- 摘要Abstract

- 关键词Keywords
-
1 引 言
-
2 文摘特征句语义识别与分类算法
-
2.1 研究背景介绍
-
2.2 句子语义识别与分类算法步骤
-
2.3 特征动词语义识别算法获得的结果
-
2.4 科技文摘6分类算法的结果
-
3 分类算法的数据统计分析
-
3.1 分类算法的数据统计结果
-
3.2 科技文摘6类句型总体数量分布图
-
3.3 科技文摘三大类型句分析
-
3.4 单一类型句分析
-
4 单一非规范句型语义结构分析
-
4.1 单一非规范句型语义结构分析
-
4.2 单一非规范句语义结构分析结论
-
5 混合类型句的语义结构分析
-
5.1 混合类型句语义结构分析
-
5.2 从第4、6类中分离出第1、2类
-
5.3 从第5、6类中分离出第2类
-
6 解决方案与评价
-
6.1 解决方案
-
6.2 分类效果评价
- 参考文献
1 引 言
科学引文索引(Science Citation Index,SCI)是利用文献的引用和被引用关系建立起来的一种新型索引,它揭示了文献之间的引证关系。引文索引既可以用于进行多种类型的检索,也成为评价核心期刊、核心出版社,评价科学家、科学团体以及国家的科研能力与水平的工
具[1] 。实际上文献中不同功能类型的引用对文献的贡献是不同的,学者们将SCI引用功能分为5个等级和10个类别[2,3] 。5个等级分别为:①非常不重要(背景、事实);②不重要(扩展阅读);③一般(概念、定义);④重要(观点、结论、数据);⑤非常重要(方法、相关研究)。袁慧等[4] 证实了引用“相关研究和方法”这两类引用功能约占全部引用的18%。由于SCI只是文献层面的引证,还不是文献内容细节的引证,因此,很难从引文索引中佐证其引文的真实性,不可避免地存在着虚假性和炫耀性等不易辨别等缺陷。随着传统的引文分析方法受到学者的质疑,陆伟教授等[5] 开始尝试采用引文内容分析的方法以解决上述问题。近年来,大数据带给科技人员信息检索的压力已不再是当年SCI解决多渠道信息获取的问题,而是如何高效率地获取能直接启发科研创新点的新问题、新方法、新结果的文献内容知识深度服务问题。显然,SCI难以满足科研工作者知识服务的深度需求。为此,文献信息服务业和学术文献出版业提出了知识服务的观念[6] ,开展寻找出版企业如何打开知识服务大门的正确方式[7] 。张晓林教授[8] 对信息服务和知识服务做了全面而深刻的研究,认为知识服务之所以不同于传统的信息服务,知识服务是用户目标驱动的服务,它关注的焦点和最后的评价不是“我是否提供了您需要的信息”,而是“通过我的服务是否解决了您的问题”;明确强调,传统的信息服务基点、重点和终点则是信息资源的获取。为实现知识服务的目标,图书情报学领域的学者开始探讨人工智能(AI)在知识服务中的应用。认为AI时代,知识服务明显的特征是不再局限于提供基本的信息服务,更重要的基于场景为用户解决问题,并进一步满足潜在需求。强调关于AI的知识服务应用,必须以问题为中心[9] 。化柏林博士[10] 认为,论文中有很多方法知识元的描述,如何把这些方法知识元抽取出来,形成结构化的方法知识库,是细粒度知识组织的重要研究内容之一。科技文摘中提供了科学研究创新点的问题、方法、结果,为利用人工智能进行知识服务提供了可靠的事实数据。利用科技文摘创新点作为知识创新的引证方法,这将开启一种新的创新内容引证方法,它不仅有助于消除虚假引证的行为,还能通过创新点的关联性检验创新点的真实性,启发跨学科知识创新的借鉴性。可以预见,从科技文摘中提取表达创新点的“问题、方法、结果”事实知识,利用这些事实知识进行学术创新点的发现和学术创新点问答服务技术研究,将成为利用人工智能技术在科技学术文献大数据中应用的前沿研究领域。为此,我们研究科技文摘的创新点的语义识别与分类算法,为实现基于创新点引证的新方法,探索利用人工智能技术实现科技大数据知识推理和发现的技术基础。2 文摘特征句语义识别与分类算法
2.1 研究背景介绍
文献[11]对从北京万方数据有限公司获得的3410篇《计算机学报》文摘进行了语义动词的统计分析,统计结果给出了几个重要的结论:①从3410篇计算机学报文摘中得到动词92288个,平均每条文摘有27.06个动词;②每条文摘的句子数量没有固定数量,最多的有10句,最少的为3句;③动词的分布主要在前5句中,文摘的前4句的动词数量占总文摘动词数量的87.1%,文摘的前5句的动词数量占总文摘动词数量的94.3%;④文摘句中动词语义作用与句子位置的分布有一定关系。基于文献[11]的统计分析结果,为了寻找智能化的算法能把科技文摘分类为表达创新点的问题、方法、结果三类句子,我们随机选择《电子学报》文摘中每篇为4句话的文摘75条,共300个句子进行了动词的语义识别和自动分类的算法研究。选择有4句话文摘的理由有两方面,一方面考虑到后面会利用机器学习进行普遍性推广,另一方面考虑到识别率的人工检验工作量。软件开发工具采用Matlab。
2.2 句子语义识别与分类算法步骤
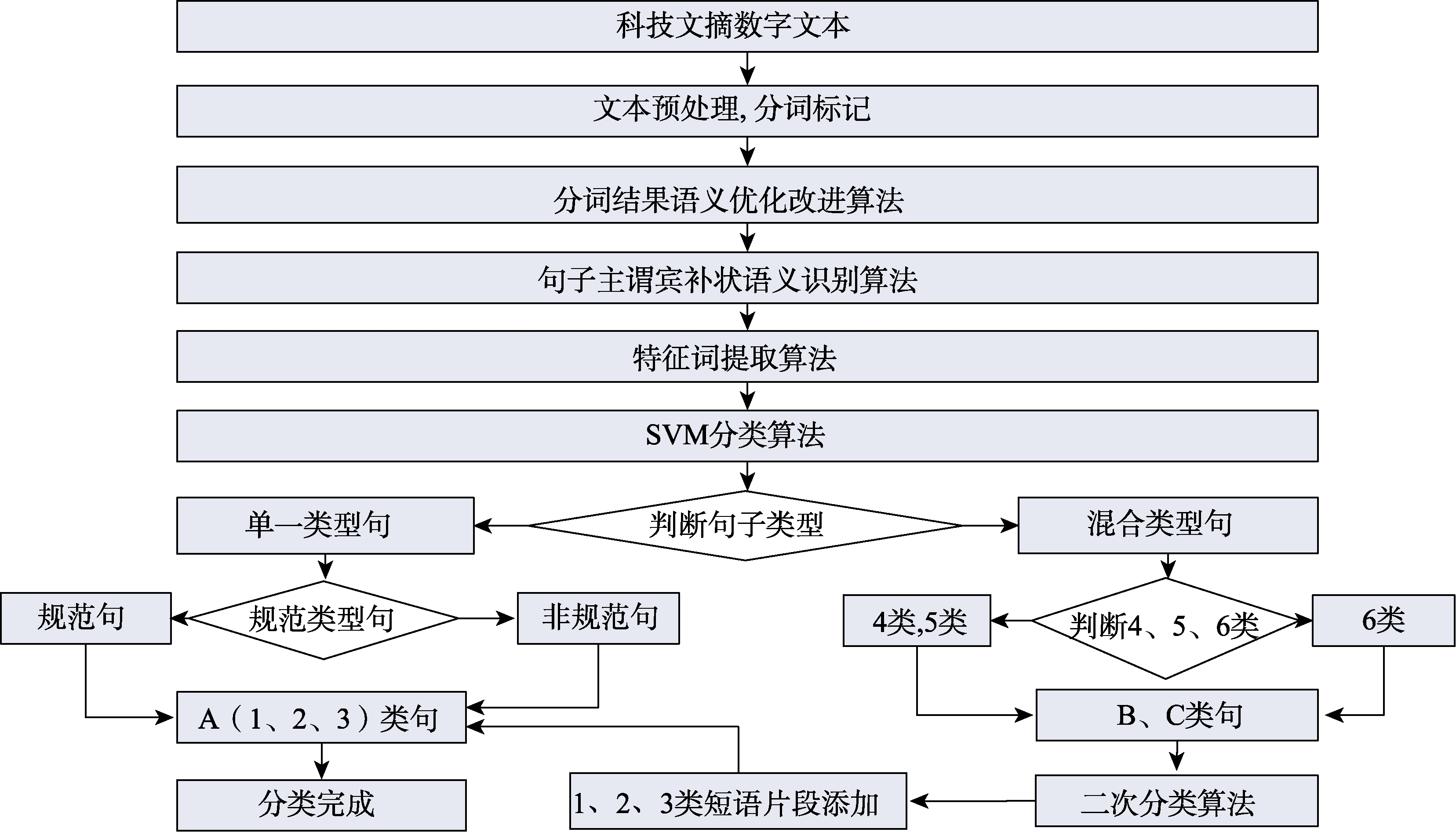
科技文摘句子语义识别与分类算法步骤由9个部分组成:①分词标记处理;②对分词标记后的句子进行了语义优化改进处理,使得有利于创新点特征句的机器识别;③句子主谓宾补状的语义识别算法;④特征动词自动提取算法;⑤判断句子是否单一句型,是否单一规范句;⑥判断句子是否是混合句型;⑦基于支持向量机(SVM)特征动词语义和句型进行6分类算法;⑧程序实现;⑨人工检验。算法流程如图1所示。
2.3 特征动词语义识别算法获得的结果
经过上述分词、分词优化改进、主谓宾补状识别、特征动词提取4个步骤后,得到的结果如表1所示。
表1 分类算法的4个过程结果
科技文摘句子实例 ICTCLAS50分词 分词优化改进 主谓宾补状识别 特征动词提取 20为减少无用数据包被缓存的概率,提出了一种基于历史信息的侦听管理策略,可有效减少干扰流对系统吞吐量的影响。 20/m 为/v 减少/v 无用/v 数据包/n 被/p 缓存/n 的/u 概率/n ,/w 提出/v 了/u 一/m 种/q 基于/p 历史信息/n 的/u 侦/v 听/v 管理策略/n,/w 可/v 有效/a 减少干扰/n 流/v 对/p 系统/n 吞吐量/n 的/u 影响/v。/w 20/m 为/p 减少无用数据包被缓存的概率/n,/w 提出了/v 一种基于历史信息的侦听管理策略/n,/w 可有效减少/v 干扰流对系统吞吐量的影响/n。/w 20/m 主语状语:为/p减少无用数据包被缓存的概率/n,谓语: 提出了/v,宾语:一种基于历史信息的侦听管理策略/n,补语:可有效减少/v干扰流对系统吞吐量的影响/n。 20/m 为/p,提出了/v,可有效减少/v 2.4 科技文摘6分类算法的结果
首先,根据上述特征词提取和句型识别算法,我们加入了特征句的位置信息、提高了特征句识别的准确率。由此,按照科技文摘中作者对创新点描述的写作特征,我们首先将实验的文摘归纳为6类,这6类代表了科技文摘的真实特征句型,并采用标记:1(问题),2(方法),3(结果),4(问题-方法),5(方法-结果),6(问题-方法-结果)。对科技文摘特征句型进行的6分类结果举例如表2所示。
表2 科技文摘特征句型6分类结果举例
类 句 1(问题) 2(方法) 3(结果) 4(问题-方法) 5(方法-结果) 6(问题-方法-结果) 句型
特征
……严重影响……,如何……成为……问题。 利用……技术,提出了……方法。 ……结果表明,……,能够降低,……,具有较低……。 针对……问题,提出了……算法。 该算法……,可以有效地……,提高……。 针对……不足,设计了……方案,并……证明了……。 句型
实例
189互联网上的虚假事实陈述严重影响人们有效地获取信息,如何判定事实陈述是否可信成为一个亟待解决的问题。 125利用云计算中的核心技术MapReduce,提出了一种在线社交网络(online social network,简称OSN)蠕虫的仿真方法。 200真实数据集上的实验结果表明,该方法在满足匿名要求的同时能够降低概化和抑制处理带来的信息损失,并且具有较低的时间和空间复杂度。 49针对多模态优化问题,提出了基于广义凸下界估计模型的改进差分进化算法。 142该算法通过感知节点能量、链路质量和链路生存性等网络状况,可以有效地均衡网络能量,提高分组投递率。 84针对该方案安全性方面的不足,本文设计了一个安全可证的属性基门限签名方案,并基于CDH困难假设,在标准模型下证明了该签名算法的安全性。 注:句型实例标记的数字为实验文摘句的编号。
3 分类算法的数据统计分析
3.1 分类算法的数据统计结果
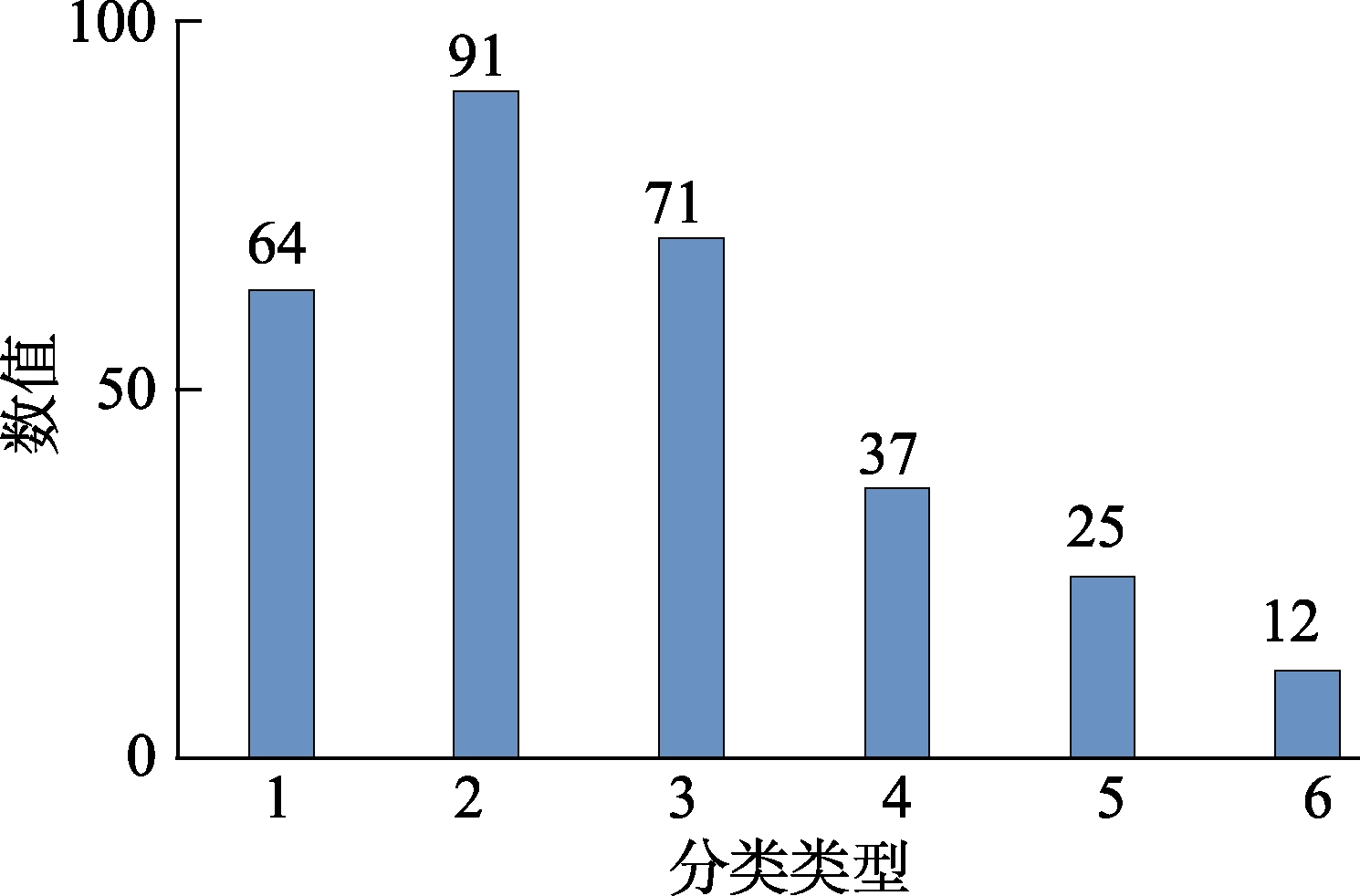
按照上述6分类算法,我们对选取的《电子学报》75篇共300句进行了程序自动分类实验,并进行了人工检验分析,正确率达到99%。对6分类数据结果进行统计分析的目的一方面是分析科技文摘创新点表达的语法、语义和语序的语用规率;二是在第一级6分类的基础上,将4、5、6三类进一步分解、合并添加到相应的1、2、3类中,最终分为3类,即1(问题)、2(方法)、3(结果)类。对6分类数据的统计结果如表3所示。
3.2 科技文摘6类句型总体数量分布图
3.3 科技文摘三大类型句分析
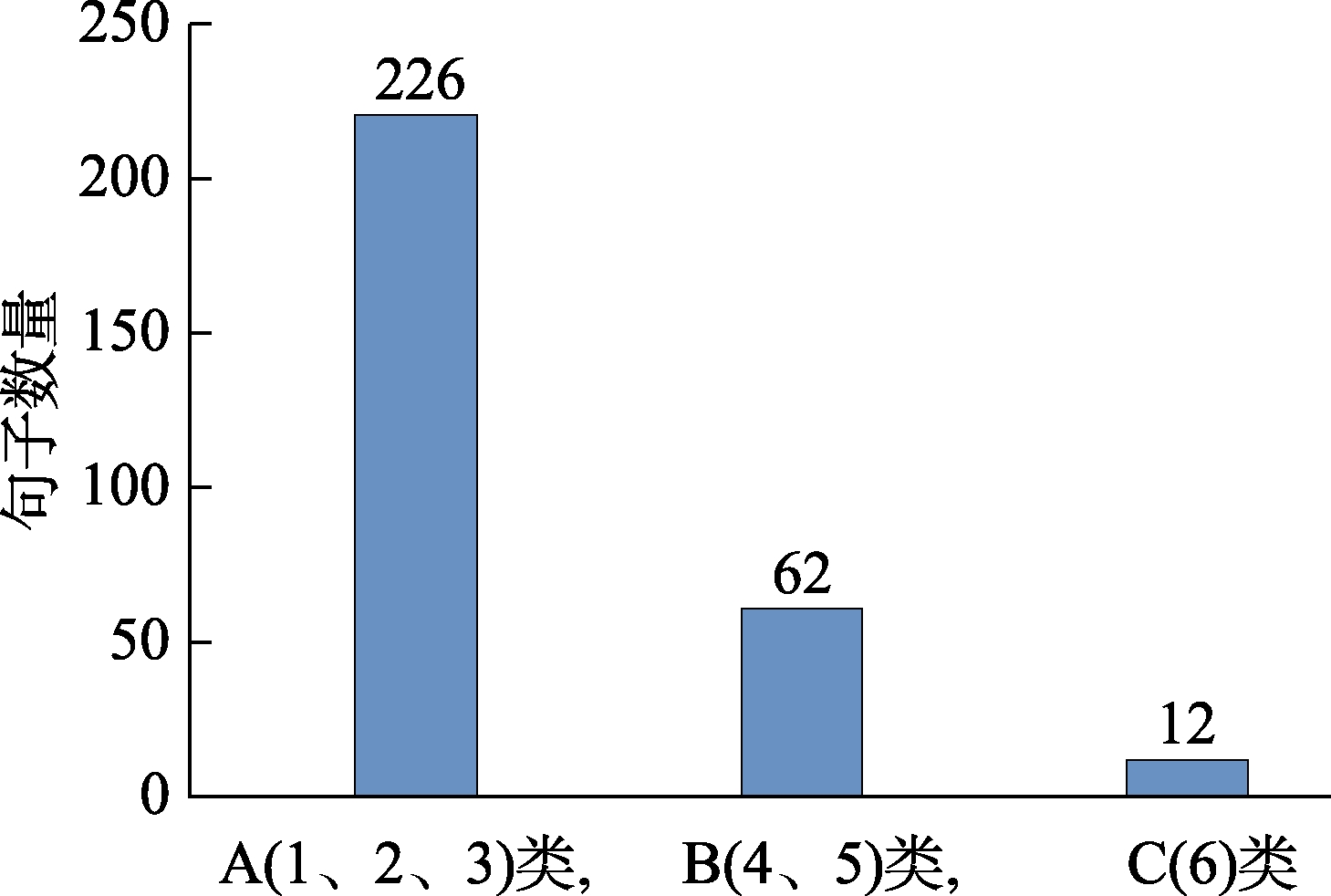
为了对上述科技文献6分类句型有一个清楚的认识,我们将其归纳成A、B、C三大类句型,A类句型由1、2、3类组成,这类句子可以独立地分成问题句、方法句和结果句。B类句型由4、5类句型组成,这类句中的一个句子里面包含了问题、方法,或方法、结果两种成分,不能直接分成独立的类。C类由6类构成,这类句型句子中包含有问题、方法和结果三种成分,也难以独立分类。
首先,我们分析这三大类句型的句子数量占总句子的比例。A类共226句,占总句子300句的75.3%;B类共62句,占总句子300句的20.7%;C类共12句,占总句子300句的4%。三大类型句子数量分布如图3所示。
然后,我们分析三大类型句的句子特征,把它们细分成单一类型句和混合类型句。
最后,我们根据语义动词和句子所在的语序位置,又将单一类型句分成单一规范句型和单一非规范句型,进一步考察语义动词和句子位置的概率问题。
分析这三大类句型的数量可以得出一个简单的结论,即进行第一次6分类所能得到真正独立分类的单一类型句子只占75.3%,剩下的24.7%句子还是并不能独立分类的混合类型句子,必须对它进行第二次细分类。
3.4 单一类型句分析
定义1单一类型句。指的是使用单一句子完成了一种类型所书写的句子。
定义2单一规范类型句。指的是使用单一句子,且语义功能词按“问题、方法、结果”的语序顺序书写的文摘句。例如,假设,第一句采用的语义动词为描述问题的句子,第二、三句为描述方法的句子,第四句描述结果的句子,它们的语义动词与文摘中句子的位置密切相关,我们把这种句子称为单一规范类型句。
定义3单一非规范类型句。指的是使用单一类型句子,但语义动词与文摘中句子的语序位置顺序无关,我们称为单一非规范类句型。
分析1 单一规范类型句与单一类型句的比例
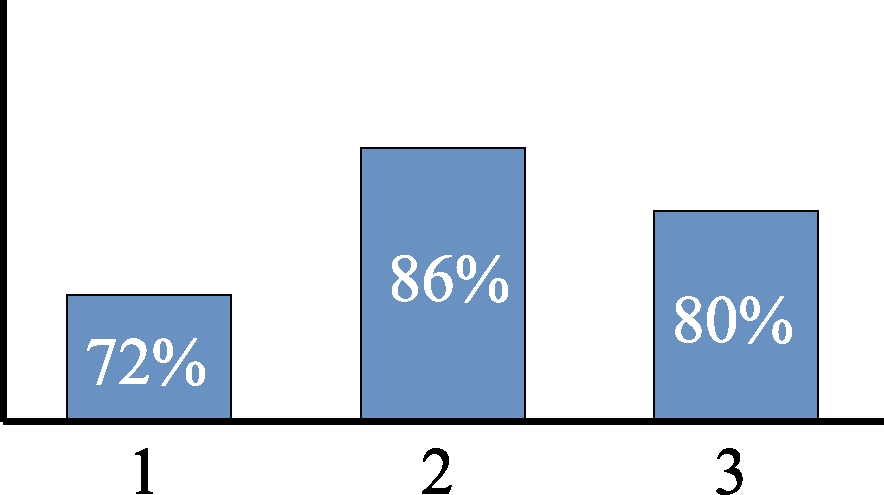
从表3可以看出,单一类型句子由A(1、2、3)类型句组成(226个句子),其中单一规范类型句子共181个句子,由第1类的第一句(46个句子),第2类的第二、三句(78个句子),第3类的第四句(57个句子)组成。单一规范文摘句型占单一类型句的比值为80%(181/226)。这说明了科技文摘书写中表达创新点的语义动词与句子的语序位置的关系有80%的概率。其余的20%句子分布虽然是单一类型的句子,但其语义动词并不是按语序顺序书写的。如第一句为书写第1类的句子有46句,占第1类句子64句的72%;第二、三句表述第2类的句子有78句,占第2类91句的86%;第四句表述第3类的句子57句,占第3类句子71句的80%。这种分布可用图4表示。
分析2 单一非规范类型句占单一类句子的比例
单一非规范类型句占单一类型句的20%,其中第1类有18句分布在第二、三句中,第2类有13句分布在第一、第四句;第3类有14句,分布在第二、三句中。这说明了文摘表达创新点的“问题、方法、结果”的单一类型句的语义语序位置并非有序,还存在20%的不规范,因为这一类型的句子写作不规范,它的识别不能依据单一规范文摘句的识别方法,它的识别算法要比规范句的识别算法复杂。
分析3 单一规范类型句占总句的比例
这种规范书写的文摘句子数只有181句,占文摘句总句300句的60.3%,这说明了《电子学报》文摘表达“问题、方法、结果”的书写规则并非有严格规范的语义动词和语序位置书写规则。因此,科技文摘句子类型的识别算法的复杂度主要在于对单一非规范句的语义结构分析,以及对混合句型的语义结构的分析。
4 单一非规范句型语义结构分析
4.1 单一非规范句型语义结构分析
单一非规范类型句占单一类型句的20%,这使得提取科技文摘创新点的“问题、方法、结果”句的效率受到影响。下面通过对单一非规范类型句的分析来寻找识别其语句的语义动词和语序位置的共同特征,优化识别算法和提取方法。表4中举例的句子标记由3部分组成,从左到右标记为一条文摘的句子位置(第几句),文摘中总句子的顺序号,6分类中的第几类。如2-38/m1,左边第一个数字2表示第二句,38表示实验文摘中的第38号句子,m1表示第1类。
表4 单一非规范类句型结构分析
第1类中的第二句(共13句) 第2类的第一句(共11句) 第3类中的第三句(共11句) 2-38/m1 当前的……不足;另一方面,缺乏……。 1-1/m2 提出了……方法。 351/m3 ……结果表明,提出的……能够有效地……,动态地实现……到……过渡。 2-58/m1由于……,……越来越受到……的重视。 1-25/m2 本文在……下,提出……算法。 3-71/m3 ……表明:该算法不但……减小……且具有……,……远小于……算法。 2-82/m1 验证者通过……,只能……,具有……作用。 1-33/m2 本文提出了……,可用于……。 387/m3 ……结果表明,……具有……性能,……快,……小。 2-122/m1 人们提出了……,其中,……可以……,从……,又可以……。 1-89/m2 文中提出了……算法。 3-95/m3另外,……实验还表明,……是……的关键参数。 2-158/m1 然而,……面临……挑战, 其……研究对于……具有……意义。 1-101/m2 提出了……方法,该方法……,获得……。 3-99/m3在该算法中,……,从而使……。 2-174/m1 现有……, 以及……等问题。 1-125/m2 利用……,提出了……方法。 3-103/m3在此基础上,不仅可得到……,而且可以获取……。 2-202/m1 已有工作……,以加强……,以加强…。 1-133/m2 ……采用……,使……成为可能。 3-155/m3 实验结果表明,……能有效降低……,可将……降到……。 2-206/m1 传统的……算法无法……获得较好的性能。 1-221/m2 利用……,本文提出了……算法。 3-187/m3 ……适用于……。 2-214/m1 例如,现有的……是……重要的,然而现有的研究很少关注这类问题。 1-229/m2 本文提出了……模型。 3-191/m3该模型针对……,从……,度量……;考虑了……差别,……度量了……,并获取了……;……实现了……。 2-254/m1 广泛采用的……存在以下问题:(1),(2),(3)。 1-265/m2 在……基础上,引入了……,提出了……算法……。 3-251/m3 ……实现了……算法,……进行仿真,与其他……对比,评估……。 2-270/m1 如何……提高……,成为……的主要任务。 1-289/m2 提出了……策略。 3-267/m3 在分析……基础上,讨论了……,并利用……证明了……。 第1类的第三句(共5句) 第3类中的第二句(共3句) 3-123/m1如何……有效,是一个新的挑战。 2-26/m3 与……相比,本文的……减少了……,同时对……保护,增强了……。 3-171m1 在此算法中,……比……具有……,……或……影响。 2-78/m3,该……不仅能……,还可……,以达到……之目的。 3-239/m1,为验证……有效性,进行了……应用实验。 2-298/m3,同时,……模型下证明了……是可证安全的。 4.2 单一非规范句语义结构分析结论
分析4 从表4的句型结构分析可以看出,第1类中的第二句(共13句)、第2类的第一句(共11句)、第3类中的第三句(共11句)是具有数量较大的单一非规范类型句。
第1类中的第二句(共13句)具有继续前一句对问题的补充的语义语序位置结构,但与第二句表达方法句(39个句)结构的相比,可以看成是一种弱语序结构形式。第3类中的第三句(共11句)是提前表达结果的语义语序位置结构,但与第三句表达方法的句子(39句)以及第四句表达结果的句子(57句)相比,也可以看成是一种弱语序结构形式。
分析5 第1类的第三句(共5句)中有2句分错,从语义结构看应分到第3类。其他三句是一种不规范的特殊写作格式。前三句都为问题句,后一句为问题、方法、结果总结句(第6类)。例如:第31条文摘由(121,122,123,124)四个句子组成,第51条文摘由(201,202,203,2044)四个句子组成,这两条文摘前三句全为问题句,第四句为第6类。第69条文摘由(273,274,275,276)四句组成,前三句全为问题句,最后一条第四句为第3类,缺少第2类句。
第3类的第二句(共3句)属于作者对结果句子的提前表达。
分析6 第2类的第一句(共11句)属于很独特的文摘写作格式,第一句就是方法句,以“提出了……方法”为特征的句型,这一类型的文摘在整个文摘中没有问题句的描述,这类文摘占总文摘数量的14.7%(11/75)。
5 混合类型句的语义结构分析
5.1 混合类型句语义结构分析
定义4 混合类型句。我们把包含两种以上类型的句子称为混合类型句。
混合类型句由6分类的第4、5、6类组成,共74句,占总实验文摘句300句的24.7%。进一步分析可以看出,属于第1类的句子数量有113句。其中64句是单一类型的第1类句子,占第1类句子的57%,而有49句是一种混合的非单一类型句子(第4类、第6类),占第1类句子的43%%。第2类句子的数量有165句。其中91句是单一的第2类句子,占第2类句子的55%,而有74句是一种混合的非单一类句子(第4、5、6类),占45%。第3类句子有108句。其中71个句子是单一的第3类,占第3类句子的66%,有37句是非单一类的混合类句子,占第3类句子的34%。单一类型句与混合类型句比例如图5所示。
由图5可以看出,采用6分类法分类,第3类的单一类型句子数量比第2类和第1类的数量多一些。但混合类型句与单一类型句的交织非常大,因此对混合类型句子的二次分类仍然是一个重要问题。
5.2 从第4、6类中分离出第1、2类
对表3的6分类结果进一步分析,纵向看,第4类有37个句子,第6类有12个句子。下面对第4类和第6类的句子结构进行统计归纳分析。
(1)第4类中第一句共18句,句子的语义结构如表5所示。
表5 句子的语义结构
文摘号 结构 句子语义结构1(第1类) 句子语义结构2(第2类) 句子语义结构3(第1类) 句子语义结构4(第2类) 1-19m/4 针对……的……优化问题, 提出了……算法, 对……进行调整, 并提出……优化,简称……算法。 (2)第4类中第二句共10个句子,句子语义的结构如表6所示。
表6 句子的语义结构
文摘号 结构 句子语义结构1(第1类) 句子语义结构2(第2类) 句子语义结构3(第1类) 句子语义结构4(第2类) 2-250/m4 针对此问题, 文中提出……判据, 该判据充分考虑……, 然后,基于……,为最大化……, 文中提出了……协议。 (3)第4类中的第三句共9句子,句子语义的结构如表7所示。
表7 句子的语义结构
文摘号 结构 句子语义结构1(第1类) 句子语义结构2(第2类) 句子语义结构3(第1类) 句子语义结构4(第2类) 3-47/m4 这种……首先分析……信息,对……进行筛选,缩小……范围; 在此基础上,建立了……模型,并定义了一种……方法; 最后根据……结果……进行……定位。 (4)第6类中的第二句共5句子,句子语义的结构如表8所示。
表8 句子的语义结构
文摘号 结构 句子语义结构1(第1类) 句子语义结构2(第2类) 句子语义结构3(第1类) 句子语义结构4(第2类) 2-50/m6 首先,基于……方法将……转变为……问题;其次,基于……理论,利用……知识, 建立……模型,设计实现了……计算方法; 进而,综合考虑原问题……与……之间的差异, 提出一种基于……指标,并设计……来保证算法……能力。 (5)第6类中的第三句共1句子,句子语义的结构如表9所示。
(6)第6类中的第四句共10句子,句子语义的结构如表10所示。这是一个典型的结构不严格的文摘。第一、二、三句都是第1类,第四句为1、2、3类。
5.3 从第5、6类中分离出第2类
第5类中的第二句共5句子,句子语义的结构如表11所示。
表11 句子的语义结构
文摘号 结构 句子语义结构1(第1类) 句子语义结构2(第2类) 句子语义结构3(第1类) 句子语义结构4(第2类) 2-34/m5 其基于……的原理, 首次采用……, 减小了……失真。 2-210/m5 本文提出基于……, 结合……, ……实现了……。 从混合句的句子语义结构可以看出,混合类型句由两个以上的多个短语组成,每个短语的语义动词准确地表达了问题、方法、结果的描述功能,只是不能按照句子的方式进行直接的分类,同时也证明了6分类算法的正确率高。
6 解决方案与评价
6.1 解决方案
通过以上对6分类算法的人工检验和分析发现,算法的语义识别能力很强,分类的准确率很高。同时也清楚地揭示了科技文摘表达创新点的语法、语义、和语序的写作结构,对智能化分类提供了科学依据。主要成果归纳如下:
(1)科技文摘对于创新点的书写大部分都是比较规范的,但也有一部分文摘的书写存在不一致性。
(2)同时也可以看出,首先我们将科技文摘对创新点的描述分为6类是符合客观实际情况的,有利于识别算法的可靠性和分类算法实现的准确性。
(3)然后再将6类句型分解为单一类型句,和混合类型句。单一规范类型句的语义动词表达具有很强的语序位置规律;单一非规范类型句的语义动词不具有语序位置规律;混合类型句有明确的语义动词,但句子的语义众多表达的概念混杂。
(4)单一规范句和非规范句型在第一次6分类中取得了准确率很高的分类结果。
(5)混合类句型具有多分类结构,先将其分为混合类型句,然后对其按短语进行二次分类,最后将其结果合并到1、2、3类,最后实现完整分类结果。
6.2 分类效果评价
人工检验和分析发现,单一句类型中有3个句子分错类,即第2类第四句共两句,程序分在第2类,这两句应该分到第3类。第2类的第三句程序分在了第1类,应分到第3类。这样277条句子得到正确分类,正确分类效率达到99%。
上述分析是对6分类得出的结果进行的分析,然而,从表3的第2类的第一句中的11条句子分析,可以看出科技文摘的作者在第一句就直接给出第2类描述方法的句子,经过人工进一步仔细分析发现包含这11条句子的文摘作者在整个文摘的其他句子中也没有给出关于问题句的描述,这类文摘占总文摘量的14.7%(11/75)。这一数据说明了电子学报75篇文摘有85.3%给出了问题句的描述,而14.7%的文摘作者就没有给出问题句的描述。如果不采取其他处理方法,文摘创新点的抽取率最多达到85.3%,如何解决将是我们下一步继续研究的问题。
参考文献
- 1
引文索引[EB/OL]. [2018-6-3]. https://baike.baidu.com/item/%E5%BC%95%E6%96%87%E7%B4%A2%E5%BC%95/8017877?fr=aladdin.
- 2
Chang S J, Rice R E. Browsing: A multidimensional framework[J]. Annual Review of Information Science and Technology, 1993, 28(4): 231-276.
- 3
CanoV. Citation behavior: classification, utility, and location[J]. Journal of the American Society for Information Science, 1989, 40(4): 284-290.
- 4
袁慧, 马建霞, 王文娟. 期刊引用行为与影响因子的关系[J]. 中国科技期刊研究, 2017, 28(11): 1058-1064.
- 5
陆伟, 孟睿, 刘兴帮. 面向引用关系的引文内容标注框架研究[J]. 中国图书馆学报, 2014, 40(6): 93-104.
- 6
郭全中. 创新知识服务——推动出版业转型发展[J]. 出版广角, 2018, 3(9): 29-31.
- 7
江锦年. 出版业知识服务创新的发展策略[J]. 新闻与写作, 2017(10): 101-103.
- 8
张晓林. 走向知识服务——寻找新世纪图书情报工作的生长点[J]. 中国图书馆学报, 2000, 11(5): 32-37.
- 9
刘寅斌, 胡亚萍. 从谷歌大脑看人工智能在知识服务上的应用[J]. 图书与情报, 2017, 20(6): 112-116.
- 10
化柏林. 学术论文中方法知识元的类型与描述规则研究[J]. 中国图书馆学报, 2016, 42(1): 30-40.
- 11
温浩, 乔晓东. 文摘创新点的语义本体模型研究[J]. 情报学报, 2017, 36(9): 964-971.
- 1
摘要
公开出版的科技文摘提供了科学研究活动中的问题、方法、结果的可靠语义事实数据,为创新点的传播与跨学科新知识发现奠定了坚实的基础。如何将其准确地的识别和分离出来将是利用人工智能技术实现创新点事实知识问答系统的关键问题。本文提出了一种创新点语义识别与分类方法。该方法先将科技文摘按照句法和语义功能进行6分类算法处理,然后对6分类算法结果进行了类与句子位置的数量分布统计分析、句子类型和句子语义位置结构特征的深入分析,检验了文摘句的语义语序特征,最后在此基础上进行二次分类和合并,实现了对科技文摘创新点的问题、方法、结果的分类实验,分类的准确率达到99%。人工检验验证了语义识别和分类算法的有效性。实验结果表明,这种方法具有算法简便、分类精度高、普适性好的优点。
Abstract
The published scientific and technical abstracts provide reliable semantic fact data of problems, methods, and results in scientific research activities, and lay a solid foundation for the dissemination of innovative points and the discovery of new interdisciplinary knowledge. Their accurate identification and separation will be a key issue in the use of artificial intelligence technology to realize an innovative factual knowledge question and answer system. This paper proposes an innovative point semantic recognition and classification method. On this method, scientific and technological abstracts are firstly classified as 6 kinds according to their syntactic and semantic functions. Secondly, the results of the classification are analyzed with statistical analysis of the number distribution of classes and sentence positions, sentence types and the structural features of sentence semantic positions, and the semantic word order characteristics of abstract sentences are tested. Finally, the second classification and merging are carried out which is based on the previous analysis, so and the classification of the innovation points, methods and results of scientific and technological abstracts is realized. The accuracy rate of classification is 99%. The experimental results show that this method has the advantages of simple algorithm, high classification accuracy, and good universality.