份(2010年)的总时间间隔。例如,专利A被检索出需要引用a、b、c三个专利,三个专利分别申请于2000年、2001年以及2008年,则该专利的专利引用文档的时间间隔为21年。
引证专利的同族专利数量(BWD_Family_Size)。即统计一个专利的引证专利的同族专利总数。例如,专利A被检索出需要引用a、b、c三个专利,三个专利分别含有1、10、100个同族专利时,该专利的引用文档的同族专利数量记为111个。由于同族专利数量在已有文献中经常作为专利质量的指代指标之一,因此,如果专利引用文档的同族数量较多,则证明该专利内容涉及了重要专利。
引证专利的被引证次数(BWD_FWD)。即统计一个专利的引证专利在该专利申请年份(2010年或2011年)已经被引用的总数。例如,专利A在2010年被受理申请,需要引用a、b、c三个专利,三个专利在2010年已经获得的后续引用次数分别为0、10、100个引用,该专利的引证专利的被引证数量记为110个。由于被引证次数为专利质量的直接反映,因此该指标也是对引证专利质量的有效评测。
表4为本文所新搭建的基于引证专利的特征变量的统计描述及T检验结果。从T检验结果来看,两组专利样本的均值都呈现出显著的差异性。但是,和表2中专利质量相关指标不同,无后续引用专利子样本中专利引证专利的质量指标均值都高于有后续引用专利的子样本。
表4 基于引证专利的特征变量统计描述
特征变量 总样本 无后续引用样本专利子样本 至少有一个后续引用专利子样本 T检验 均值 方差 均值 方差 均值 方差 引证专利数量(nBWD) 3.50 2.59 3.32 2.70 3.64 2.49 -57.84 授权引证专利数量(BWD_Grant) 3.01 1.88 3.09 1.90 2.96 1.86 29.00 引证专利的申请年份间隔(BWD_Gap) 2448.45 1482.33 2649.57 1523.19 2315.58 1439.37 91.81 引证专利的同族专利数(BWD_Family_Size) 3.00 3.45 3.46 3.96 2.69 3.03 91.28 引证专利的被引证数量(BWD_nFWD) 34.96 69.19 40.58 78.73 31.25 61.81 54.74 3 机器学习模型概述
3.1 随机森林模型基本概念
本文选用了机器学习中善于处理大样本数据的随机森林(random forest,RF)进行学习及预测。随机森林方法建立在决策树模型(Decision Tree,见图1)基础之上。决策树模型利用树形结构,把数据集按对应的类标签进行分类。例如,本文将专利样本数据集D分为两种类别的专利:无后续引用以及有后续引用。如图1所示,样本D中有后续专利引用的样本标志为√,无后续专利引用的样本标志为×。决策树模型的目标是通过特征判断,将样本归到对应的分类中去。
构建决策树时,模型选择样本数据的某个特征值作为树的节点。如图1所示,模型选择专利的技术保护范围(nIPC4)作为第一个节点。当技术保护范围大于该分界点,专利会被归类到左边的分支中进入下一个节点的判断;反之,专利会被归为右边的分支中。依据数据样本分类结果,计算机计算出专利样本数据D的信息熵,公式表达为
式中,pi表示类别i样本数量占所有样本的比例。
对应数据样本D,还需要决定特征A的分裂点。如图1中,第一个节点为技术保护范围(nIPC4)有一个分裂点,即样本专利会依据nIPC4的数量是大于3还是小于3被分类进入下一节点。假设特征A有k个分裂点,即样本专利D会被分为k个部分。对应数据集D,选择特征A作为节点时,在特征A之后的信息熵为
式中,信息增益
式中,Gain(A)最大时的特征A的分裂点取值,就是对于数据样本D在决策树节点A最合适的分类。
模型在样本专利训练数据集中,通过有放回的多次抽样产生N个子样本作为训练决策树用到的训练集。若输入的特征中有M个特征,可以通过设定m(<M)作为决策树生成过程中确定最佳分裂点时所涉及的特征数目。通过以上方式重复T次,可以生成T棵决策树。基于这T棵决策树的决策结果,利用基于多数投票机制测算出最优的分界点。
随机森林模型是对决策树模型的延展。计算机首先将样本专利随机产生N个子样本,对每一个子样本进行决策树模型的训练,找出最佳分割点。重复M次,产生M棵决策树。基于N个子样本的决策树模型结果,基于多数投票机制测算出最优的分界点。总体上,随机森林模型比单一的决策树模型预测的误差方差更
小[25] 。图1只作为模型举例说明,并不代表实际预测结果。图中,√表示样本中有后续引用的专利,×表示无后续引用的专利。通过特征分类,模型将大部分样本专利的归类做出了正确的判断。
3.2 随机森林模型的评估
和其他机器学习模型一样,随机森林算法包括训练和测试两个部分。计算机首先使用训练集(training set)选择最优的模型,再使用测试集(test set)来评估模型。本文采用常用的两种评估方法:一个是分类准确度(accuracy),其定义是:对于给定的测试数据集,正确分类的样本数量与总样本数之比。例如,模型识别出100个专利获得引用,实际只有80个获得引用,剩余20个并没有获得引用,即被错误分类,这种情况下,分类准确度为0.8。另一个模型评估指标为召回率(recall),即所有“正确被检索的结果”占“应该检索到的结果”的比例。例如,样本中总共有100个专利获得后续引用,模型识别出了99个,只有1个没有识别出,那么该模型的召回率为0.99。
计算机在使用训练集训练模型的过程中,可能出现过度拟合的现象,即训练样本达到非常高的逼近精度,但对检验样本的逼近误差随着训练次数而呈现出先下降后上升的现象。如图1所示,所用例子的决策树为三个层级,属于比较“浅”的决策树模型,当层级进一步扩大,决策树的深度增加,会出现过度分类的现象。本文使用采用了10、20、30以及60层级对模型进行调试。
除此之外,随机森林模型会选用基尼指数增益值作为决策树选择特征的依据。即
式中,pi表示类别i样本数量占所有样本的比例;对应数据集D,选择特征A作为决策树判断节点,k表示特征A的分裂点数量。如图1所示,在所有的特征中,技术保护范围(nIPC4)的ΔGini最大,因此被作为决策树的第一个节点。
3.3 小结:机器学习模型相对计量回归模型的优势
随着机器学习技术的不断发展,机器学习模型越来越多地运用到经济学、管理学的实证检验中,国内外已有学者对此进行了总结分
析[14,26] 。总体上,对于专利质量的预测,机器学习模型的优势体现在以下两个方面:第一,机器学习模型由于强大的计算能力,对于数据特征以及特征之间的关系给予更多变的假设,依据最优预测模型推导出变量之间更复杂的关系,对经济管理理论进行补充。例如,已有文献中,理论假设专利的引用专利数量(nBWD)对专利质量成线性正相关,当统计检验无法通过时,其线性正相关的假设被拒绝。而在机器学习中,计算机可以进一步检验引用专利数量与专利后续引用之间更复杂的非线性关系,以及引用专利数量、同族专利数量等不同专利特征之间对专利质量的共同作用。除此之外,如本文所采用的随机森林模型对特征变量的基尼指数增益值的计算,不仅能检验特征变量与专利质量之前的相关性,同时能对特征变量对专利质量的重要性进行排序。
第二,线性相关问题。计量模型中,最小二乘回归法会选择一条唯一的回归线,满足数据集的整体残差平方和达到最小值。越来越多的模型被不断加入自变量参数。而自变量之间的线性相关会导致模型参数估计得不稳定或不易解
释[27] 。如表5所示,本文所采用的专利特征变量之间,如引证专利数量 (nBWD)和引证专利的其他特征之间存在明显的线性相关。对此,机器学习模型的正则化思想能够解决自变量相关问题,即在参数估计的目标优化方程中加入涉及模型复杂度的惩罚项,避免预测模型的过度拟合,并且提高模型预测的准确度。表5 特征变量相关性
1 2 3 4 5 6 7 8 9 10 11 12 1. nIPC4 1.0 2. Family_Size 0.1 1.0 3. nNPL 0.1 -0.1 1.0 4. nApplicants 0.0 0.0 0.0 1.0 5. nInventors 0.0 0.0 0.1 0.2 1.0 6. Priority 0.0 0.1 0.0 0.0 0.0 1.0 7. Priority_Seq 0.1 0.6 -0.2 -0.1 -0.1 -0.1 1.0 8. nBWD -0.1 0.1 -0.2 0.0 -0.1 0.0 0.1 1.0 9. BWD_Gap 0.0 0.1 -0.1 0.0 0.0 -0.1 0.2 0.2 1.0 10. BWD_Grant -0.1 0.0 -0.2 0.0 -0.1 0.0 0.0 0.8 0.2 1.0 11. BWD_Family_Size 0.1 0.4 0.0 0.0 0.0 0.0 0.3 0.0 0.1 -0.1 1.0 12. BWD_nFWD 0.0 0.2 -0.1 0.0 0.0 0.0 0.3 0.3 0.2 0.2 0.2 1.0 4 实证结果
4.1 随机森林预测结果
本文首先将85.1250万个样本数据随机分为训练集和测试集两部分,分别占比70%以及30%。表6显示了对2010—2011年国家知识产权局受理的85万专利申请的质量预测结果。首先,表6左半部分对是否获得后续引用(FWD)进行了预测,第二部分依据后续引用数量的三个层级(FWD_Type)进行预测。整体上,决策树深度的增长虽然能够显著提升训练集内样本的拟合度,但是对于测试样本的预测,因为过度拟合而产生错误的判断,从而导致预测准确率的下降。整体上,基于本文的专利样本,10层级决策树模型是最优结果,对测试集的预测准确率为0.57,基本上能预测出全部的有后续专利引用的情况。但是,如同表6右半部分结果所显示的,模型对于FWD_Type的预测能力较弱,尤其是对于后引数量大于4的FWD_Type=2的高质量专利的预测。本文第5节将对进一步提高专利质量预测模型提出具体意见。
4.2 变量特征解读
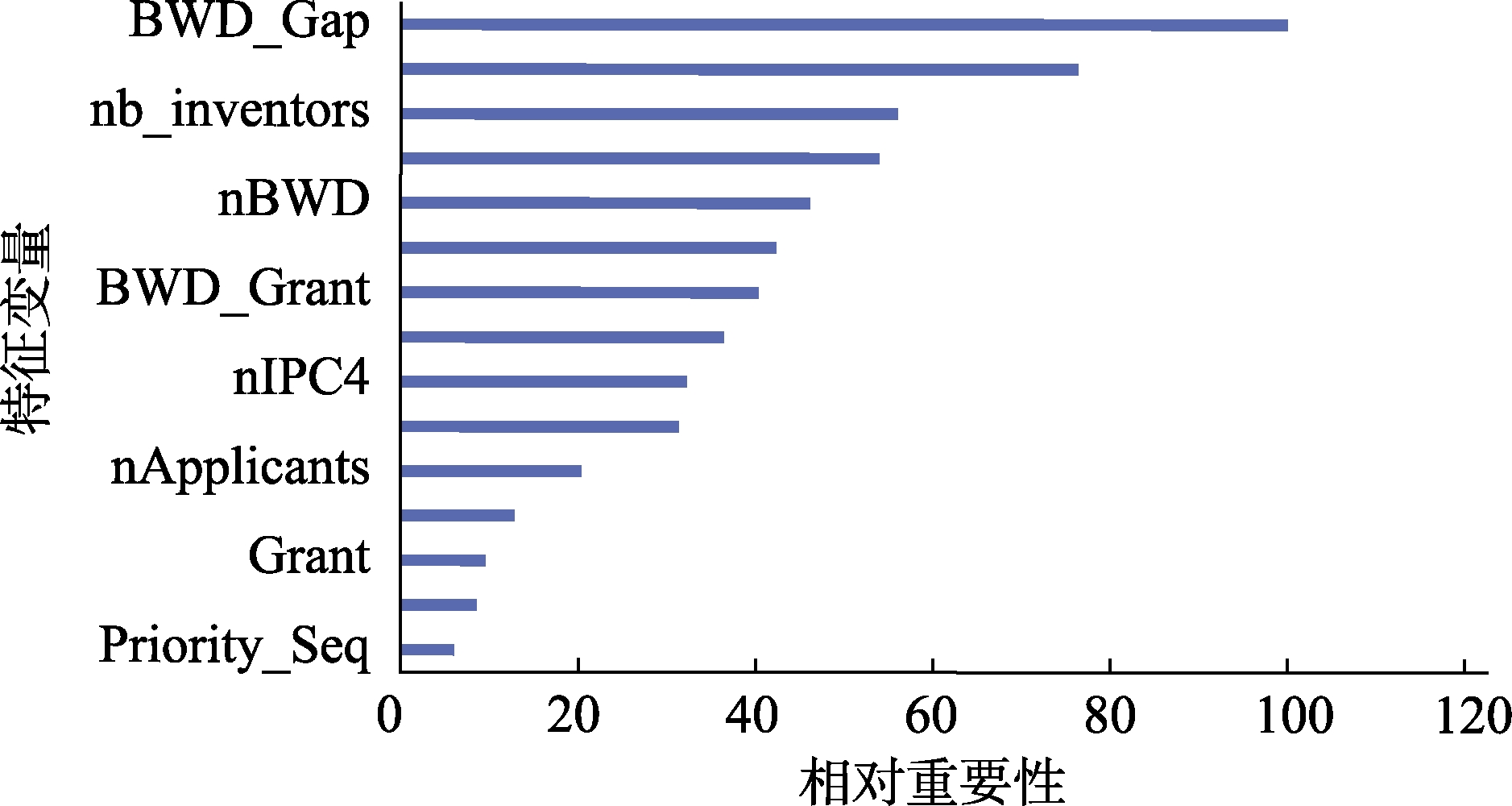
基于随机森林的计算原理,模型能够对本文所采用的特征变量与专利质量之间的相关性进行具体计算并排序。如图2所示,柱状图的长度代表了该变量对于获得专利引用的重要性程度。首先,常见的专利特征变量,如同族专利数量(Family_Size)技术保护范围(nIPC4)申请人或发明人人数(nApplicants/nInventors)尽管在描述统计的T检验中具有显著性,但并没有显示出足够的预测能力。其次,本文所构建的基于前引专利特征的特征变量,如先前引证专利的时间间隔(BWD_Gap)、先前引证专利本身的同族专利数量(BWD_Family_Size)、先前引证专利的后续引证次数(BWD_FWD)对于专利质量的预测显示出较高的相关性。该结论进一步体现了专利审查中对于先前引文(Prior Art)检索工作的重要性。它不仅直接影响到审查员对于专利新颖性的判断,也直接影响后续专利对相关专利质量的判断。不过,机器学习对于先前引证专利的特征与专利质量之间所搭建的非线性关系非常复杂,我们无法对前引专利特征与专利质量之间的正负效应做出判断。
除此之外,考虑到前引专利的相关特征,样本中约10%的专利并未有任何前引专利,将直接提升模型对其特征的抓取难度和预测难度。因此,表7罗列了前引专利数量对于模型对测试集专利进行预测的准确率分布。如表7所示,在测试集中,未含有任何前引专利的样本其后引次数,以及模型的预测准确率都明显低于其他样本专利。换言之,如果一个专利申请未含有任何前引专利,虽然体现了其高度新颖性,但是其质量具有更大的不确定性。其后引次数可能较低,并且较难被预测。
5 研究结论和建议
本文利用欧洲专利局PATSTAT专利数据库以及引文数据库,基于技术保护范围、同族专利数量等专利基本特征,以及基于向前引证专利所搭建的相关特征指标,提出了完整的随机森林模型对专利的后引情况的预测模型,提供了机器学习技术在专利管理及技术预测领域的初步尝试。
依据随机森林模型提供的变量特征重要性排序,本文所构建的基于前引专利的特征变量对专利质量预测显示出更强的解释能力。首先,该结论进一步反映了专利审查中对先前专利检索工作的重要性。检索工作的全面性、准确性不仅影响到对专利申请的新颖性的判断,也会影响到后期对相关专利质量的判断。除此之外,在我国现有的专利申请过程中,先前专利的检索工作由审查员全权执行,审查员会将专利申请与先前相关专利的内容进行对比,判断该专利申请的可专利性。通常,当先前专利数量较多时,审查员将具有更充足的信息,对新的专利申请的可专利性判断可能更为严格。因此,当申请人没有义务提供先前专利信息时,更多的申请人不会主动提交相关专利信息。然而,本文的预测结果显示,专利文档中涉及的引证专利特征会直接影响到后续专利引用的概率。申请人应意识到在专利申请文档中是否提交在先引用信息,将可能是提高后续专利对相关专利质量判断的策略之一。
不过,本文搭建的机器学习模型对于专利质量的预测尚有一定的局限性,主要存在于三个方面:第一,我国目前专利的“多而不优”的整体现状在样本的特征变量中得以充分体现,近一半的样本专利未获得一个后续专利引用,而超过5个后引次数的专利占比只有不足1%。专利质量的普遍低下直接影响到样本的特征分析和预测难度。随着我国专利质量政策的推动,专利质量的普遍提升也将提高专利质量的可预测性。第二,本文选取的分析样本为2010年申请的专利文档。该样本区间的优势在于能够反映当下的专利质量问题,但局限性在于模型只能学习到样本专利申请8年内的后引情况。随着时间的推移,该模型可以持续更新,对样本专利的后续被引用情况进行重复学习,以提升模型的预测能力。同时,随着样本专利后续引用数量的增长,模型的预测问题可以延展到阶段性预测,即对专利申请五年内、十年内、十五年内的引用情况分别进行学习和预测。第三,寻找专利数据的特征是提高预测准确度的重要因素。然而,由于数据的可获得性,本文的变量搭建仅限于专利申请文档中的基本信息以及相关引文信息,并没有涉及专利申请人、专利所涉及的产业的经济活动等信息。未来,企业信息以及经济信息与专利申请信息得到进一步匹配后,机器学习对于专利质量的预测将有更多提升空间。
参考文献
- 1
世界知识产权组织(WIPO). 2011年世界知识产权指标[R/OL]. 2011. https://www.wipo.int/publications/en/details.jsp?id=236& plang=EN.
- 2
Thomson Reuters. China s IQ (innovation quotient)-trends in patenting and the globalization of Chinese innovation[R/OL]. 2014. https://www.rouse.com/magazine/news/chinas-iq-innovation- quotient-trends-in-patenting-and-the-globalization-of-chinese-
innovation/.
- 3
裴宏, 吴艳. 实施专利质量提升工程加快建设知识产区强国[N/OL]. 知识产权报, 2017, http://www.sipo.gov.cn/zscqgz/1101209.html.
- 4
郭俊华, 杨晓颖. 专利资助政策的评估及改进策略研究——以上海市为例[J]. 科学学研究, 2010, 28(1): 17-25.
- 5
龙小宁, 王俊. 中国专利激增的动因及其质量效应[J]. 世界经济, 2015(6): 115-142.
- 6
张古鹏, 陈向东, 杜华东. 中国区域创新质量不平等研究[J]. 科学学研究, 2011, 29(11): 1709-1719.
- 7
宋河发, 穆荣平, 陈芳, 等. 基于中国发明专利数据的专利质量测度研究.[J]. 科研管理, 2014, 35 (11): 68-76.
- 8
杨思思, 戴磊, 郝屹. 专利经济价值度通用评估方法研究[J]. 情报学报, 2018, 37(1): 52-60.
- 9
李瑞茜, 陈向东. 基于专利共类的关键技术识别及技术发展模式研究[J]. 情报学报, 2018, 37(5): 495-502.
- 10
郑贵忠, 刘金兰. 基于生存分析的专利有效模型研究[J]. 科学学研究, 2010, 28(11): 1677-1682.
- 11
乔永忠. 专利维持时间影响因素研究[J]. 科研管理, 2011, 32(7): 143-149.
- 12
肖冰. 基于法定保护期的专利维持时间影响因素研究[J]. 科学学研究, 2017, 35(11): 1652-1658.
- 13
刘佩佩, 袁红梅. 专利权无效宣告结果的影响因素探讨——基于药物专利属性的实证研究[J]. 情报学报, 2017, 36(4): 392-400.
- 14
李华杰, 史丹, 马丽梅. 基于大数据方法的经济研究: 前沿进展与研究综述[J]. 经济学家, 2018(6): 96-104.
- 15
国家知识产权局.《2016专利统计年报》[R]. 2016.
- 16
Squicciarini M, Dernis H, Criscuolo C. Measuring patent quality[R]. OECD, 2013.
- 17
Boeing P, Mueller E. Measuring patent quality in cross-country comparison[J]. Economics Letters, 2016, 149: 145-147.
- 18
Lerner J. The importance of patent scope: An empirical analysis[J]. The RAND Journal of Economics, 1994, 25(2): 319-333.
- 19
郑素丽, 宋明顺. 专利质量由何决定?——基于文献综述的整合性框架[J]. 科学学研究, 2012, 30(9): 1316-1323.
- 20
Harhoff D, Narin F, Scherer F M, et al. Citation frequency and the value of patented inventions[J]. Review of Economics and statistics, 1999, 81(3): 511-515.
- 21
Narin F, Hamilton K S, Olivastro D. The increasing linkage between US technology and public science[J]. Research Policy, 1997, 26(3): 317-330.
- 22
Cassiman B, Veugelers R, Zuniga P. In search of performance effects of (in) direct industry science links[J]. Industrial and Corporate Change, 2008, 17(4): 611-646.
- 23
Harhoff D, Scherer F M, Vopel K. Citations, family size, opposition and the value of patent rights[J]. Research Policy, 2003, 32(8): 1343-1363.
- 24
Van Zeebroeck N. The puzzle of patent value indicators[J]. Economics of Innovation and New Technology, 2011, 20(1): 33-62.
- 25
Hastie T, Tibshirani R, Friedman J. Unsupervised learning[M]// The elements of statistical learning. New York: Springer, 2009.
- 26
Mullainathan S, Spiess J. Machine learning: an applied econometric approach[J]. Journal of Economic Perspectives, 2017, 31(2): 87-106.
- 27
Wooldridge J M. Introductory econometrics: A modern approach[M]. Beijing: Tsinghua University Press, 2014.
- 1
摘要
随着专利数量的迅速增长,如何预测专利质量,已成为企业、政府以及学术界越发关注的问题。传统的统计分析方法虽然对专利质量评估进行了多方面探索,却较少对专利质量进行预测,尤其是充分利用到专利数据的海量样本和持续更新的优势。本文以2010—2011年国家知识产权局受理的共计85万余件专利申请为研究对象,抓取申请文档中以及相关引文的特征信息,搭建完整的随机森林模型,对后续被引情况进行机器学习及预测。除此之外,随机森林对特征重要性的评估结果显示,专利的向前引证专利的特征比该专利本身的特征对后续引证的预测提供了更多有效信息,进一步显示出专利审查中对前引专利检索工作的重要性。同时,文章结尾指出了本文模型的局限性以及今后借助机器学习对专利预测的改进方法。
Abstract
As the number of patent applications in CNIPA (China National Intellectual Property Administration) increases, patent value is of great interest throughout industries, governments, and academies. However, the existing statistic and econometric models cannot take advantage of huge samples of patent data for value prediction. Based on more than 850,000 patent applications field in 2010 and 2011, this paper provides a machine learning approach to predict patent forward citations at an early stage by using multiple patent indicators that can be defined immediately after the relevant patents are public. The developed model could provide a prediction on whether the relevant patent would receive forward citations; however it was weak in differentiating between high and low citations. Moreover, based on the Gini impurity, features of backward citations provide more information for value prediction. In other words, the prior art search process during the patent examination should be focused on. Finally, the paper discusses the limitations of the adopted model, as well as improvement methods for further studies.