-
1 引 言
当今Web 2.0时代,社会化媒体和移动互联网技术的迅猛发展改变了人们获取信息的方式,“去中心化”、高度交互性和精细划分成为这一时期信息生产和传播的显著特
征[1] 。各类自媒体平台,如微信、微博等已悄然成为公众发布信息和获取信息的重要渠道。自媒体平台具有较高的开放程度,但信息发布的门槛较低、审查不严,信息生产者素质良莠不齐[2] ,致使信息失时、失真、冗余的现象广泛存在,也使用户难以便捷地获取最新的信息。因此如何有效测度信息新颖度成为自媒体进一步发展中亟待解决的问题,同时也引起了学界的关注和重视。大规模文本内容具有内涵丰富、表达多样、价值稀疏的特点,现有的针对文本新颖度评估的方法存在一定的局限性,如通过聚类或近邻算法构建的评估模型无法有效表达和处理高维数据,而概率统计方法的准确性和效果则受训练集和特征集的规模和质量的限制[3] 。部分学者采用了改进的机器学习算法,其性能和效果极大依赖于语料库标注的质量,对算法选择和参数设定也较为敏感[4] ,国内鲜有相关模型的实证研究和检验,模型的复杂性也使深度推广十分困难。微信公众号是一类重要的自媒体载体,截至2017年11月,微信官方公布的月活跃微信公众号数量为350万个,月活跃粉丝数达到了7.97
亿[5] ,微信已经成为国内最大的自媒体平台之一。但微信公众号内容的同质化问题也饱受诟病,主要体现在微信用户经常收到重复信息,对微信公众号内容的多样性并不满意[6] 。然而,目前针对中文微信公众号的新颖度量化评估鲜有研究。因此,本文以微信公众号文章为研究对象,以深度学习语言模型Doc2Vec和递归张量神经网络(Recursive Neural Tensor Networks, 简称RNTN)为基础量化计算文章的新颖度,实验结果证明了该方法的有效性及可行性。本文第2节概括了新颖度的概念以及国内外关于新颖度测度研究的进展,并指出了现有研究的不足;第3节详述了如何构建句级公众号文章的文本向量以及利用递归张量神经网络训练文档新颖度;第4节利用实验对本文所提出的方法进行实验验证分析;第5节总结了本文内容,分析了本文所提出的新颖度评估方法的优势及不足并对该研究方向进行展望。
-
2 相关研究
-
2.1 新颖度的概念及内涵
新颖度一直是信息评测和知识发现领域的重点研究内容。早在2002年,文本检索会议(Text Retrieval Conference,简称TREC)就把从评测系统中发现新颖信息作为重要研究目标。新颖度(Novelty)来源于拉丁文“novus”,韦氏词典的定义认为其是一种强调与已有事物不同的性质,表达一种新颖程度的状
态[7] 。基于这样的理解,众多学者对新颖度的探测(Novelty Detection)进行了定义,Sebastião等[8] 认为新颖度探测是对新概念进行识别,捕捉发生在已知概念和噪音信息基础上的变化;Faria[9] 指出新颖度探测强调识别出未标注的实例。在学习系统的相关研究中,新颖度探测关注的是对未知情况的发现[10] ,用于确定相关输入是否来源于已知集合与特定的类[11] 。更具体地,国内学者提出文本内容的新颖度评估一般是指在特定的文档集中,通过对比新文档与已有文档之间的内容冗余度,确定新产生的文本内容是否新颖[12] 。由此可知,国内外学者普遍认为新颖度是一个相对的概念,即信息内容在某一信息集合中的差异化程度。 -
2.2 传统的新颖度评估方法
通过文献调研发现,国内外众多学者对新颖度评估做了不少有益的研究和探索。一方面基于文本内容特征进行统计计算,如沈
阳[13] 通过分析关键词句的频度、被用户检索的频率等衡量科学文献的创新度;Zhao等[14] 关注了两个不同句子间的重叠度(Overlap),计算了“形似”和“意似”两个方面的重叠性;Allan等[15] 在新颖挖掘中采用了计算新词数的方法,以识别出新颖度高的句子。另一方面主要通过计算文档相似性来探测新颖度,如余弦距离是被最早用于句子新颖度探测的度量之一[15] ,甚至被用在如马来语等其他以字母为基础的语言的新颖度探测工作中,并取得了良好的效果[16] ;Kouris等[17] 学者则将Jaccrad相似度应用到两个不同集合的差异比较中以得出新颖度评分。在此基础上,Tsai等[18] 学者构建了兼顾“余弦相似度”等对称性度量和“新词数”等非对称性度量的综合新颖度评测框架。另外,同样基于距离的聚类方法也得到了广泛使用,如Spinosa[19] 用标准聚类方法识别未知概念,Hautamaki等[20] 学者利用k近邻算法捕捉距离图中远离正常集合的“新颖点”等。 -
2.3 基于改进机器学习的新颖度评估方法
近年来,基于机器学习的新颖度评估方法进一步发展起来。逯万辉
等[21] 学者通过Doc2Vec和HMM计算文本内容特征因子,以对学术成果主题的新颖度进行度量。Fu等[22] 构建了一个基于TF-IDF和局部敏感哈希(Locality-Sensitive Hashing)算法的文本流新颖内容侦测系统,并通过谷歌新闻的数据集进行了实证检验。与传统的二分类不同,Blanchard等[23] 通过半监督学习算法实现了对未知新颖分布的识别,同时其方法对高维数据有良好的适应性。de Faria[24] 设计的应用于数据流的“MINAS”方法将新颖度检测视为一个多值问题,并实现了新颖模式的自动更新和扩展。此外,新颖度的评估也被应用到不同领域,相关实践工作得到越来越多学者的关注,如余骞等[25] 学者提出了一种通过多阶邻域交互计算实现向用户推荐新颖度社区的方法“Novel Rec”;Cichosz等[26] 学者从新颖度探测的视角出发,结合聚类和单类支持向量机算法构建检测模型,对乳腺癌图片数据进行识别;Marchi等[27] 学者则构建了基于深度循环神经网络的声学新颖度探测模型;新颖度探测技术甚至被应用到优化机器人的导航功能中[28] 。综上所述,现有的新颖度探测研究已初具规模,国外研究也已取得较为丰硕的理论和实践成果。但从总体上看,在新颖度的评估问题上各派学者还没有形成较为统一的理论方法,尤其基于深度学习算法对文本内容进行新颖度评测仍鲜有研究。而国内有关新颖度评估的研究还处在探索和起步阶段,尤其对于中文文本的新颖度评估缺乏评测的指标及方法。因此,本文以微信公众号文章作为研究对象,提出了一种自媒体平台文章的新颖度评估方法,该方法利用非监督的句级Doc2Vec语言模型构建文本向量,基于递归张量神经网络构建新颖度测度模型,进而通过模型训练求解并量化评估文章的新颖度。
-
3 利用RNTN评估微信公众号文章的新颖度
深度学习发展至今,在文本分类、特征提取、情感分析、图像识别等领域已有广泛应用。张量神经网络模型(Neural Tensor Network,NTN)从单个词语的角度构造语义向量空间,难以正确解释长文本的含义,而且可能会导致维数灾难,目前的组合性语义向量空间又依赖大量的标记数据。而RNTN能模拟节点的动态时序行为,能够处理任意长度的输入序列,适合输入和输出数据有相关关系的训练任
务[29] 。RNTN最早被用于解决长文本的情感分类问题,而微信公众号文章也多属于长文本,且文本长度没有固定的范围,因此利用RNTN模型测度公众号文章的新颖度具有可行性。鉴于张量网络在处理实体关系计算上的优势,本文利用非线性的新颖度语义测度函数训练文档集合,通过待测度文档与文档集合之间的实体关系交互生成张量层的新颖度特征,最后将新颖度特征进行线性组合并归一化处理,输出文档的新颖度值。该评估方法包含两个阶段:首先利用语言模型技术Doc2Vec构建公众号文章的文本向量,即用数字的形式表示公众号文章的文本特征;其次把文本向量作为RNTN的输入层数据,通过RNTN模型训练公众号文章的新颖度,通过Sigmoid函数归一化处理并计算新颖度值。
-
3.1 公众号文章的新颖度语义测度函数
本文2.1节已经介绍了有关新颖度概念及内涵的相关研究。本文的研究对象聚焦于微信公众号文章,其新颖度是指在文本语义内容层面,某一文档与已有文本集从相似性、异质性和冗余性等维度量化计算出的差异化程度。Tsai
等[30] 学者认为,在文档新颖度检测中,句子级别的测度比文档级别的测度在冗余精度和冗余召回方面有着更出色的表现,并给出了文档新颖度的计算量化定义:(1)
即系统识别的新颖句子数量与文档中总句子数量的比值。该定义将一篇文档视为若干个无关联的句子构成,明确了新颖度的量化表示方法,但却割裂了句子的有向结构,并不能体现句子的语义顺序。本文参考了这种从句子维度评估新颖度的方法,并进行了语义有效性层面的改进:
式中,
-
3.2 构建公众号文章的文本向量
在本文的新颖度评估方法中,文本向量化表示是十分重要的环节,后续步骤中的新颖度模型训练需要依靠文本向量作为输入层数据,文本向量与公众号文章的语义拟合程度对RNTN的训练过程的有着很大影响。文本向量化一般通过Doc2Vec模
型[31] 实现。Doc2Vec利用非监督的学习算法获得文本的向量表示,充分考虑了词在文本中的位置和词的上下文信息,并将词映射到对应的特征向量,形成了词之间的特征矩阵,减少了文本向量化过程中的信息损耗,其侧重点是将文档高质量地映射到低维连续向量,但没有计算文档之间的相关关系,其准确率依赖于语料库的大小和文档的数量。本文从句子角度测度微信公众号文章的新颖度,为了提升模型训练性能,在Doc2Vec模型的基础上添加了句级向量进行强化改进,利用有向句子序列构建文档的向量表示。 -
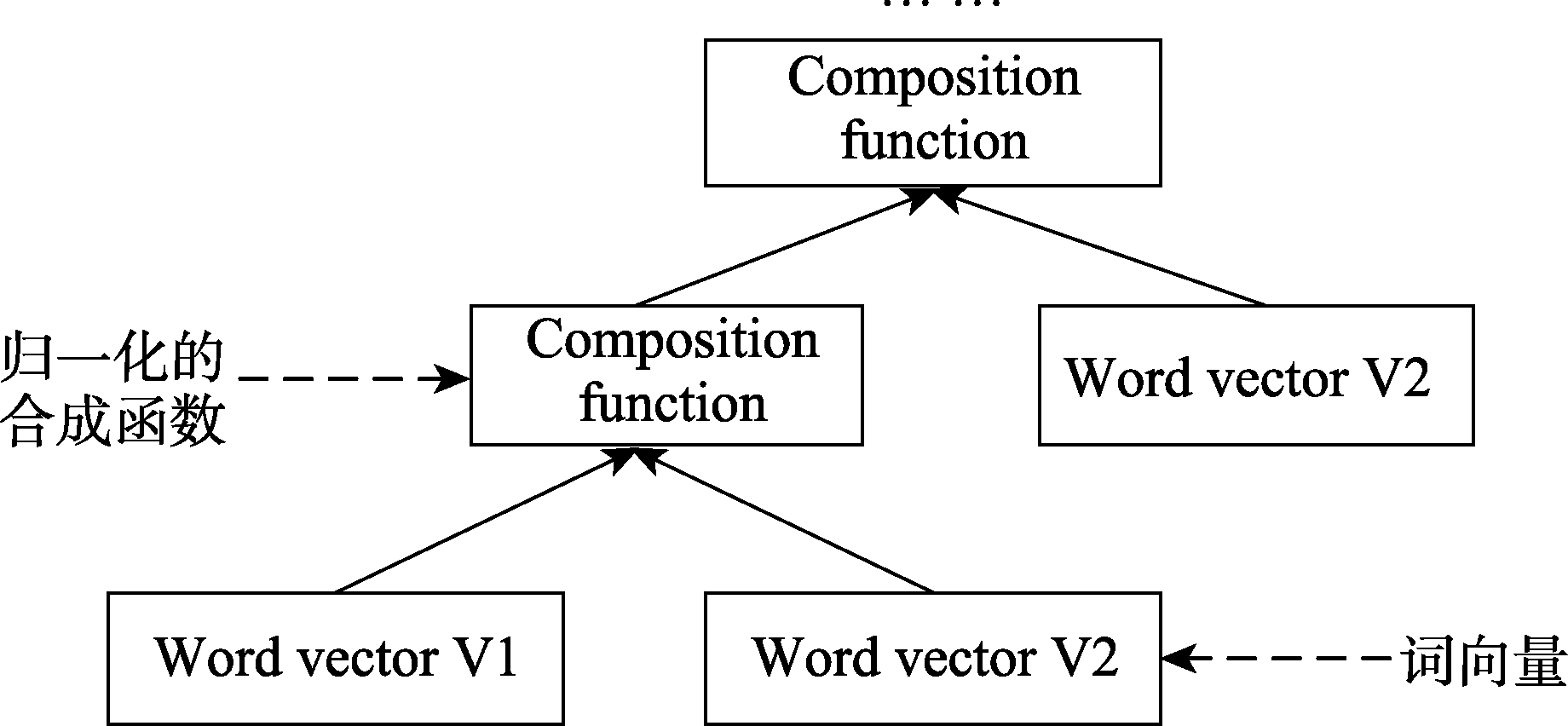
3.2.1 句级Doc2Vec
本文提出的句级Doc2Vec模型如图1所示,以Doc2Vec为基础添加句级向量增强文本的特征表示效果。给定长度为
(3)
式中,
-
3.2.2 构建公众号文章的句级文本向量
在Doc2Vec原模型中,输出层利用softmax分类器进行词分布预测,公式如下:
参考该方法,本文把句子向量
式中,
式中,
在获得句子的向量表示之后,通过建立文档级的语言模型,基于句子序列的向量表示来预测文档向量。其具体思路是把上下文句子和文档特征作为输入层数据预测当前句子的概率分布。文档
(8)
综合以上,可以梳理出句级Doc2Vec的实现算法:
算法:句级Doc2Vec模型
输入:文档集合
输出:文档向量模型
步骤:
(1)遍历文档集合中的词,建立数据字典vocab
(2)切割文档集合中的句子,建立句子矩阵
(3)随机初始化
(4)for
(5) for
(6) 标记
(7) 遍历当前词节点到huffman树root节点:
(8) 计算误差向量,更新当前词向量、中间节点向量、临近词向量
(9) End for
(10) End for
(11) for
(12) for
(13) 标记
(14) 利用公式(8)计算
(15) 更新文档向量
(16) End for
(17)End for
-
3.3 微信公众号文章的新颖度评估
-
3.3.1 RNTN训练过程
Socher
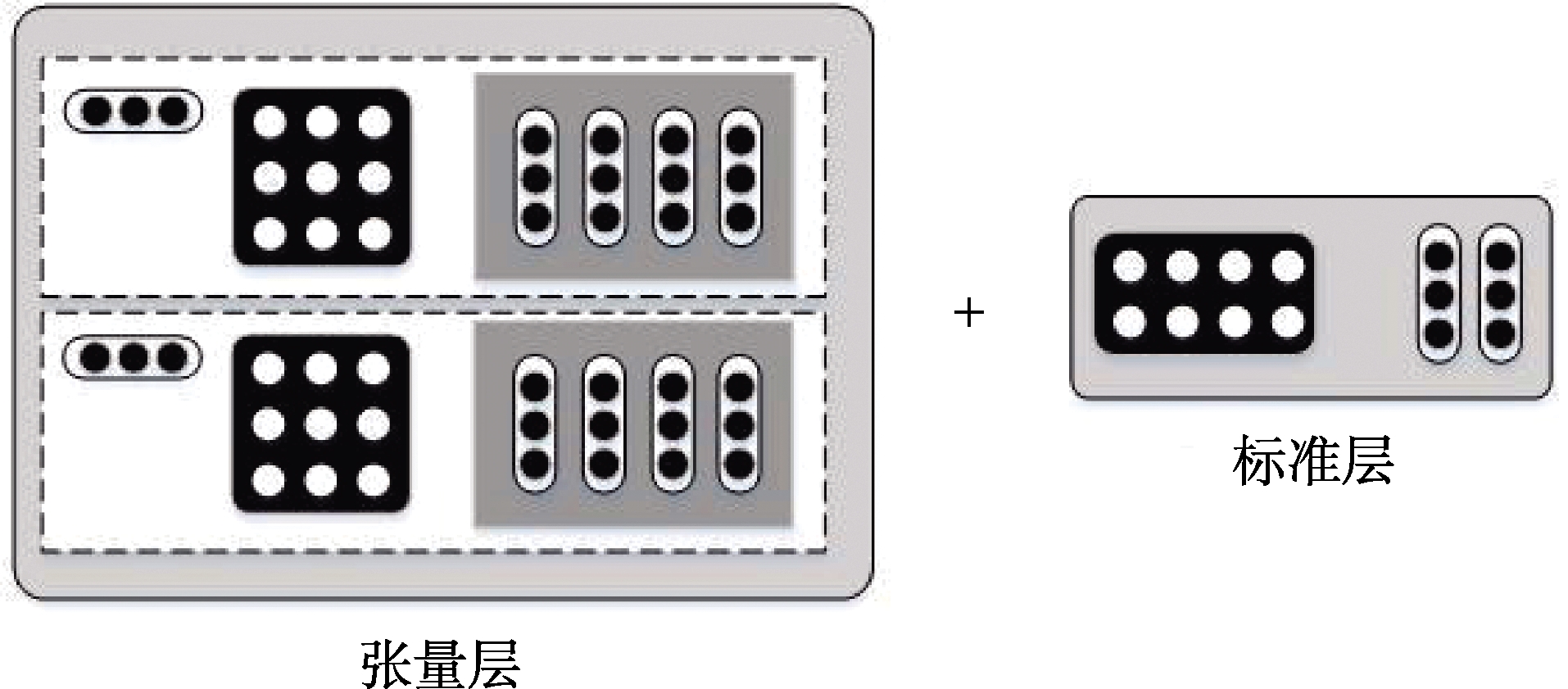
等[29] 在解决文本库中情绪检测任务时提出了RNTN。该模型在使用词向量作为特征输入的基础上,增加了解析树(Parse Tree)同步表示整个文档的语义,解析树利用递归的方式不断地吸收文档中的词作为新节点,随着解析树的层次不断增加,文档语义的表示也更加丰富。解析树以二元树作为基本的数据结构,每个节点都可以通过向量进行描述,并使用基于同一张量的合成函数计算树中高维度节点的向量,其结构如图2所示。单一张量层的形式如图3所示,可以表示为:
式中,
-
3.3.2 新颖度建模
在神经网络模型中,神经张量网络(NTN)利用双线性的张量层(Tenser Layer)可在任意维度上关联两个实体向量,因此NTN模型通常用于计算两个实体之间的关系
值[32] :类似的,RNTN模型可以通过张量积计算输入向量之间的相关关系,引申到单个文档与其他文档的新颖度关系测度中,即将文档集
式中,
-
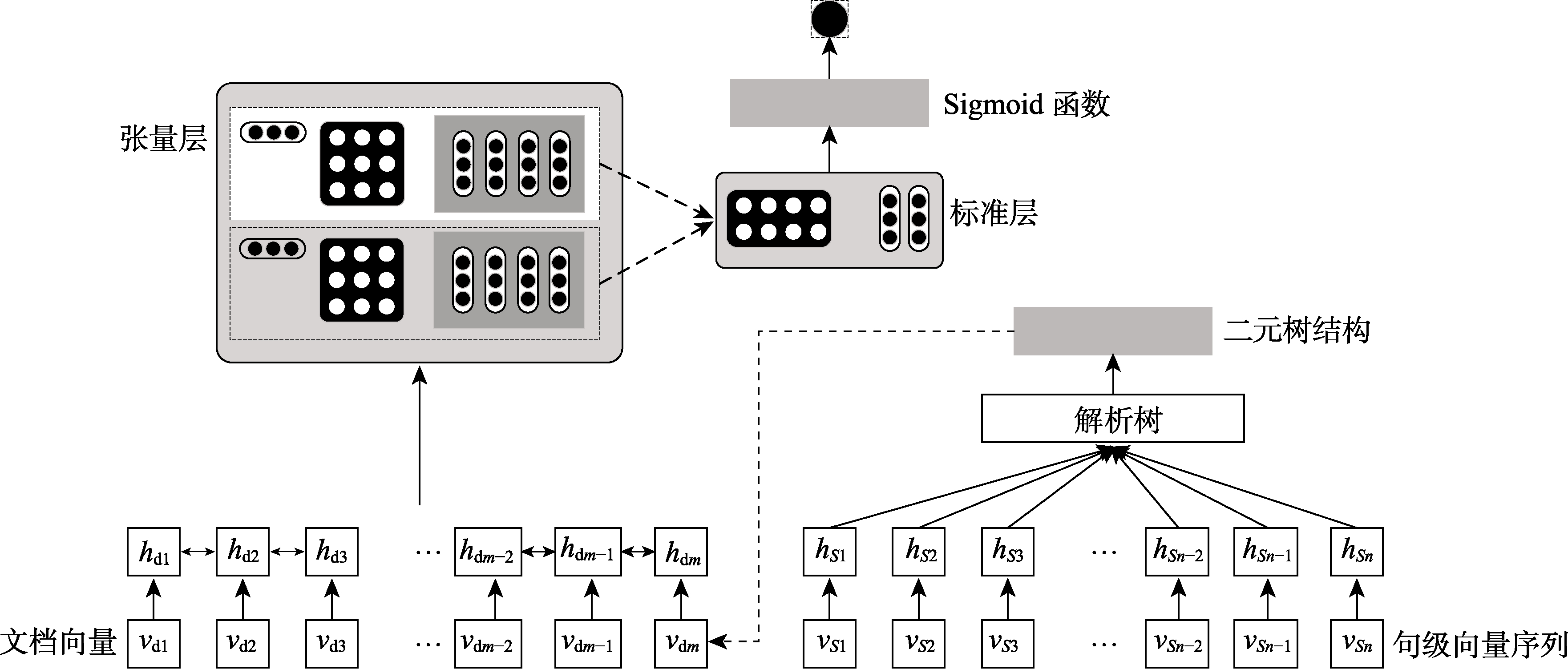
3.3.3 解析树构建与新颖度训练
如图4所示,本文将基于句级Doc2Vec向量作为解析树输入层数据,构建二元解析树结构作为文档的初步表示向量。张量切片把文档初步向量作为输入,文档
(12)
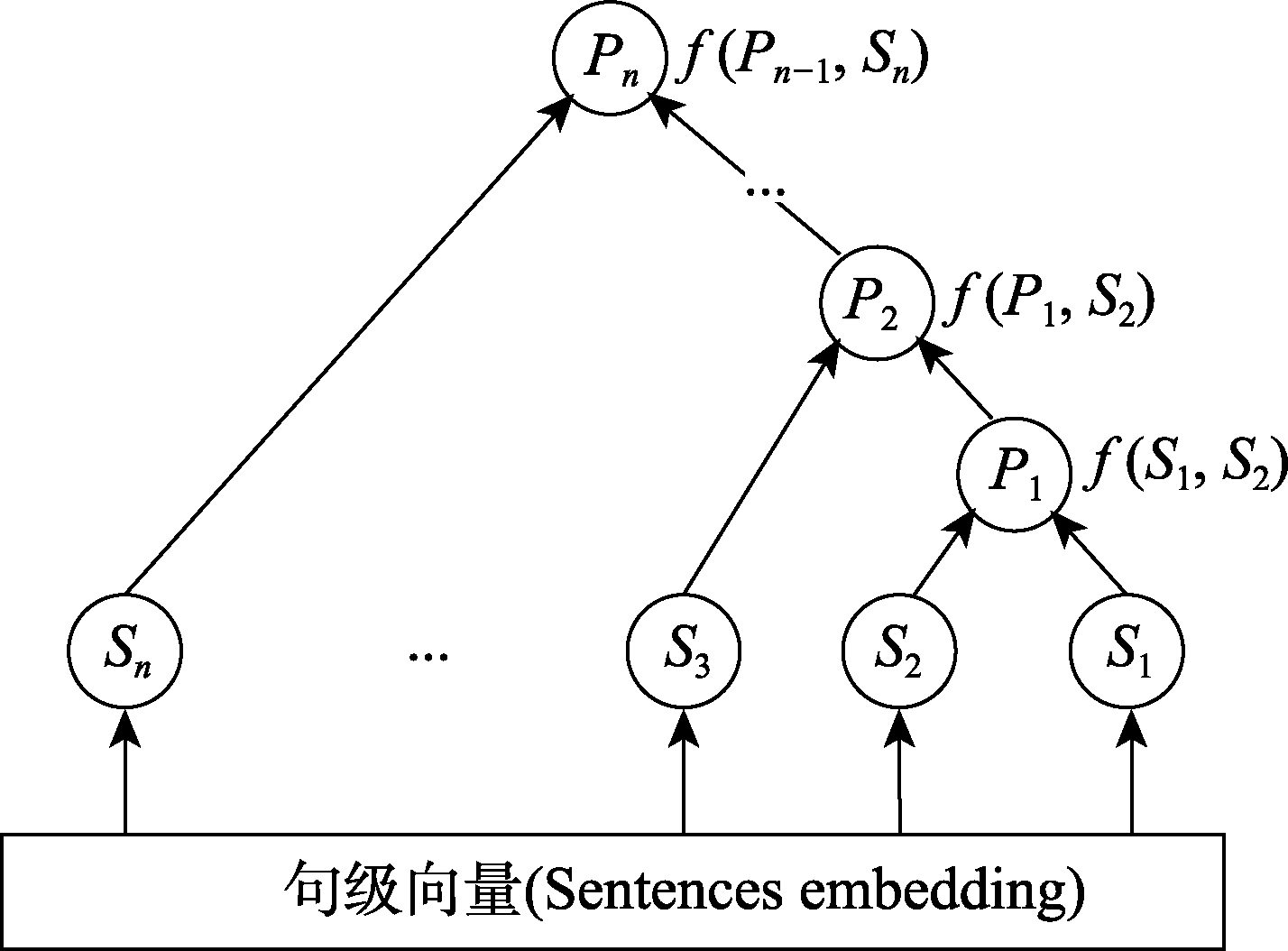
文档解析树构建方式如图5所示。树中的叶子结点由单个句子向量组成,根节点是文档的完整语义表示。文档解析树递归到
(13)
式中,
在模型训练阶段,我们用二元解析树中的节点
式中,
-
4 实证研究
-
4.1 实验准备
-
4.1.1 数据来源
本文基于搜狗搜索引擎的微信接
口[33] 自主开发了微信公众号文章的分布式爬虫,采用了标题关键词检索的方式,将数据科学领域的7组热门技术词汇作为候选关键词,分别是“大数据”、“人工智能/AI”、“数据挖掘/数据分析”、“深度学习/机器学习”、“自然语言处理/NLP”、“云计算”、“互联网/移动互联网”。在去除噪声数据后,累计采集到951个公众号的4628篇文章,其中原创文章1162篇,文章的发布时间跨度为2014年7月—2018年4月。本文以文章发布的时间戳为阈值,划分训练集和测试集,具体情况见表1。表1 实验数据集
序号 关键词 训练集 训练集时间域 测试集 测试集时间域 1 大数据 470 (2016-12-25,
2018-04-14 )
118 (2018-04-14,
2018-04-17 )
2 人工智能/AI 680 (2017-11-17,
2018-04-11)
271 (2018-04-11,
2018-04-17)
3 数据挖掘/数据分析 392 (2014-07-25,
2018-03-29)
98 (2018-03-29,
2018-04-17)
4 深度学习/机器学习 826 (2016-03-01,
2018-03-19)
207 (2018-03-19,
2018-04-17)
5 自然语言处理/NLP 224 (2015-01-30,
2018-04-11)
56 (2018-04-11,
2018-04-17)
6 云计算 424 (2015-11-07,
2018-04-01)
107 (2018-04-01
2018-04-17)
7 互联网/移动互联网 487 (2017-03-06,
2018-04-17)
122 (2018-04-17,
2018-04-17)

此外,由于微信公众号文章包含图片、视频、音频等多媒体信息,还需用正则表达式过滤多媒体内容标签,保留文章文本部分。通过数据清洗去除干扰数据后,还需经过分词、去停用词处理,剔除语义无关词,降低语义稀疏问题对文本建模造成的影响。
-
4.1.2 实验环境
本次实验采用了CPU型号为Intel(R) i5-2310(主频2.9 GHz)的主机,内存为16 GB,操作系统是Win10 64位专业版;软件方面采用了Python2.7作为主要编程语言,PyCharm 2017为集成开发环境,编码过程中用到的第三方开源工具包如Tensor Flow、Gensim、Numpy等。
-
4.2 实验结果及分析
-
4.2.1 不同张量区间的新颖度分布
按照上述研究方法和实验思路,本文选取3649篇微信公众号文章作为RNTN模型的训练集和新颖度语义参照集合,并将剩余的979篇文档作为测试集。本实验将张量的切片数量区间设置为[1,30]进行了多组实验。
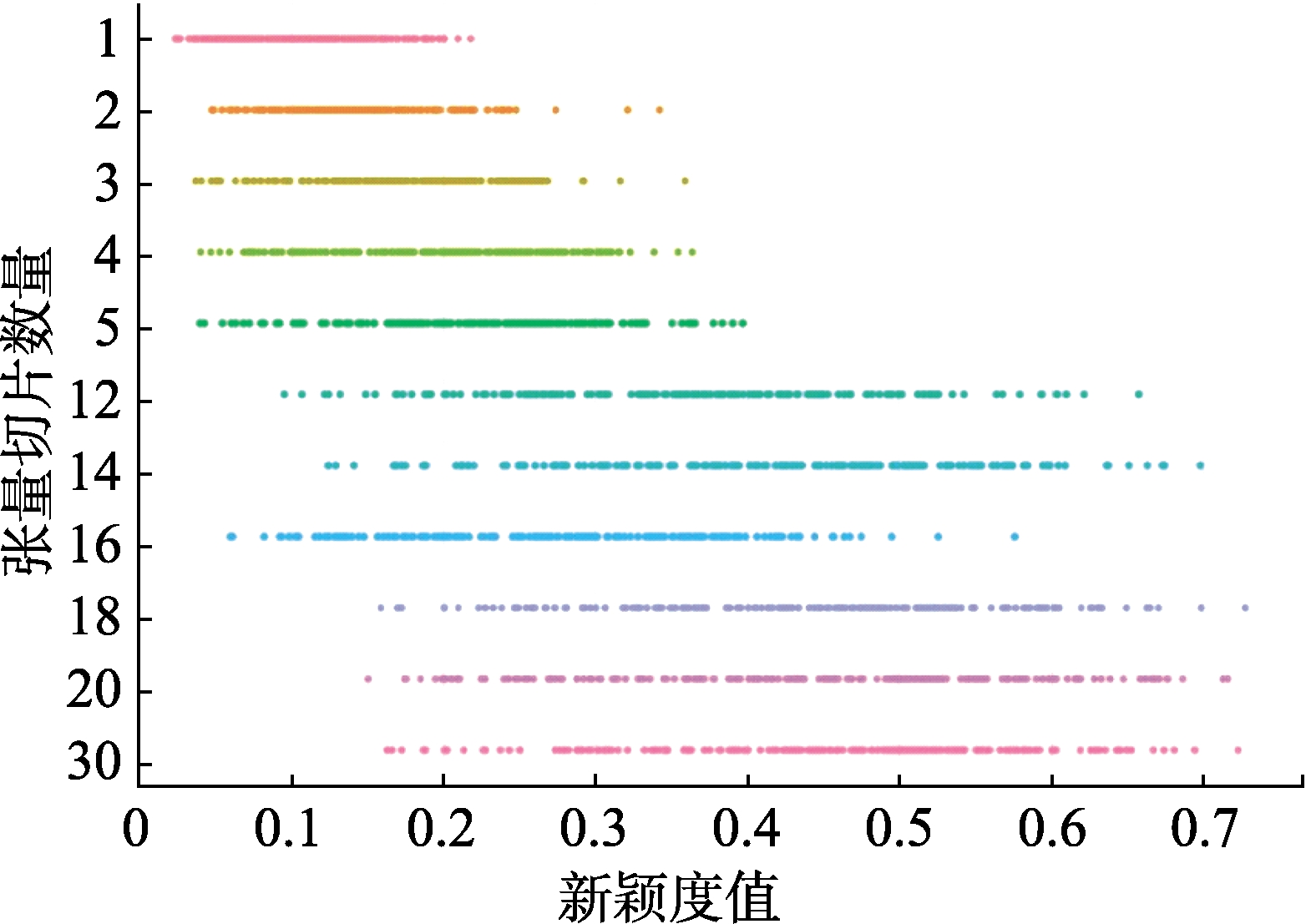
新颖度的分布区间随切片数量的变化趋势如图6所示。当切片数量小于等于5时,公众号文章之间的相关关系没有拟合,新颖度分布区间集中于0.05~0.30之间;当切片数量大于10时,公众号文章之间的新颖度差异化特征逐渐显露出来,新颖度整体分布区间扩展到0.05~0.75之间,符合正态分布趋势;当切片数量大于等于18时,公众号文章的新颖度分布趋势开始稳定。当切片数量继续增加时,拟合效果没有显著变化,新颖度值区间为0.15~0.75。
由图7可知,随着切片数量的增加,实验的训练时间呈指数级增长,当切片数量为1~5时,训练时间分别为0.045 h、0.055 h、0.070 h、0.076 h和0.078 h;当切片数量达到12时,训练时间超过1 h;此后当切片数量分别为14、16、18、20和30时,训练时间分别为1.430 h、1.600 h、2.015 h、3.180 h与10.140 h。当张量切片达到18时,测试集的新颖度分布与训练时间之间达到最优状态。
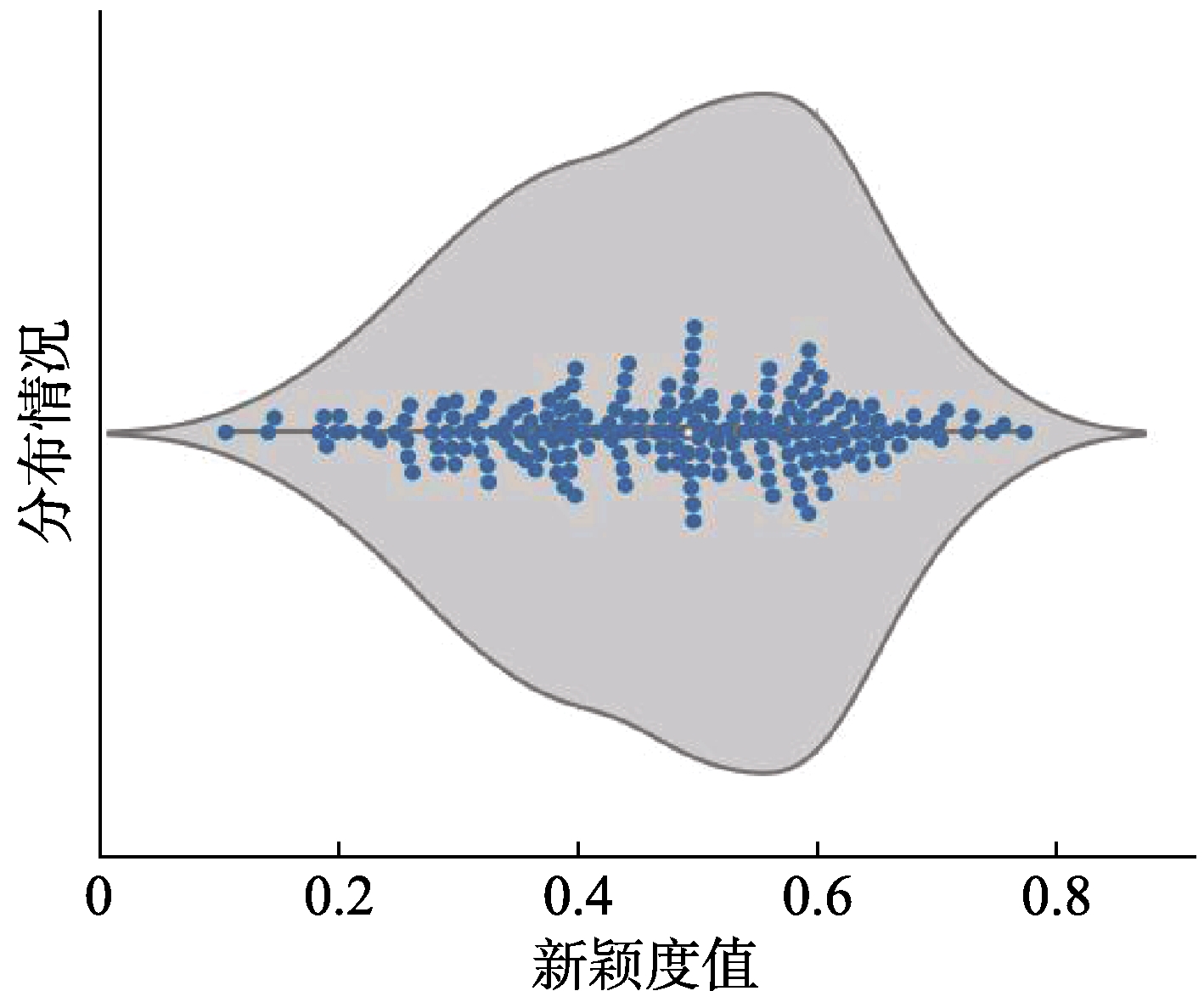
当张量切片数量设置为18时,测试集中所有公众号文章的新颖度分布如图8所示,新颖度的端点值分别是0.163和0.723。经统计超过70%的文章新颖度值在0.31~0.63,众数峰值出现在0.59左右。本文在对比研究时选取0.5作为新颖度标准阈值,则微信公众号新颖性文章占比为43.52%。
表2,3分别列举了切片数量为18时,新颖度排名最高和最低的公众号文章样例。
表2 新颖度排名最高的公众号(Top10)
排名 文档编号 标题 新颖度值 1 3432 互联网所带来的焦虑,我们有权利选择拒绝 0.723161489 2 3116 人工智能画的人体艺术,你猜画成什么样? 0.694738477 3 3457 没听过区块链?你可能对互联网金融知之有限! 0.681097031 4 273 【人工智能女友】 0.674442232 5 3156 当大数据时代来临,新购享领衔“互联网+”分享经济模式。 0.667257488 6 544 云计算使服务更高效!大数据让城市更智慧! 0.652912915 7 4407 深度学习的研究方向: 你会为AI转型么? 0.64980042 8 529 【数据分析】理科类近三年广东高考分数线汇总 | 本科二批 0.645396024 9 1287 大数据,零隐私 | 冬吴音频 0.644786149 10 1026 云计算,大数据,物联网,视频看完就明白了 0.635998487
表3 新颖度排名最低的公众号文章
排名 文档编号 标题 新颖度值 1 3641 AI复盘003:2018-04-15,轩vs弈城网友 0.163249016 2 921 AI教程/3D的饼干人 0.166252196 3 1825 大数据时代网络安全保护意识更加全面 0.17273736 4 3411 大数据透露的美国真相 0.186896563 5 4109 博鳌AI彻底火了!有巨头说未来公司都是AI+,却有AI翻译抽风了! 0.186923385 6 4617 人工智能 电力升级 | 互联网助力智慧能源 0.188402534 7 4174 8个深度学习方面的最佳实践 0.200529814 8 1846 大数据告诉你,孩子最渴望什么样的教育? 0.201455832 9 1939 人工智能应用新模式,安防机器人强势来袭 0.226280451 10 1540 “互联网+医疗健康”让百姓从容就医 0.227902293
-
4.2.2 微信公众号文章的新颖度与相似度的相关分析
学者Tsai
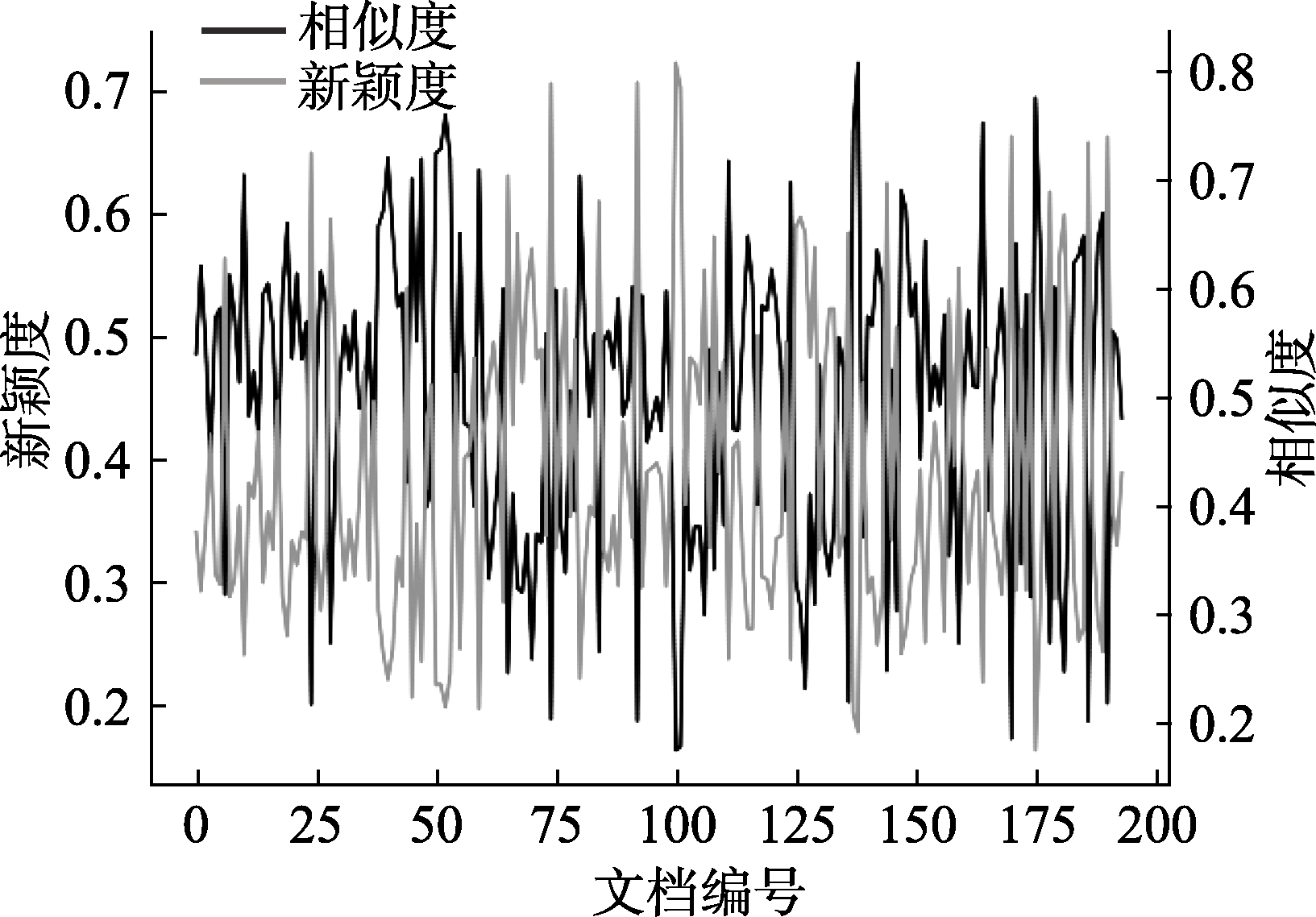
等[34] 认为在新颖度测度任务中,新颖度可以通过过滤高于一定阈值的关键词和主题相关词进行求解,在此基础上通过余弦相似度实现了文本的新颖度测度模型(Novelty Detector),并利用英文语料数据验证了这一方法的有用性。为了验证中文语料数据的新颖度与相似度的关系,本文采用了余弦相似度计算实验作为对照。余弦相似度也称为余弦距离,是指利用向量夹角的余弦值度量两个个体的差异性。本节实验选取了测试集中的200篇文章作为样本,依次遍历训练集的公众号文章计算最大余弦相似度,并以张量切片数量设置为18时的新颖度值作为对比参照,其实验结果如图9所示,公众号文章的新颖度和相似度呈现显著的负相关关系。
表4和表5分别呈现了测试集中余弦相似度最高与最低的前10篇文章,以及利用RNTN模型训练得到的该数据集新颖度排名。实验发现,当文章的余弦相似度值较高时,新颖度值相对较低;当余弦相似度值较低时,新颖度值相对较高。其中在相似度值最高的10篇文章中,新颖度排名(降序)位于前10位的有8个;在相似度值排名(降序)前10位的文章中,新颖度值位于前10位的有10个,进而验证了相似度与新颖度负相关关系的假设。
表4 相似度排名前10的公众号文章
文档编号 标题 余弦相似度 新颖度值 相似度排名 新颖度排名
(降序)
3641 AI复盘003:2018-04-15,轩vs弈城网友 0.807301 0.163249 1 1 4109 博鳌AI彻底火了!有巨头说未来公司都是AI+,却有AI翻译抽风了! 0.789149 0.186923 2 5 4617 人工智能 电力升级|互联网助力智慧能源 0.788277 0.188403 3 6 921 AI教程/3D的饼干人 0.784307 0.166252 4 2 1825 大数据时代网络安全保护意识更加全面 0.739473 0.172737 5 3 1846 大数据告诉你,孩子最渴望什么样的教育? 0.739188 0.201456 6 8 3411 大数据透露的美国真相 0.73386 0.186897 7 4 4174 8个深度学习方面的最佳实践 0.724292 0.20053 8 9 1939 人工智能应用新模式,安防机器人强势来袭 0.703469 0.22628 9 11 1540 “互联网+医疗健康”让百姓从容就医 0.696424 0.227902 10 12
表5 相似度(降序)排名前10的公众号文章
文档编号 标题 余弦相似度 新颖度值 相似度排名(降序) 新颖度排名 3116 人工智能画的人体艺术,你猜画成什么样? 0.173995 0.694738 1 2 3432 互联网所带来的焦虑,我们有权利选择拒绝 0.190664 0.723161 2 1 3156 当大数据时代来临,新购享领衔“互联网+”分享经济模式。 0.208335 0.667257 3 5 1026 云计算,大数据,物联网,视频看完就明白了 0.212065 0.635998 4 10 3457 没听过区块链?你可能对互联网金融知之有限! 0.213520 0.681097 5 3 4407 深度学习的研究方向: 你会为AI转型么? 0.222670 0.628913 6 7 544 云计算使服务更高效!大数据让城市更智慧! 0.234762 0.652912 7 6 273 【人工智能女友】 0.236364 0.674442 8 4 529 【数据分析】理科类近三年广东高考分数线汇总 | 本科二批 0.244464 0.645396 9 8 1287 大数据,零隐私 | 冬吴音频 0.255635 0.644786 10 9
-
4.2.3 微信公众号文章的新颖度与相似度的回归关系
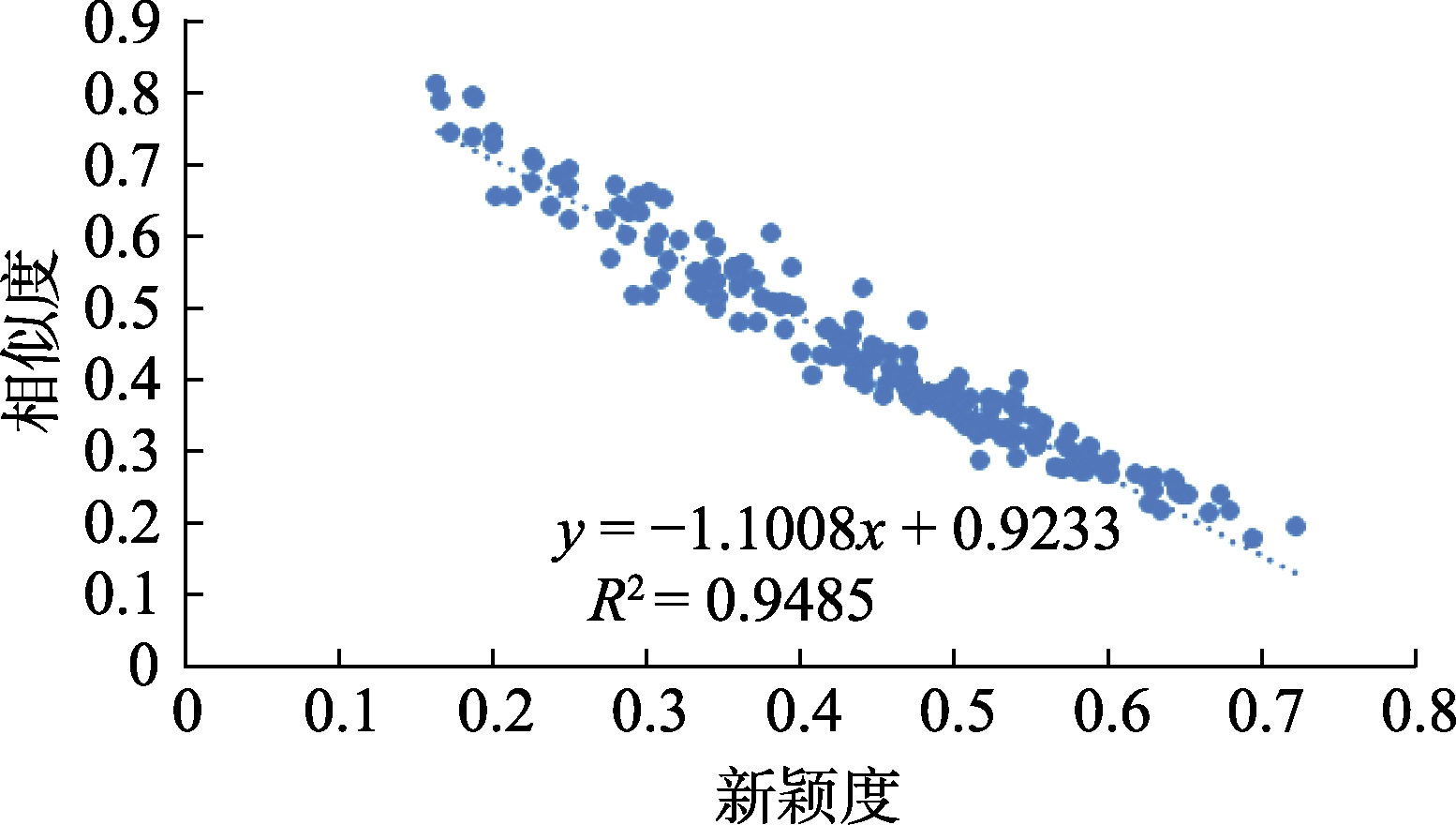
为了进一步验证新颖度和相似度是否存在回归关系,本章节将公众号文章
-
5 结语与展望
针对自媒体平台的文章新颖度量化评估问题,本文提出了一种基于递归张量神经网络的文本内容新颖度评估方法。具体而言,该方法利用句级文本向量构建了文本的语言模型,基于向量表示了微信公众号文章的语义,引入了递归张量神经网络模型,利用解析树表示句级文本向量作为神经网络的输入层数据,随后利用张量层自动抽取并计算文本的新颖度指标,最终通过归一化处理计算出新颖度值。本文通过实验验证了该方法的有效性,其流程主要包括语料库构建、文本向量表示以及模型训练三个重要环节。同时本文设置了多组对照实验对比RNTN模型中不同张量切片数量对实验性能的影响,通过观察新颖度的区间分布以及训练时间的变化情况,实验表明切片数量为18时,实验性能最佳。此外,本文还通过回归分析验证了微信公众号文章的新颖度和相似度存在着负相关及线性回归关系,并通过R² 检验得出相关强度为0.9485。
与传统的基于统计或机器学习的新颖度测度方法相比,本文采用的无监督深度学习算法避免了实验性能对手工标注数据集准确率的依赖,同时本方法的主要优势在于:在Doc2Vec语言模型的基础上,添加了句级文本向量作为中间层向量,利用句级向量构建微信公众号文章的向量模型能够更加充分地表示文章的语义特征。但是由于目前没有成熟的自媒体平台文章的新颖度标注语料库,无法从实验结果的精度、召回率、F1值等常用指标对本方法的性能进行精确评估。同时本文仅选取了微信公众号的少量文章作为实验样本,而自媒体平台的内容形式多元,因此实验数据具有一定的局限性。而新颖度应是一个动态概念,因此拓展实验样本数量及类型、通过将时间节点纳入动态评估指标以优化模型等将是未来研究的努力方向。
-
参 考 文 献
-
1
熊回香. 面向Web3.0的大众分类研究[D]. 武汉: 华中师范大学, 2011.
-
2
代玉梅. 自媒体的传播学解读[J]. 新闻与传播研究, 2011(5): 4-11.
-
3
Pimentel M A F, Clifton D A, Clifton L, et al. A review of novelty detection[J]. Signal Processing, 2014, 99: 215-249.
-
4
Markou M, Singh S. Novelty detection: a review—part 2: neural network based approaches[J]. Signal Processing, 2003, 83(12): 2499-2521.
-
5
微信. 2017微信数据报告[EB/OL]. [2018-06-09]. http://mp.weixin.qq.com/s/CDh91V9RIcVlAyRoiCOI0Q.
-
6
苏正. 微信用户获取信息质量的满意度调查分析[D]. 郑州: 郑州大学, 2017.
-
7
Merriam-Webster. Novelty[EB/OL]. [2018-06-09]. https://www.merriam-webster.com/dictionary/novelty.
-
8
Sebastião R, Gama J, Rodrigues P P, et al. Monitoring incremental histogram distribution for change detection in data streams[C]// Proceedings of the Second International Workshop on Knowledge Discovery from Sensor Data. Heidelberg: Springer, 2010: 25-42.
-
9
Faria E R. Novelty detection in data streams[J]. Artificial Intelligence Review, 2016, 45(2): 235-269.
-
10
Perner P. Concepts for novelty detection and handling based on a case-based reasoning process scheme[J]. Engineering Applications of Artificial Intelligence, 2009, 22(1): 86-91.
-
11
Kliger M, Fleishman S. Novelty detection with GAN[OL]. https://arxiv.org/abs/1802.10560.
-
12
邢美凤, 过仕明. 文本内容新颖度探测研究综述[J]. 情报科学, 2011, 239(7): 1098-1103.
-
13
沈阳. 一种基于关键词的创新度评价方法[J]. 情报理论与实践, 2007, 30(1): 125-127.
-
14
Zhao L, Zhang M, Ma S. The nature of novelty detection[J]. Information Retrieval, 2006, 9(5): 521-541.
-
15
Allan J, Wade C, Bolivar A. Retrieval and novelty detection at the sentence level[C]// Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2003: 314-321.
-
16
Kwee A T, Tsai F S, Tang W. Sentence-level novelty detection in English and Malay[M]// Advances in Knowledge Discovery and Data Mining. Heidelberg: Springer, 2009: 40-51.
-
17
Kouris I N, Makris C H, Tsakalidis A K. Using information retrieval techniques for supporting data mining[J]. Data & Knowledge Engineering, 2005, 52(3): 353-383.
-
18
Tsai F S, Tang W, Chan K L. Evaluation of novelty metrics for sentence-level novelty mining[J]. Information Sciences, 2010, 180(12): 2359-2374.
-
19
Spinosa E J, Gama J. Novelty detection with application to data streams[J]. Intelligent Data Analysis, 2009, 13(3): 405-422.
-
20
Hautamaki V, Karkkainen I, Franti P. Outlier detection using k-nearest neighbour graph[C]// Proceedings of the 17th International Conference on Pattern Recognition. Los Alamitos: IEEE Computer Society Press, 2004: 430-433.
-
21
逯万辉, 谭宗颖. 学术成果主题新颖性测度方法研究——基于Doc2Vec和HMM算法[J]. 数据分析与知识发现, 2018(3): 22-29.
-
22
Fu X Y, Ch ng E, Aickelin U, et al. An improved system for sentence-level novelty detection in textual streams[C]// Proceedings of the 3rd International Conference on Smart Sustainable City and Big Data. IET, 2016.
-
23
Blanchard G, Lee G, Scott C. Semi-supervised novelty detection[J]. Journal of Machine Learning Research, 2010, 11: 2973-3009.
-
24
de Faria E R, de Leon Ferreira Carvalho A C P, Gama J. MINAS: multiclass learning algorithm for novelty detection in data streams[J]. Data Mining and Knowledge Discovery, 2016, 30(3): 640-680.
-
25
余骞, 彭智勇, 洪亮, 等. 基于用户邻域和主题的新颖性Web社区推荐方法[J]. 软件学报, 2016, 27(5): 1266-1284.
-
26
Cichosz P, Jagodziński D, Matysiewicz M, et al. Novelty detection for breast cancer image classification[J]. Proceedings of the SPIE, 2016, 10031: Article ID 1003135.
-
27
Marchi E, Vesperini F, Squartini S, et al. Deep recurrent neural network-based autoencoders for acoustic novelty detection[J]. Computational Intelligence and Neuroscience, 2017, 2017: Article ID 4694860.
-
28
Richter C, Roy N. Safe visual navigation via deep learning and novelty detection[C]// Proceedings of Robotics Science and Systems, 2017.
-
29
Socher R, Perelygin A, Wu J Y, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2013: 1631-1642.
-
30
Tsai F S, Zhang Y. D2S: Document-to-sentence framework for novelty detection[J]. Knowledge and Information Systems, 2011, 29(2): 419-433.
-
31
Le Q, Mikolov T. Distributed representations of sentences and documents[OL]. https://arxiv.org/pdf/1405.4053.pdf.
-
32
Socher R, Chen D, Manning C D, et al. Reasoning with neural tensor networks for knowledge base completion[C]// Proceedings of the International Conference on Neural Information Processing Systems. Granada: Curran Associates Inc, 2013: 926-934.
-
33
搜狗. 微信搜索[EB/OL]. [2018-06-29]. http://weixin.sogou.com/weixin.
-
34
Tsai M F, Chen H H. Some similarity computation methods in novelty detection[J]. Proceedings of TREC, NIST Special Publication: SP, 2002, 18(1): 655-660.
-
1
摘要
自媒体平台内容同质化问题日益严重,导致用户难以从中获取新颖优质的信息,因此对其文章内容进行新颖度评估就显得尤为重要。本文以微信公众号文章为例,提出了一种自媒体平台文章的新颖度评估方法,该方法利用非监督的句级Doc2Vec语言模型构建文本向量,基于递归张量神经网络构建新颖度测度模型,进而通过模型训练求解并量化评估文章的新颖度。本文从微信公众平台自动采集4,628篇文章开展实证研究,首先设置不同的张量切片数量进行对照实验,综合新颖度分布特征和训练时间计算最优参数,然后通过计算文档相似度验证了文章的新颖度和相似度之间的线性回归关系。该实验结果证明了本方法具有较强的可行性和有效性,从深度学习的视角拓展和丰富了文本新颖度评估的研究,也为自媒体平台的新颖话题探测和前沿知识发现提供了支撑。
Abstract
The problem of content homogeneity in We-Media platforms is becoming increasingly serious, making it difficult for users to obtain high-quality information. Therefore, it is particularly important to evaluate the novelty of We-Media articles. Taking the articles of WeChat Subscription as an example, this paper proposes a novelty evaluation method for articles on We-Media platforms, using an unsupervised sentence level Doc2Vec language model to construct the text vector, and establishes a novelty evaluation model to quantify articles’ novelty based on the recursive neural tensor network. This paper automatically collected 4,628 articles from WeChat Subscription to conduct an empirical research. First, a number of different tensor slices were selected to conduct contrastive experiments, and the optimal parameters were obtained by combining the feature of novelty distribution and training time. Subsequently, the linear regression relationship between novelty and similarity was discovered and then verified by calculating the similarity of the documents. The experimental results demonstrate the feasibility and effectiveness of this approach. This paper expands and enriches the research on document novelty evaluation from the perspective of deep learning. It also supports the novel topic detection and frontier knowledge discovery of We-Media platforms.