-
1 引 言
当前,数字图书馆对馆藏数字资源的组织方式,延续了传统图书馆馆藏资源组织的基本方法,仍然是以文献为最小组织单位,无法实现对知识内容本身的有效管
理[1,2] 。人们在查找自己所需的知识时,不得不首先检索到包含自己所需知识的文献,然后再从文献中定位自己所需要的知识,增加了用户的认知负担和使用成本。由此可见,以文献为单位的知识组织与服务方式已无法有效满足人类的知识需求,成为数字图书馆知识服务变革的重要瓶颈。相关学者认为解决这一瓶颈的有效方法是将数字图书馆知识服务的单位由文献单元深入到知识单元[3] ,并依据知识之间的逻辑关系建立知识单元之间的链接,生成多种粒度层次的知识单元,进而提供多粒度的集成知识服务,使得数字图书馆的知识服务方式逐渐由以文献(知识的载体)、信息(知识的某些特征,如主题、数据、关键词等)为单元[4] 的知识服务方式朝着以知识本身为基本单元的知识服务的方向发展,这也被认为是图书情报学取得突破的关键问题。而关联数据[5] 意在摆脱现有知识组织方式的粗粒度与语义性缺失,以开放互联的方式实现分散异构知识的语义关联[6] ,关联数据的提出为数字图书馆的发展带来了新的机遇。越来越多的数字图书馆将自己的数据发布为关联数据[7] ,然而,需要指出的是当前数字图书馆关联数据应用主要集中在书目数据、规范数据等有关知识载体(文献)信息的关联数据创建与发布,面向知识内容本身的关联数据应用较少。为此,本文在对数字图书馆馆藏资源的特征进行分析的基础上,提出一种基于关联数据的数字图书馆多粒度集成知识服务方式,以为数字图书馆用户提供“检索即所得”的多粒度集成知识服务,提高数字图书馆的易用性,降低用户的认知负担和使用成本。 -
2 基于关联数据的数字图书馆多粒度集成知识服务
本文借助关联数据技术提出了数字图书馆多粒度集成知识服务方法。该方法试图向数字图书馆用户提供一站式的“检索即所得”的知识服务。为实现基于关联数据的数字图书馆多粒度集成知识服务,本文设计了如图1所示的基于关联数据的数字图书馆多粒度集成知识服务框架。从图1可以看出,该框架主要包括四个层次:资源层、多粒度关联数据创建层、多粒度关联数据索引层和多粒度关联数据检索层。资源层主要包括数字图书馆存储的各类数字资源,如电子书、期刊论文、学位论文、报纸等;多粒度关联数据创建层主要任务是提取数字馆藏资源语义信息,实现数字馆藏资源的关联数据化;多粒度关联数据索引层主要任务是实现数字图书馆馆藏资源的多粒度关联索引;多粒度关联数据检索层主要任务是完成与用户的交互,实现基于用户需求模式的检索和语义导航。
-
3 基于关联数据的数字图书馆多粒度集成知识服务的关联问题
-
3.1 数字图书馆多粒度关联数据创建
多粒度关联数据的创建是数字图书馆多粒度集成知识服务系统的基础,其目的主要是依据关联数据创建的基本原则进行数字馆藏资源的关联数据化,实现数字馆藏资源的多粒度层级组织(图2)。具体来说,多粒度关联数据的创建主要包括四个基本步骤:首先,对数字图书馆馆藏资源依据主题进行多粒度层级分割,生成细粒度的文本片段;然后,识别文本片段中包含的知识元;接着,基于本体概念树对知识元进行语义标注;最后,基于语义标注结果,依据关联数据创建的原则实现多粒度关联数据创建。
-
3.1.1 数字馆藏资源的多粒度层级分割
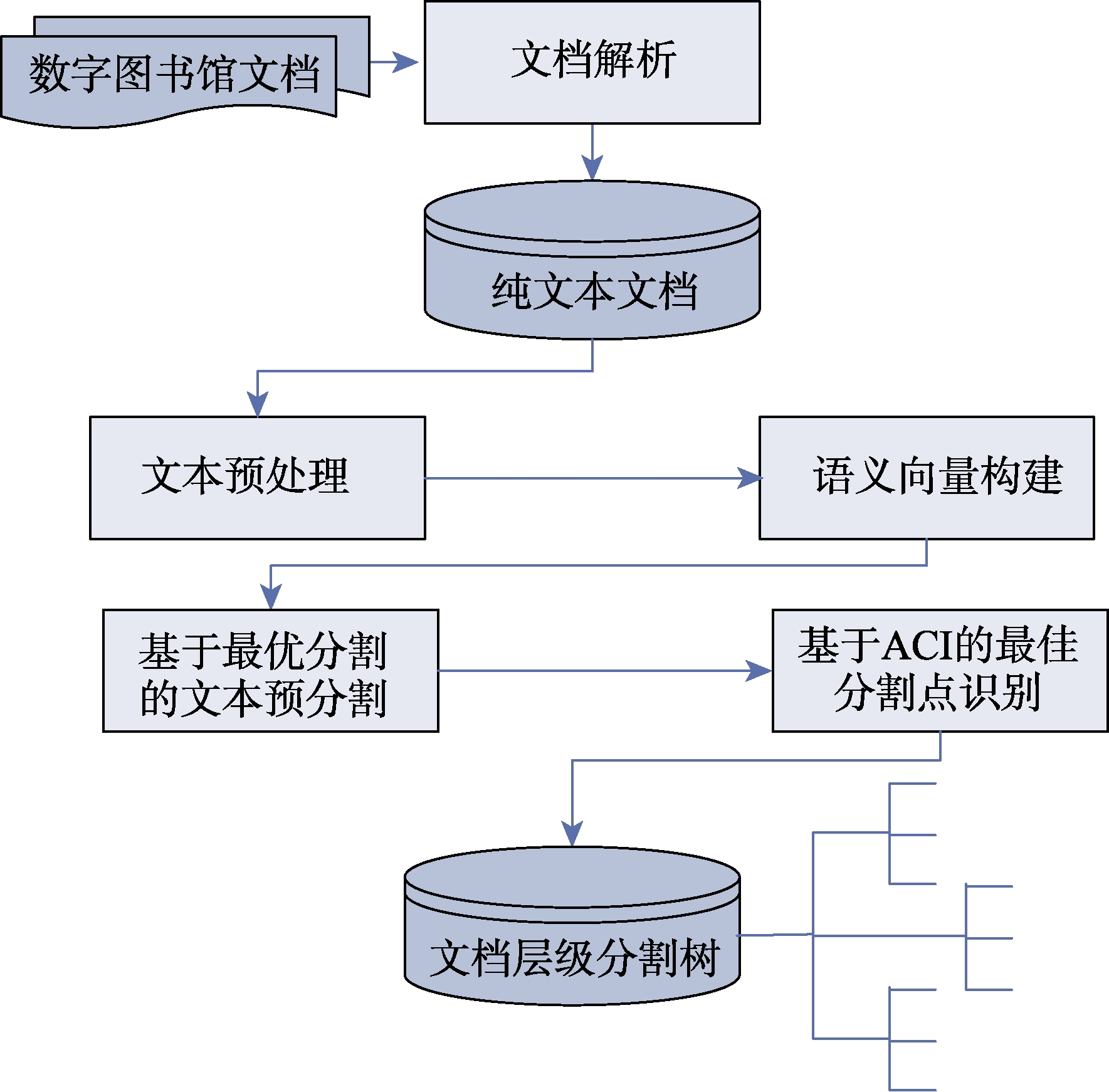
数字馆藏资源的多粒度层级主题分割主要任务是依据文献论述的主题以及主题之间的隶属关系,对文献进行多粒度层级分割,生成一个多粒度层级分割树,树的叶节点是文献论述的最小主题。具体包括:文档解析、文本预处理、语义向量构建、基于最优分割的文本预分割和基于ACI的最佳分割点识别等步骤(图3)。文档解析可以将数字图书馆各种格式类型的信息资源(如PDF、CAJ等)解析成没有任何文本修饰的纯文本文档;文本预处理主要是对文档进行分句、分词、去除没有标识价值的停用词等操作;语义向量构建的主要功能是将高维的语句词向量映射到低维的语义空间;基于最优分割的文本预分割首先依据分割函数对文档进行分割,而后通过绘制最小误差函数随分割个数变化的趋势图识别候选分割点;基于ACI的最佳分割点识别的主要功能是依据ACI准则确定最佳分割方案;最终生成一棵有机的包含多种粒度的层级分割树。数字馆藏资源多粒度层级主题分割算法见表1。
表1 数字图书馆馆藏资源多粒度层级主题分割算法
输入:包含n个语句的文献
输出:一棵文本层级分割树
1.文本解析,将数字图书馆各种格式类型的文献解析成没有任何文本修饰的纯文本文档;
2.文本预处理,对文档进行分句、分词、去除停用词等操作;
3.语义向量构建,依据奇异值分解公式
4.识别待分割的
5.依据分类函数
6.依据计算得到的所有
7.确定分割点,也即分类误差最小的分割点i即为所求的二分点;
8.对新生成的两个分割(设为分割
9.在直角坐标系中进行描点,绘制出最小误差函数
10.依据公式
-
3.1.2 知识元识别
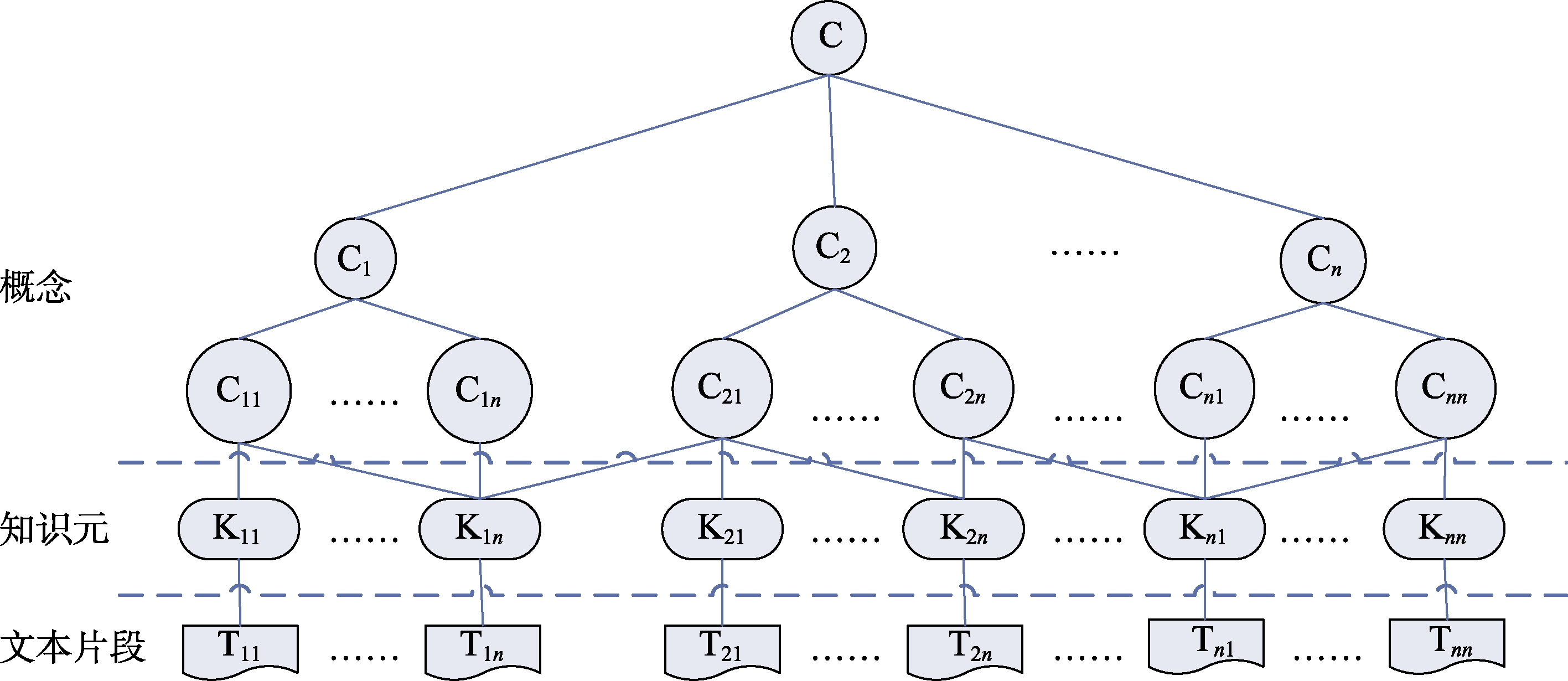
在多粒度层级分割树中,每个叶节点构成一个基本的知识单元,也即知识
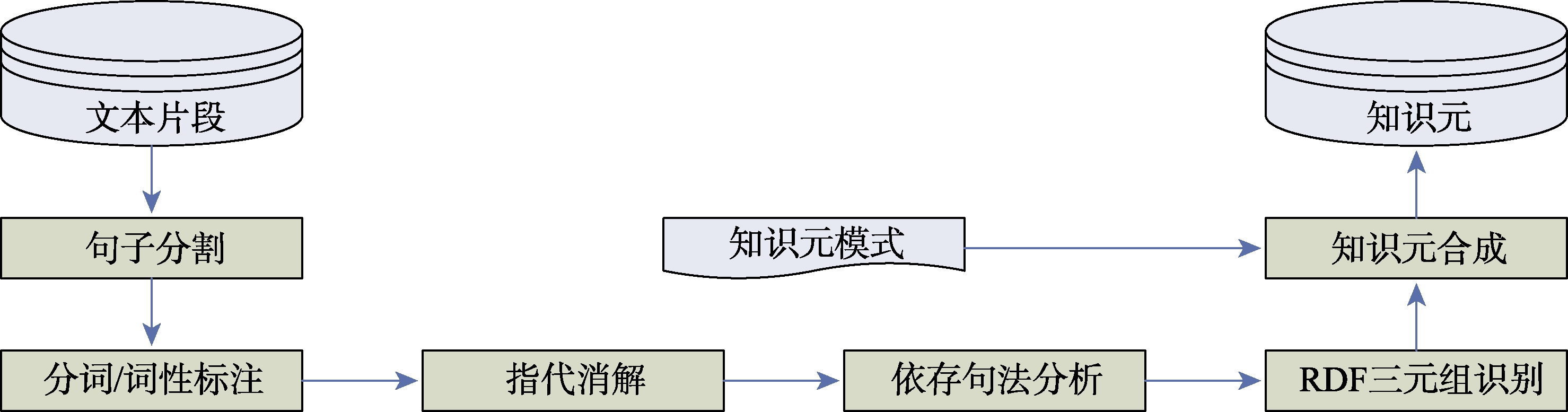
元[8,9,10] 。从内容上分,知识元包括概念知识元、事实知识元等多种类型。而无论是什么类型的知识元,本文在进行知识元识别时,均采用了统一的知识元结构模型,即,知识元:{名称,属性,属性值,操作,方法,关联}。因此,知识元识别过程就转化为依据知识元结构模型从叶节点文本片段的内容中分别提取叶节点论述的实体名称、实体属性、属性值、实体操作、实体方法和关系等的过程。知识元的识别过程如图4所示,主要包括句子分割、分词/词性标注、指代消解、依存句法分析、RDF三元组识别和知识元合成等几个步骤。首先,依据句子标识符(如。!?等)对文本片段进行句子分割,识别文本片段中包含的所有语句;接着,对文本片段中的每一个语句进行分词,去除没有实在意义的停用词,并进行词性标注;而后,为能较为全面地抽取与实体相关的信息,对文本片段中的指代现象进行消解;然后,借助依据句法分析对语句中词语之间的关系进行分析,识别语句中主语、谓语、宾语、修饰语等,并进行依存分析;紧接着,依据依存句法分析结果,提取RDF三元组;最后,依据知识元模式,对识别出的三元组进行合并,最终达到知识元识别的目的。
-
3.1.3 语义标注
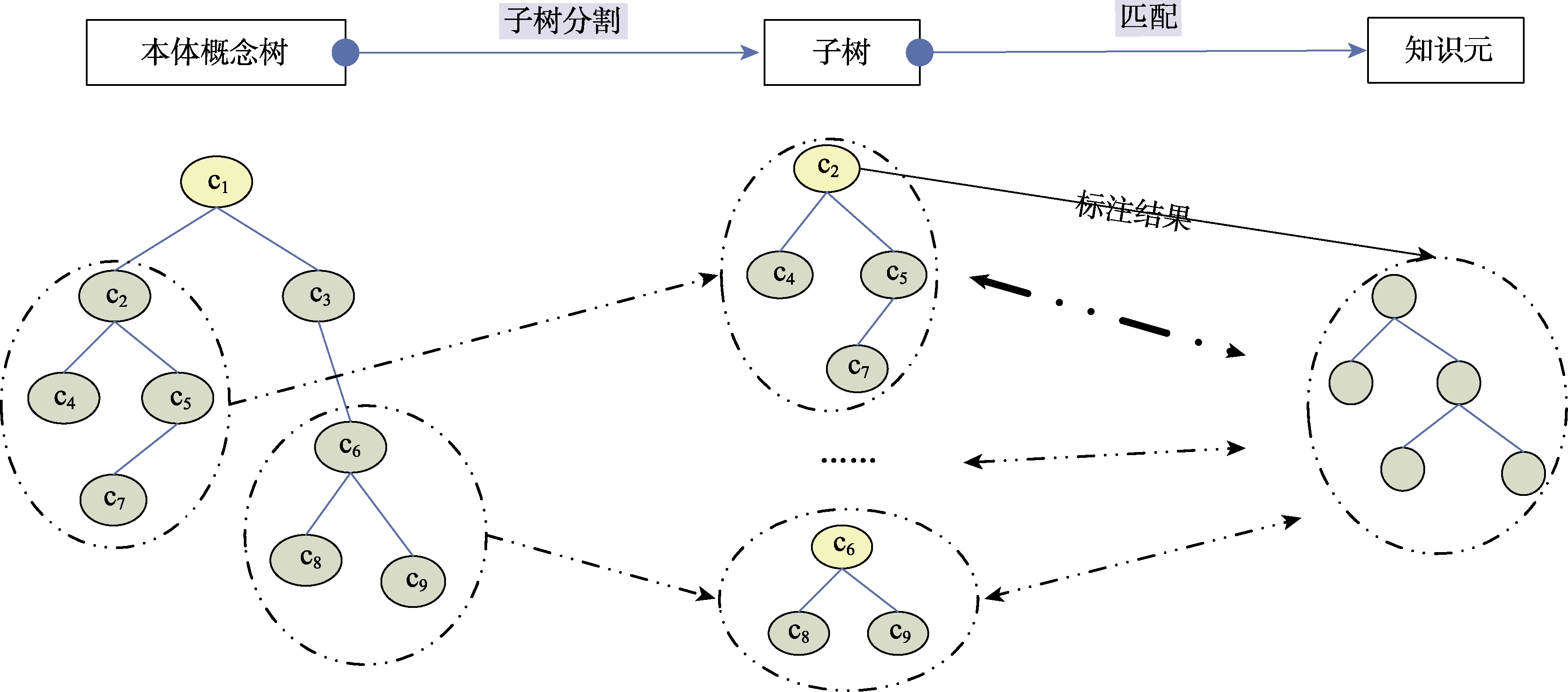
语义标注是建立本体概念与资源实例之间联系的过程,主要任务是通过计算本体概念与资源实例之间的相似度来实现资源实例按本体的分类体系进行归类。在本文中,语义标注的目的是建立知识元中的实体与本体概念之间的映射关系。由知识元结构模型可知,知识元作为无法再分割的最小知识单元,揭示和描述了实体的名称,属性,属性值,操作,方法和关联等,也即是说,知识元本身可以看作是一棵以实体为根节点的树结构。而本体概念树中每一个概念的内涵均可以用以该概念为根节点的一棵子树来表达。由此可见,无论是本体概念还是知识元均体现出树结构,为此,在对知识元进行语义标注时,本文提出基于树匹配的方法实现知识元中的实体到本体概念的映射,以达到语义标注的目的(图5)。从图5可以看出,基于树匹配的知识元语义标注主要包括本体概念树的子树分割、子树与知识元匹配两个阶段。
-
1) 本体概念树的子树分割
子树分割也即识别出本体概念树中所有子树的过程。具体来说,采取深度优先策略,首先抽取本体概念树中一个概念,作为子树的根节点,而后抽取该概念拥有的所有子概念,作为该子树的分支节点,直到叶节点为止,所有这些节点共同构成本体概念树的一棵子树。从子树分割的上述流程可以看出,本体概念树中有多少个节点就有多少棵子树,最大的一棵子树是其本身,最小的子树是单独一个叶节点。图5中的子树列表如表2所示。
-
2) 子树与知识元匹配
由于无论是本体概念子树还是知识元它们均是以根节点为中心,不同的根节点对应不同的子节点集合,这也就意味着如果两棵树的根节点不匹配,那么两个树的其他节点的相似度也会非常低,因此,在进行子树与知识元的匹配之前,首先通过根节点匹配来过滤掉一些不太可能的匹配树将会大大提高匹配的效率。而且在进行本体概念子树与知识元匹配时,除了要计算节点之间的相似性,还要考虑节点之间语义关系的相似性,为此,本文提出一种基于路径的匹配方法。路径是由从根节点通往叶节点的一条完全路径上的所有节点组成,路径的相似度由路径上节点的相似度决定,并且各节点对于路径相似度的贡献不一样,本文认为越靠近底层的节点贡献度越大,这是因为在本体概念网络中,越是靠近底层的概念越专指,表达的含义越明确。
具体来说,设s=([p1,w1], [p2,w2], [p3,w3],…,[pm,wm])为具有m个节点的路径,其中pi为路径s中从根节点开始第i个节点,wi为该节点的权重。s1,s2为两条路径,k为路径s1,s2中相匹配的节点个数,则路径s1,s2之间的匹配度的计算公式为
(1)
设T1、T2为两棵待匹配的子树,通过公式(1)可以得到子树T1与T2中相匹配的路径,设相匹配的路径个数为q,则子树相似度的计算公式为
式中,
通过本体概念子树与知识元的匹配,可以得到与知识元最匹配的本体概念,最终实现知识元的语义标注。语义标注的结果是生成一个面向知识元的概念树,概念树中下位概念较为专指,能够揭示较为细粒度的文本片段的主题,如概念树中叶结点仅揭示了一个知识元的主题内容,而上位概念则相反,能够揭示较为粗粒度的文本片段的主题,如根节点是最泛指的概念,揭示了整个文献论述的主题,其包含所有的知识元。
-
3.1.4 多粒度关联数据创建
通过语义标注实现了将非结构化的数字馆藏资源结构化的目的,这些结构化的数据是实现关联数据创建的基础。有了这些数据,数字馆藏资源的多粒度关联数据创建就变得较为简单,总的来说,主要是依据关联数据的基本原则,对语义标注的结果进行关联数据化。具体来说,多粒度关联数据创建主要包括以下几个步骤:多粒度关联数据建模、实体命名、实体RDF化和实体关联化几个步骤。其基本流程是:首先,依据语义标注生成的概念树为多粒度关联数据建模,达到定义RDF词表和揭示实体之间语义关系的目的;然后,进行实体命名,为每个实体赋予一个URI,以便标识和检索实体;接着,借助RDF对实体进行描述,达到实体RDF化的目的;最后,依据概念树所揭示的概念之间的语义关系,实现实体之间的关联化,完成关联数据的创建。多粒度关联数据创建的结果是生成数字资源多粒度关联数据。
-
3.2 多粒度关联数据索引
多粒度关联数据索引是实现多粒度关联检索的核心,其主要功能是建立多粒度关联数据的倒排文档(也即索引)供检索模块检索使用。多粒度关联索引的实现过程主要包括两个基本步骤:实例索引和类索引。索引采取自下而上的策略,也即首先对实例进行索引,而后,基于实例索引结果对类进行索引。实例索引是最细粒度的索引,索引的基本单位是知识元。类索引是更粗粒度的索引,索引单位与概念所处的层级相关,越是上位概念包含的知识元越多,索引的粒度越大,反之,越是下位概念包含的知识元越少,索引的粒度越小。
-
3.2.1 实例索引(知识元索引)
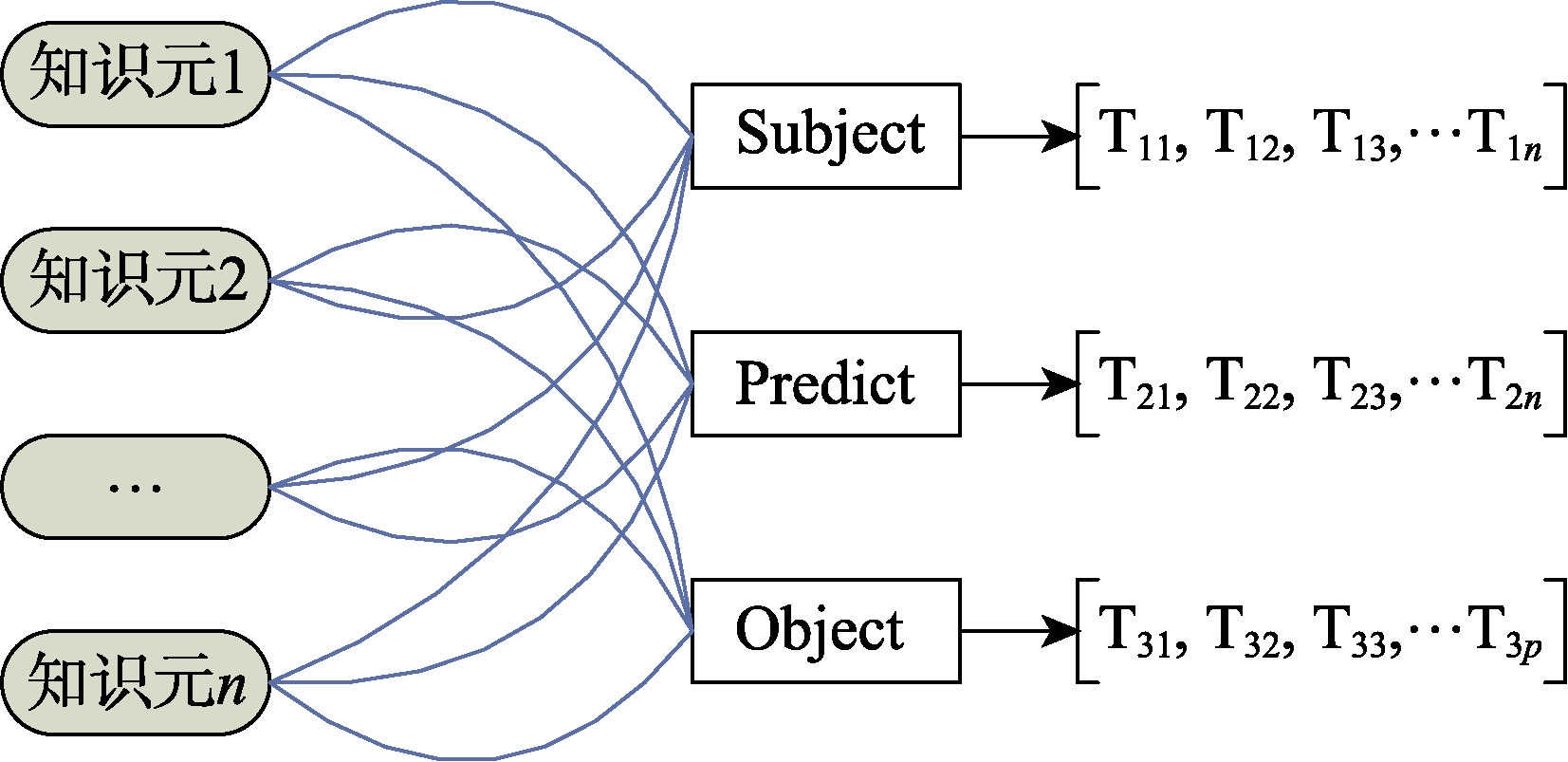
实例作为类(即:概念)的实例化对象(即:外延)主要是由知识元构成。由知识元结构模型可知,每一个知识元都被描述成为一个RDF图,该RDF图由多个RDF三元组<subject, predict, object>构成。基于上述分析,本文提出了如图6所示的知识元索引模型。由图6可知,对知识元的索引转变为对知识元中所包含的RDF三元组的索引,即,以知识元内所有RDF的主体、谓词、客体中包含的语词为关键词,以知识元所在的文本片段地址为出处,构建倒排文档。知识元索引的结果是生成三个倒排文档(也即索引):主体倒排文档(subject索引),谓词倒排文档(predict索引)和客体倒排文档(object索引)。通过subject索引可以查找RDF三元组中主体所在的文本片段
T1 i,同理,通过predict索引可以检索到谓词所在的文本片段T2 j,通过object索引可以定位客体所在的文本片段T3 k,只有同时包含主体、谓词和客体的文本片段才是知识元所在的文本片段,从而实现对知识元的索引。 -
3.2.2 类索引(概念索引)
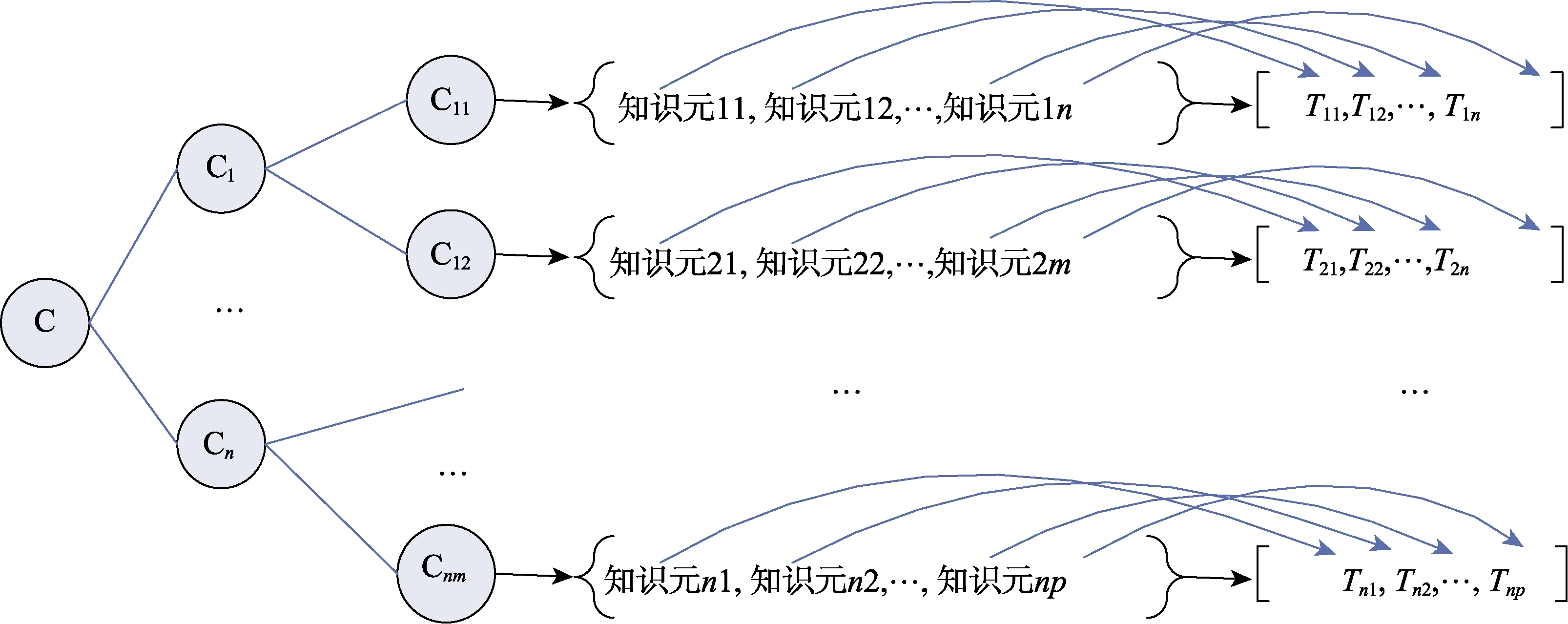
类对应于关联数据的概念层,主要是由RDF的schema也即RDFS构成。概念层是对文本片段中的知识元进行语义标引后所得到的一种概念层次结构。概念层次结构中的每一个节点均是从文本片段中抽取的能够概括其子节点共同特征的主题词。因此,类索引与实例索引不同,其索引的基本单位随着概念的抽象程度不断变化,越是抽象的概念内涵越广,包含的下位概念越多,对应的文本片段也越多,索引粒度越大;反之,越是具体的概念内涵越小,包含的下位概念越少,对应的文本片段越少,索引粒度也越小。类索引的这一特性给索引造成了不小的困难。为解决这一问题,实现概念层的多粒度索引,本文提出构建多层索引的思路。具体来说,在对知识元进行索引的基础上,构建概念→知识元索引,该索引起到链接概念与知识元的作用,而后,通过知识元索引,最终达到定位与概念相关的文本片段的目的,实现多粒度关联索引。通过类索引,建立的是一个概念索引树(如图7所示)。该概念索引树主要由三部分构成:概念树、概念→知识元索引表、知识元索引表。通过搜索这个概念索引树可以迅速查找定位到不同粒度的文本块,进而实现多种粒度的概念检索。可以依据概念树所揭示的概念之间的语义关系扩大或缩小检索结果的粒度。在概念树中,越靠近根节点的概念越泛指,内涵越广,因此其对应的文本粒度也就越大,反之,越靠近叶节点的概念越专指,包含的内容越小,因此其对应的文本粒度也越小。
-
3.3 多粒度关联数据检索
-
3.3.1 检索方式
-
3.3.1.1 检索模式
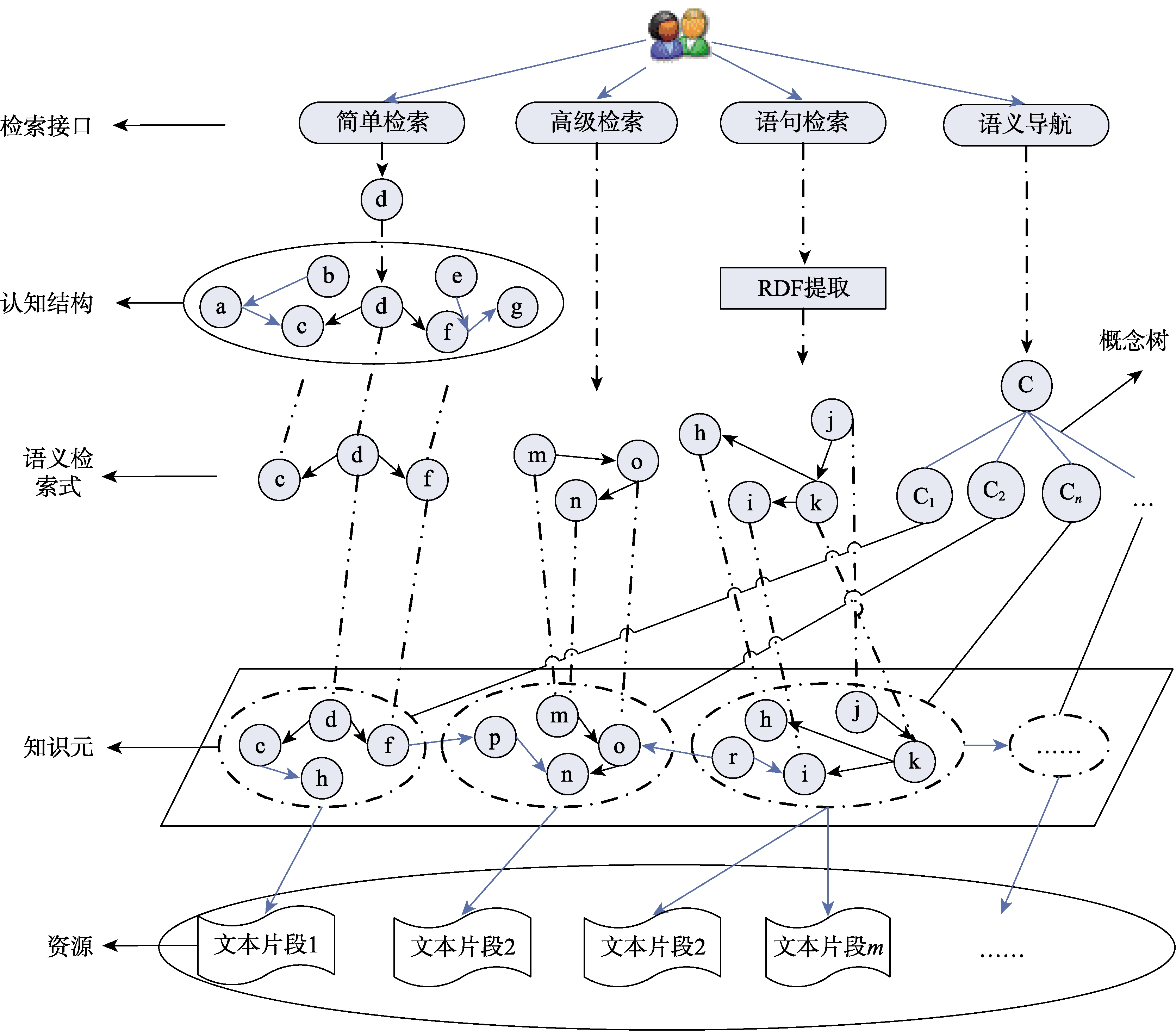
自然语言表达方式灵活多样,并且不同的人具有不同的认知结构,这就使得相同的需求不同的人往往采用不同的表达形式进行表达,然而,当前的搜索引擎大都又是基于关键词匹配,这往往会造成检索结果的不一致性,甚至检索不到自己所需要的结果。此外,对于基于关键词的检索来说,用户通常需要经过多次的检索才能定位到需要的相关知识。这是因为用户的知识需求在初始状态通常是模糊的,难以用一个或几个孤立的关键词来确切表达自己的需求,往往需要使用某种语义方式才能准确描述。基于上述分析,本文提出多粒度语义关联检索和语义导航模式(图8)。多粒度语义关联检索又分为基于用户认知结构的简单检索、高级检索和句子检索。在基于用户认知结构的简单检索时,系统会首先将用户输入的关键词与用户的认知结构进行匹配,找出与该关键词相关的其他概念组成RDF三元组,而后基于该三元组进行检索,由于该三元组提供了用户输入的关键词的语义信息,因此可以较大提高检索的准确性。高级检索为用户提供了直接输入语义信息的检索接口,用户可以直接输入<主体、谓词、客体>进行检索。在句子检索中,用户直接使用一句话来描述自己的知识需求,在检索时,系统会借助RDF提取模块将检索语句自动处理为RDF三元组的形式进行检索。语义导航主要是依据关联数据之间的关联关系,引导用户进行逐级关联检索的方式。
-
3.3.1.2 检索模式中的难点问题
在多粒度语义关联检索和语义导航模式中,主要存在两个难点问题:基于认知结构的简单检索中的用户认知结构的构建问题、语句检索中的问句的RDF提取问题。接下来,本文将详细论述这两个难点的实现过程。
-
认知结构构建
为识别用户的认知结构,本文借鉴激活扩散理论中的激活规则、路径规则、语义距离规则和终止规
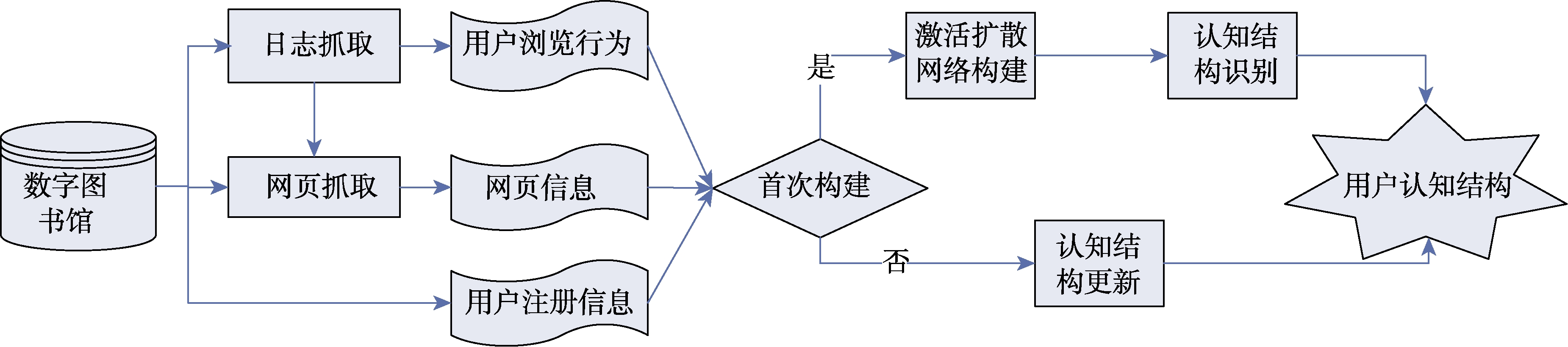
则[11] ,结合用户的知识浏览行为,构造出基于激活扩散的用户认知结构,同时设计了更新机制,以实现用户认知结构的动态更新。具体步骤包括激活扩散网络构建、认知结构识别、认知结构更新等(图9)。激活扩散网络构建:包括识别激活扩散路径节点顺序与计算激活扩散路径节点之间的距离两大内容。其中,激活扩散路径节点顺序可以根据用户访问网页的时间顺序进行构建。而激活扩散路节点之间的路径距离的计算,则采用激活扩散的基本理论,首先利用向量空间模型计算网页节点间距离;然后根据用户访问行为信息中的访问停留时间、网页长度以及用户访问网页的点击率和下载次数等优化节点距离的计算,得到最终的激活扩散路节点之间的距离[公式(3)];最后整合激活扩散路径节点顺序与节点之间的距离,实现用户激活扩散路网络的构建。
(3)
式中,
认知结构识别:需要指出的是通过上述过程构建的激活扩散网络结构的节点是网页,因此,若要基于激活扩散网络结构实现用户认知结构的构建,还需进一步识别这些网页节点所论述的主题。为此,本文借助LDA(Latent Dirichlet Allocation)主题模
型[12,13,14] ,以激活扩散网络中所有的网页作为语料(即文档集合D),识别这些网页(每个文档d)中潜藏的主题信息,进而达到识别用户认知结构的目的。认知结构更新:设
-
问句的RDF提取
在句子检索中,用户输入的检索句主要可以分为两种类型:陈述句和疑问句。如果是陈述句,将其转化为RDF三元组就较为简单,可以直接借助知识元提取的方法来实现,因此这里就不再赘述;如果检索句是问句,那么识别RDF三元组就较为复杂,为此,接下来本文将详细论述问句的RDF三元组的提取问题。
(1)问句的类型。通过问句的分析发现,用户问句的焦点均是围绕实体展开的。有的是已知实体属性的相关信息,咨询拥有该属性的实体是什么;有的是已知实体是什么,咨询该实体某个属性的相关信息;有的是已知多个实体,咨询这些实体间的关系是什么。依据上述分析,本文依据问句中包含的实体个数(n)将问句分为三种类型:实体问句(n=0)、属性问句(n=1)和关系问句(n>1)。三种问句分别对应三种不同的RDF三元组模式,详见表3。
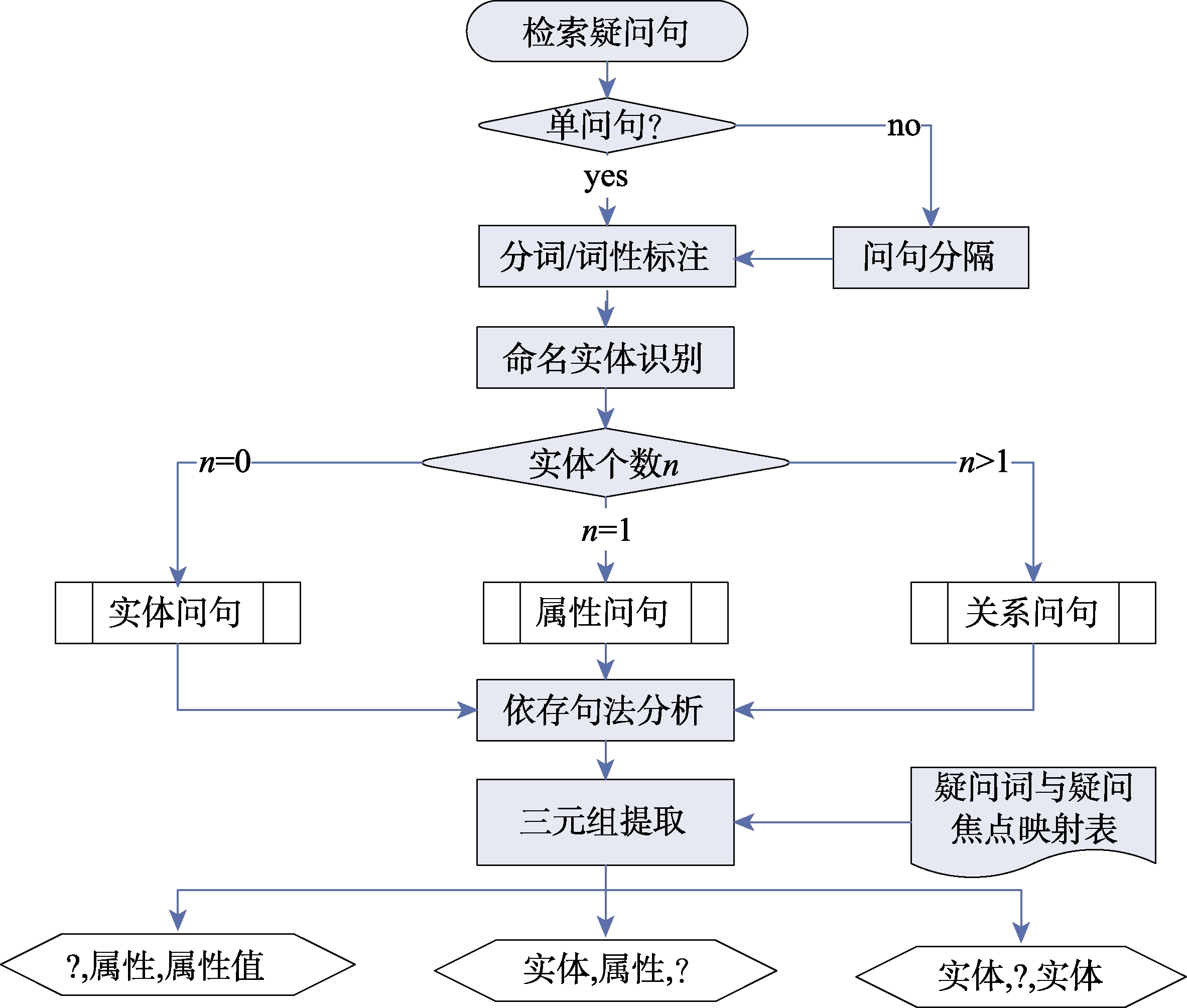
(2)RDF三元组的元素提取。基于对问句类型的划分,本文提取如图10所示的RDF三元组的元素提取方法。从图10可以看出,RDF三元组的元素提取流程:首先,对用户输入的检索问句进行分析,判断是单问句还是多问句,如果是多问句,则借助问句分隔模块将多问句分隔为多个单问句,如果是单问句则直接进入下一流程;紧接着,对每个单句进行分词/词性标注,并去除没有实在意义的停用词;而后,借助命名实体识别模块,识别出问句中包含的实体,并依据实体的个数对问句的类型进行划分;接着借助依存句法分析模块对各问句中的元素进行依存关系分析;最后,依据问句中元素的依据关系及疑问词与疑问焦点的映射表提取RDF三元组中的元素,实现问句的RDF三元组的提取。
在图10所示的流程中,问句分隔、分词/词性标注、命名实体识别、依存句法分析等均有较为成熟的方法和技术来实现,本文就不再赘述。而三元组的提取除了借助依存句法分析识别问句中的<主、谓、宾>外,另一个重要的问题就是识别或明确问句的疑问焦点是什么。通常来说,问句中有多少个疑问词就有多少个疑问焦点,这是因为这些疑问词是用户最想了解的知识,自然也就成为问句的焦
点[15] 。因此,问句疑问焦点的识别就应该以疑问词为中心,具体来说,主要分为两种情况:首先,若疑问词后紧跟一个名词,则该名词为疑问焦点,对于这类问句疑问焦点可以通过依存句法分析进行识别。其次,若问句中只有疑问词,就很难通过语法上的分析来明确疑问词所表达的疑问焦点是什么,如“中国家庭的平均收入是多少?”,在该问句中“多少”的意思是数量的多少,因此疑问焦点是“数量”,而在问句中并没有出现“数量”这个词,因此,无法明确疑问焦点的内容是什么。为解决这一问题,本文在文献[16]的研究基础上,通过对疑问词的归纳分析,构建了一个疑问词与疑问焦点的对照表(表4),以达到明确疑问词疑问焦点的目的。 -
3.3.2 检索结果的排序算法
为提高检准率,本文依据关联数据的特征提出一种面向关联数据检索的索引排序算法[公式(5)],在该排序算法中,检索结果相关度的得分主要由三部分决定:检索词相关度、实体概念的重要程度和关联数据出处权值。
式中,c为实体概念,q为用户输入的检索式,t为检索式包含的检索词,TF.ILF(t)用来测度检索词的相关度,TR(t)表示实体概念的重要程度,P(t)表示关联数据出处权值。
-
1) 检索词相关度
检索词的相关度主要是衡量用户输入的关键词与关联数据的相关性程度,本文使用TF.ISF[公式(6)]来评估检索词t与知识元所在的文本片段的相关性程度,其中
-
2) 实体概念的重要程度
关联数据本身是一个有向网络结构,对于网络中某个实体概念节点来说,依据链接的方向,可以将关联数据中关系的类划分为顺向关系和逆向关系两种。一个实体概念节点的顺向关系越多说明以该实体概念结点为主体的RDF三元组越多,因此也就越重要,反之,逆向关系越多意味着以该实体概念为客体的RDF三元组越多,重要性越低。因此,关联数据中关联数据中实体概念的重要程度主要是由其在网络中的关系决定。基于上述分析,实体概念ci的相对重要性程度可以通过递归公式(7)进行计算。其中L(cj)是指概念cj的逆向关系个数,TR(ci)为ci的TripleRank值,n为顺向关系个数。
-
3) 出处权值
出处是知识的来源之处,出处的权威程度也即出处权值在一定程度上能够反映其所包含的知识的重要性程度。通常来说,出处越权威,知识的可靠性和价值也就越大。而出处的权威性主要体现在两个方面:出处内容本身的影响度、出处作者的影响程度。前者可以用影响因子(也即IF
)[17] 来衡量,后者可以用H指数来计算(本文采用标准H指数)[18] 。为此,实体概念c的出处(provenance)权值P(c)可以通过公式(8)进行计算: -
4 实验及结果分析
-
4.1 实验数据
为在一定程度上保证实验的可实施性以及实验数据集合的全面性和代表性,本文选择了“藏书建设和馆藏组织”这一主题领域。而后依据数字馆藏资源的篇幅将其划分为三种类别:①结构清晰、篇幅较短的馆藏数字资源,如期刊论文等;②结构清晰、篇幅较长的馆藏数字资源,如学位论文、图书等;③结构模糊、篇幅较短的馆藏数字资源,如报纸等。最后,以CNKI为数据源,从第一个类中检索得到与“藏书建设和馆藏组织”相关的期刊论文1021篇,会议文献15篇;从第二个类中检索得到硕博论文28篇;从第三个类中检索得到报纸39篇。这些数据共同作为系统的实验数据。
-
4.2 原型系统
本文采用了lucene检索源码来实现索引和搜索,整个系统运行在java平台下。基于关联数据的数字图书馆多粒度集成知识服务系统是一个javaweb项目,在tomcat 7.0 server上运行。以浏览器浏览网页的方式打开,检索界面如图11所示。用户可以根据自己的知识需求和对知识需求的了解与把握情况,有目的的选择简单检索(直接输入关键词进行检索)、高级检索(以三元组形式进行检索)、语句检索和语义导航来检索自己所需要的知识。
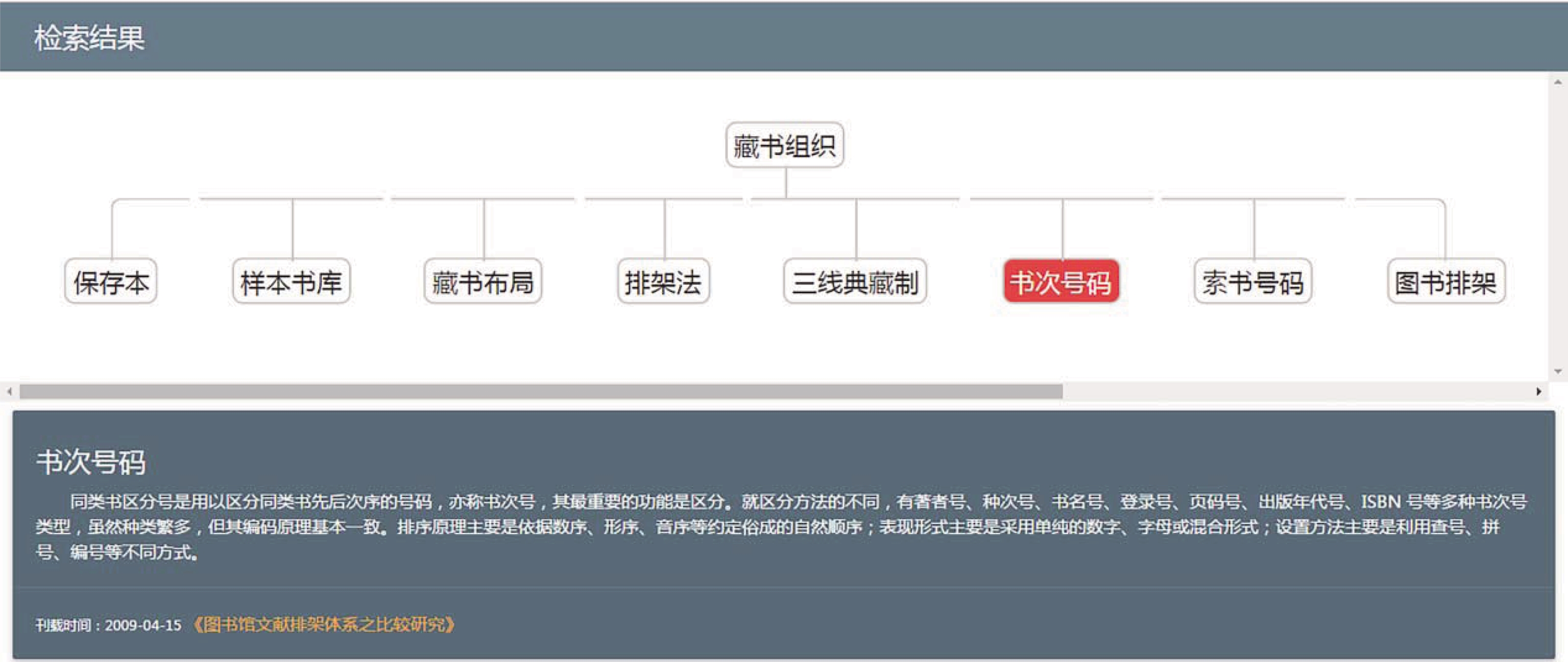
检索结果如图12所示,系统向用户提供了两种检索结果的展示方式。首先,向用户直接展示了与用户知识需求相匹配的知识单元内容本身,也即“书次号码”的知识内容,实现了检索即所得的知识服务,用户不需要继续自己阅读查找自己所需要的知识内容。此外,为满足用户对知识内容相关信息的获取,检索结果中还向用户提供了“书次编号”这一知识内容的出处《图书馆文献排架体系之比较研究》和出版时间“2009-04-15”。点击知识内容的出处便可以帮助用户获取知识的载体(如图13所示),方便数字图书馆用户获取知识的原始出处信息和下载全文,出版时间可以帮助用户了解知识内容出版的时间。其次,上方的动态关联图向用户展示了“书次编号”的相关知识内容,如粗粒度的“藏书组织”、同级的“保存本”、“样本书库”和“藏书布局”等。由于“书次编号”是最细粒度的知识元,因此,在动态关联图中无法展示出更细粒度的知识单元。由此可见,动态关联图不但揭示了与“书次编号”相关联的知识节点之间的语义关系,而且以多粒度的方式向用户提供了集成知识服务。
-
4.3 系统评价方法
为较为全面地对本课题提出的基于关联数据的数字图书馆多粒度集成知识服务系统的性能进行评价,本课题提出面向检索任务的两种评价方法:主观评价方法和客观评价方法。所谓面向任务是指让数字图书馆用户完成某个检索任务,通过数字图书馆用户在完成任务时的体验、操作以及完成任务的效果来达到对系统评价的目的。基于上述分析,为尽可能覆盖数字图书馆用户多种类型的知识检索需求,本课题设置了5个具体的检索任务,如表5所示。
5个问句分别表示了5个不同的检索任务,检索任务
Q1 是获取定义类型的知识;检索任务Q2 是获取事实类型的知识;检索任务Q3 是获取关系类型的知识;检索任务Q4 是获取数值型知识;检索任务Q5 是获取方法类型的知识。 -
4.3.1 主观评价方法
主观评价方法是一种通过对数字图书馆用户的使用体验进行分析,达到对系统性能综合评价的方法。包括以下几个步骤:
(1)邀请30位数字图书馆用户(包括15个本科生、10个硕士研究生和5个博士研究生)作为实验对象,对基于关联数据的数字图书馆多粒度集成知识服务系统(简称:MIKS)进行主观评价。
(2)挑选3个人们常用的知识检索工具:百度知道、百度学术、CNKI作为参照系统,评价MIKS系统的使用效果。
(3)30位实验对象分别借助3个参照系统和MIKS系统完成表5所示的5个检索任务,并记录每个实验对象借助各检索系统完成每个检索任务时点击鼠标的次数。
(4)完成检索任务之后,30位实验对象被要求立即填写表6所示的用户体验表。该表依据李克特5分法将用户的满意程度分为5个级别:“1”表示“特别不满意”、“2”表示“不满意”、“3”表示“一般”、“4”表示“满意”、“5”表示“特别满意”。
(5)依据每位实验对象的体验得分,借助公式(9)分别计算每个检索系统在5个检索任务中的用户满意度得分的归一化值(用A表示):
式中,Ai表示第i个检索任务的用户体验得分的归一化值;qij表示第j位实验对象在完成第i个检索任务时的体验得分。
(6)借助公式(10)分别计算实验对象借助每个检索系统完成每个检索任务时的平均点击次数。
式中,i为所有检索任务中的第i个检索任务;pij表示第j位实验对象在完成第i个检索任务时的点击次数。
(7)根据实验对象对每个检索系统主观评价的体验得分的归一化值和每个检索系统的平均点击次数,对每个检索系统的性能进行定性分析,得出主观评价结果。
-
4.3.2 客观评价方法
客观评价方法不带有任何个人的感情色彩,评价方法包含以下几个评价指标。
(1)查准率。计算公式为
式中,P表示查准率;X表示准确查找到的与用户知识需求相匹配的知识个数;Y表示反馈回来的所有知识的总个数。
(2)查全率。用R来表示查全率,用N表示检索到的相关知识的个数,用M表示系统中全部相关知识载体的总个数,则查全率可以表示为
(3)F-测度。F-测度是对查准率和查全率的综合考虑的结果,它是通过将查准率(P)和查全率(R)两者进行加权平均,取得的均衡的结果,计算方法为
-
4.4 实验结果分析
-
4.4.1 主观评价结果及分析
依据基于关联数据的数字图书馆多粒度集成知识服务系统主观评价方法的具体流程,获得了完成不同检索任务(
Q1 ,Q2 ,Q3 ,Q4 ,Q5 )时的用户平均点击次数和平均体验得分。接下来,将详细分析各个实验结果。 -
1) 完成检索任务Q1时的实验结果及分析
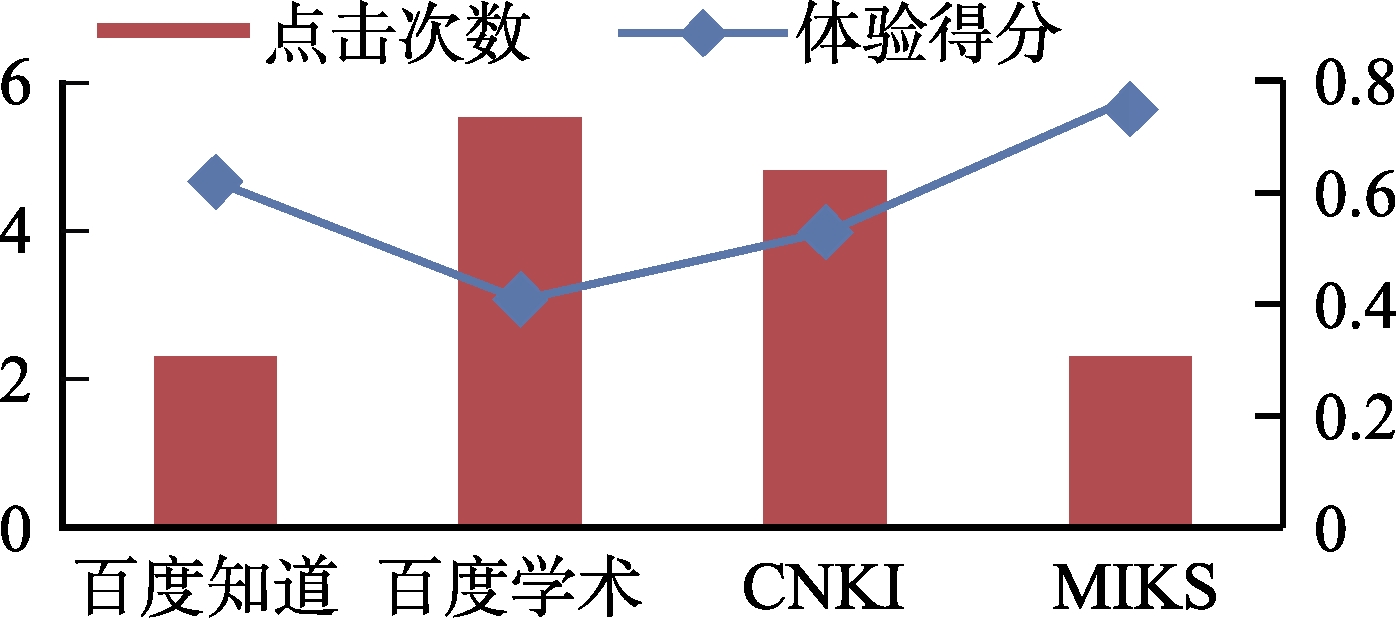
从图14可知,在完成检索任务
Q1 时,从用户体验得分来看,MIKS>百度知道>CNKI>百度学术(即0.75>0.62>0.53>0.41);从平均点击次数来看,百度学术>CNKI>百度知道>MIKS(即5.5>4.8> 2.3=2.3)。之所以得到上述实验结果,通过分析发现原因主要在于:①检索任务
Q1 的目的是获取一个概念类型的知识,四个知识检索系统均包含这种类型的知识,因此都在一定程度上获得了较好的用户体验。②百度知识和MIKS都是直接面向知识内容本身的知识检索系统,用户可以通过它们直接获得自己所需的知识内容本身,因此,用户只需要点击较少的次数就可以获得自己所需要的知识内容,这也意味着用户使用这些知识检索系统的认知成本较低,从而获得了较高的用户体验得分,而MIKS的用户体验得分稍微高于百度知道,这是由于MIKS的知识资源来源于数字图书馆,知识资源大都经过专家的评审,质量较高,而百度知道的知识资源主要来源于网络用户,不仅网络用户的知识水平参差不齐,而且知识内容本身未经第三方审核,因此知识资源的质量无法得到保障。③百度学术和CNKI作为知识检索系统,与百度知道和MIKS不同,其向用户提供的是知识载体的线索,如文献题名、摘要、作者、出版年等信息,用户若想获得他们所需的知识内容,需要进一步依据这些信息获取知识载体(文献),然后通过用户对文献的阅读定位查找到自己所需要的知识,这不仅意味着用户要通过多次点击才能获取自己所需要的知识,而且这也无形中增加了用户的认知负担和成本,使得用户体验得分比较低,也即用户对他们的满意度较差。④与使用CNKI相比,数字图书馆用户通过百度学术完成检索任务Q1 需要的点击次数略高,这是由于CNKI作为知识检索系统不仅可以获得知识载体的线索,而且可以依据该线索信息从系统中直接获得知识载体本身,然而在百度学术中,在大多数情况下,检索得到的是二次文献,若要获得知识载体本身,需要进一步链接到其他知识检索系统,如CNKI、万方等。 -
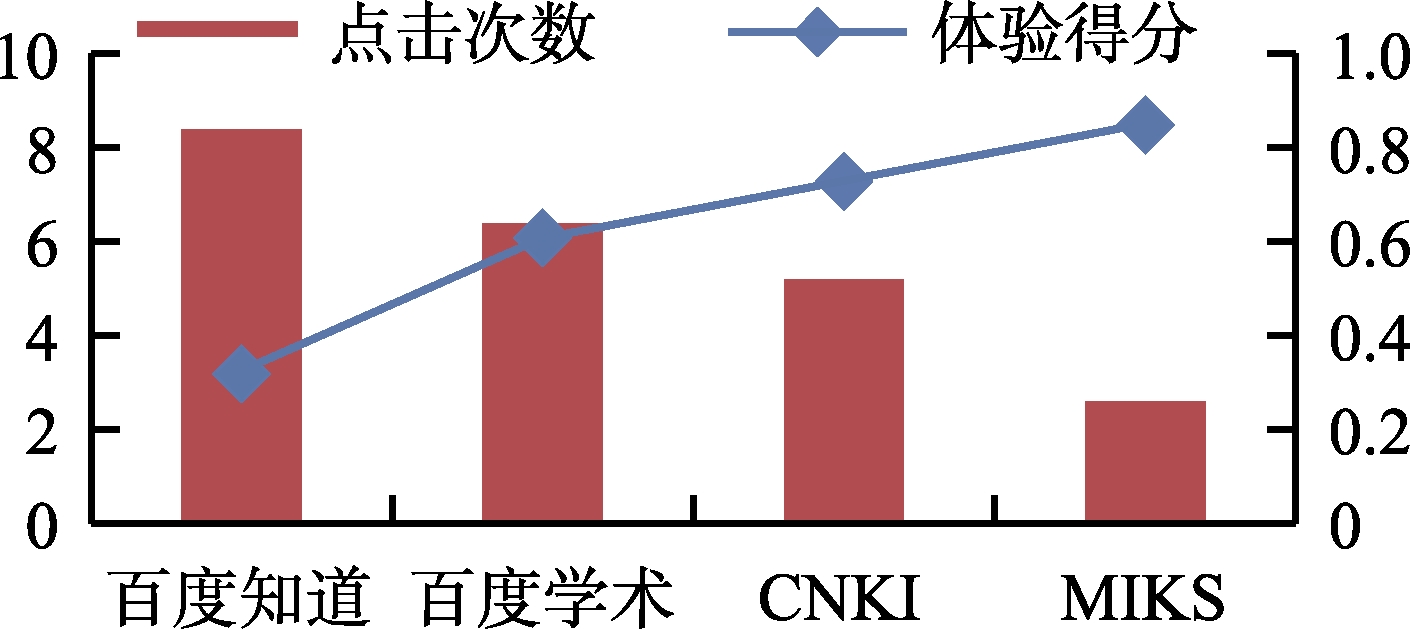
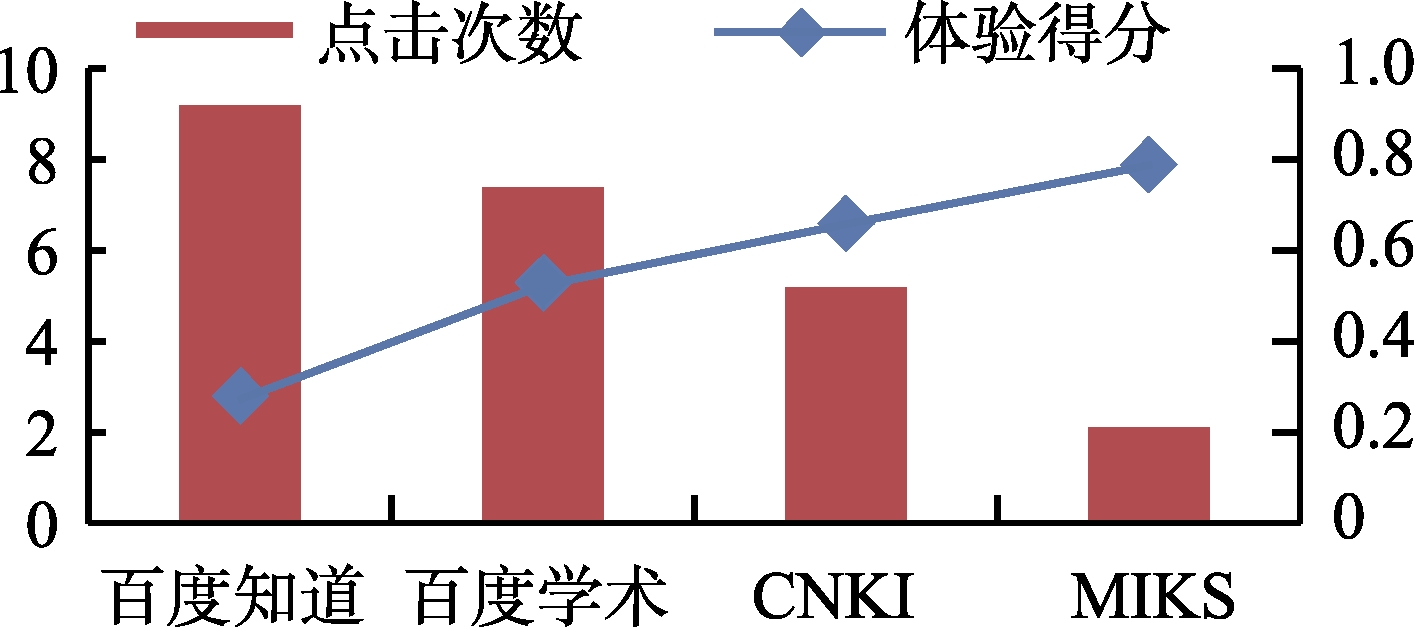
2) 完成检索任务Q2、Q3和Q4时的实验结果及分析
从图15,16,17可知,在完成检索任务
Q2 、Q3 和Q4 时,从用户体验得分来看,MIKS>CNKI>百度学术>百度知道(即Q2 :0.85>0.73>0.61>0.32,Q3 :0.79>0.66>0.53>0.28,Q4: 0.90>0.53>0.41>012);从平均点击次数来看,百度知道>百度学术>CNKI>MIKS(即Q2 :8.4>6.4>5.2>2.6,Q3 :9.2>7.4>5.2>2.1,Q4 :10.3>6.5>5.4>2.2)。之所以得到上述实验结果,通过分析发现原因主要在于:①检索任务
Q2 、Q3 和Q4 的专业化程度很高,而百度知道作为一种通用知识检索系统,未能检索到相关知识内容,因此,不但用户的平均体验得分最低,而且,需要的平均点击次数也最多。②CNKI和百度学术作为专业的知识检索系统收录了大量的专业知识内容,因此可以检索到相关的知识内容,因此用户的平均体验得分较高,用户满意度较好。③与CNKI和百度学术不同,MIKS是直接面向知识内容本身的知识检索系统,用户可以通过它们直接获得自己所需的知识内容本身,因此,用户只需要点击较少的次数就可以获得自己所需要的知识,而CNKI和百度学术由于获得的是知识线索,用户获取知识需要较多的点击次数,从而使得MIKS获得了比CNKI和百度学术更高的用户体验得分。④与检索任务Q2 相比,用户在借助百度知道完成检索任务Q3 时的平均体验得分进一步减低,用户平均点击次数则进一步升高,原因主要在于百度知道较少收录关系类型的知识,用户很难检索到相关的知识内容,而且也没有向用户提供描述关系类型知识需求的检索接口,因此用户的体验得分较低,平均点击次数较高。此外,百度学术的平均用户体验得分和平均点击次数表现出与百度知道相同的变化趋势,主要原因在于百度学术提供的检索方式过于单一,很难帮助用户描述表达关系类型的知识需求。而CNKI和MIKS都提供了描述关系类型知识需求的检索方式,因此获得了较好的用户体验和较少的平均点击次数。⑤借助CNKI和百度学术虽然可以完成检索任务Q4 ,但是,由于CNKI和百度学术均是基于字符匹配的检索方式,无法揭示数值知识的“数值对象、数值、单位”等之间的语义关系,而MIKS则可以通过RDF三元组揭示数值知识的语义关系,用户不仅可以通过高级检索以语义的方式表达自己的知识需求,检索得到自己所需要的数值类型的知识,而且也可以直接通过句子检索表达自己的知识需求,获取自己所需要的数值类型的知识,因此,在获取数值类型的知识时,MIKS表现出了比CNKI和百度学术更加突出的优势,用户只需要花费较少的平均点击次数就可以获得所需要的知识,因此MIKS的平均用户体验得分远高于CNKI和百度学术。 -
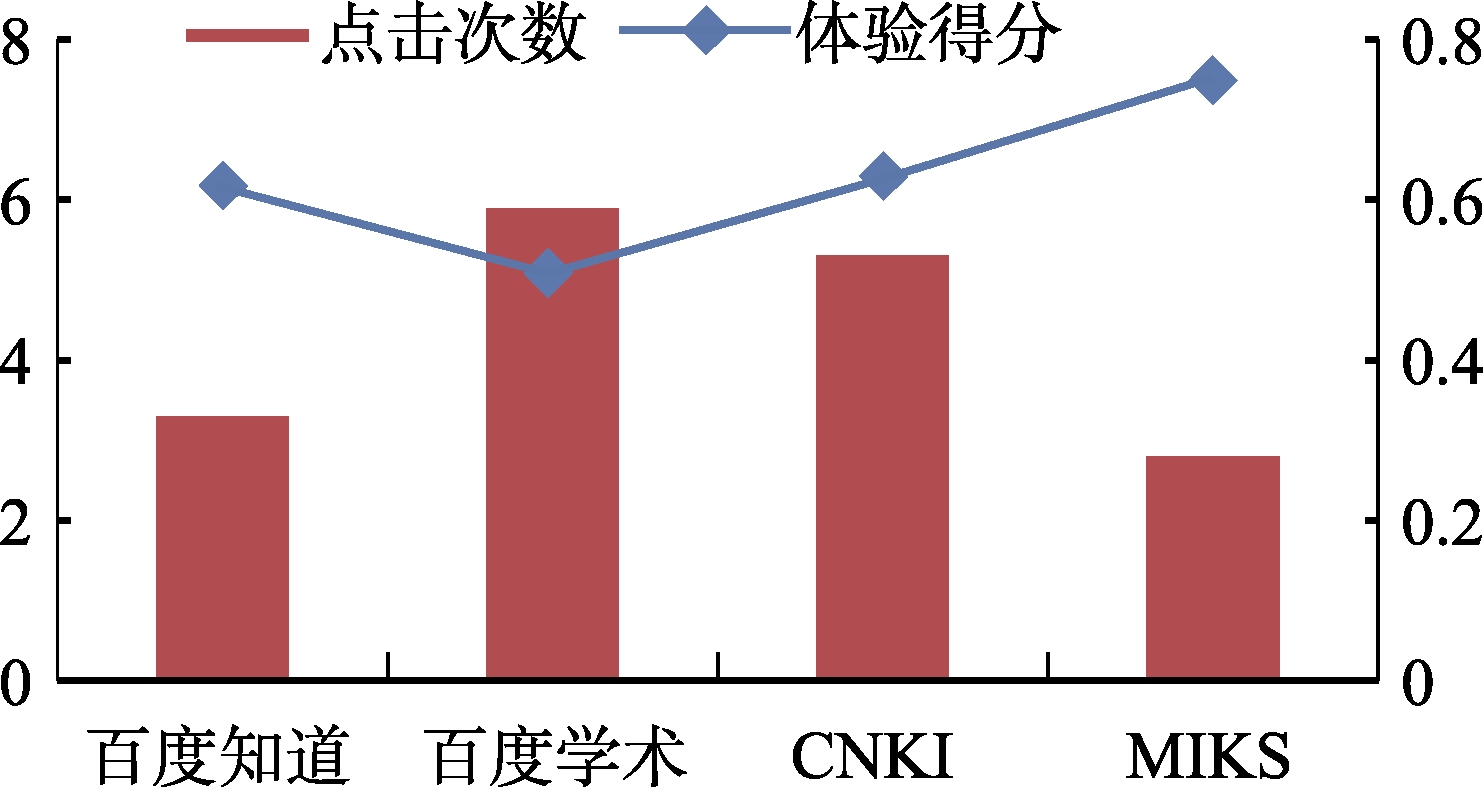
3) 完成检索任务Q5时的实验结果及分析
从图18可知,在完成检索任务
Q5 ,从用户体验得分来看,MIKS>CNKI>百度知道>百度学术(即0.75>0.63>0.62>0.65);从平均点击次数来看,百度学术>CNKI>百度知道>MIKS(即5.9>5.3> 3.3>2.8)。之所以得到上述实验结果,通过分析发现原因主要在于:①检索任务
Q5 的目的是获取一个方法类型的知识,四个知识检索系统均包含这种类型的知识,因此都在一定程度上获得了较好的用户体验。②百度知识和MIKS都是直接面向知识内容本身的知识检索系统,用户可以通过它们直接获得自己所需的知识内容本身,因此,用户只需要点击较少的次数就可以获得自己所需要的知识,这也意味着用户使用这些知识检索系统的认知成本较低,从而获得了较高的用户体验得分。③虽然CNKI与百度知道和MIKS相比需要较多的点击次数才能获得用户所需要的方法类型的知识,但是仍然获得了较高的平均用户体验得分,而且平均用户体验得分虽然低于MIKS,但高于百度知道,这是由于CNKI收录的大都是学术类型的数字资源,包含了大量的方法类型的知识,而且几乎所有方法均经过了实验验证,方法知识的质量较高,因此,尽管需要较多的平均点击次数才能获得所需要的知识,CNKI仍然获得了较高的平均用户体验得分。④在借助MIKS完成检索任务Q5 时,其仍然获得了最高的平均用户体验得分,这是由于,MIKS不仅包含大量的高质量的方法类型的知识资源,而且揭示了方法知识资源之间的逻辑关系。 -
4.4.2 客观评价结果及分析
基于关联数据的数字图书馆多粒度集成知识服务系统三种检索功能(简单检索、高级检索和句子检索)的平均查准率、查全率和F-测度的实验结果如表7所示。
从表7可以看出,在查准率方面,句子检索>高级检索>简单检索(即92%>88%>74%)。在查全率方面,简单检索>高级检索>句子检索(即83%>76%>66%)。在F-测度值方面,高级检索>简单检索>句子检索(即82%>82%>77%)。在平均值方面,三者的查准率的平均值为85%,查全率的平均值为75%,F-测度的平均值为79%。
之所以得到上述实验结果,通过分析发现原因主要在于:①在简单检索中用户只输入一个或多个检索词来表达自己的知识需求,缺乏相应的语境和语义信息,虽然在本课题中通过用户认知结构的挖掘在一定程度上克服了简单检索的语境和语义缺失问题,但由于用户的知识需求又会随着其所处情境的变化而不断变化,从而导致简单检索的查准率较低。然而,由于借助了用户认知结构对用户的检索式进行了语义化扩展,从而使得简单检索的查全率较高。②在高级检索中用户可以通过三元组(<主语、谓词、宾语>)来表达自己的知识需求,与简单检索相比,在表达用户需求方面更为准确,因此获得了较高的查准率,此外,由于用户在通过三元组表达自己知识需求时,可以进行一定的族性检索,如用户可以只在主语和宾语中输入用来表达自己知识需求的检索词,便可以获取在主语和宾语中包含检索词的各种关系类型的知识资源,不管主语与宾语之间是什么关系类型,因此查全率相对较高。③在句子检索中,用户可以通过输入一个检索语句来表达自己的知识需求,与简单检索和高级检索相比能够更加准确地表达用户此时此刻的知识需求,因此句子检索的查准率最高,然而由于检索语句中包含的语义较为丰富,检索的限制条件包含的也最多,从而导致句子检索的查准率相对较低。④从F-测度值来看,高级检索的F-测度值最高,说明高级检索的综合表现最好,句子检索的F-测度值最低,说明句子检索的综合表现一般,而简单检索的F-测度值比句子检索稍高,说明与高级检索相比,简单检索的综合表现也一般。⑤从简单检索、高级检索和句子检索的平均值来看,无论是查准率平均值、查全率平均值,还是F-测度的平均值都高出了70%,因此,尽管本课题提出的基于关联数据的数字图书馆多粒度集成知识服务系统存在一定的缺陷,但在总体上仍然达到了较高的查全率、查准率和F-测度值,在一定程度上验证了基于关联数据的数字图书馆多粒度集成知识服务系统的科学性和有效性。
-
5 结束语
为实现数字图书馆多粒度集成知识服务,本文在对数字图书馆多粒度集成知识服务的理论进行深入分析的基础上,借助关联数据技术提出了数字图书馆多粒度集成知识服务的模型框架。依据该模型框架,本课题开发了基于关联数据的数字图书馆多粒度集成知识服务的原型系统,并通过实验,在一定程度上论证了基于关联数据的数字图书馆多粒度集成知识服务的科学性和有效性。然而,数字图书馆多粒度集成知识服务的关键在于对文献中包含的知识内容依据主题进行多粒度层级分割,以识别出文献中不同粒度大小的知识以及它们之间的关联关系,由于数字图书馆的馆藏资源除包含文本内容以外,还包含诸如图像、表格、音频和视频等多媒体知识内容,这些多媒体中不仅包含更多的知识内容,而且与文本之间的关联关系也较为复杂,很难将其进行主题分割。今后将对数字图书馆馆藏资源中包含的音频、图表、视频等多媒体知识资源的主题分割,进一步深入探讨新的主题分割算法和技术来解决数字图书馆馆藏资源中多媒体知识的主题分割问题,以进一步推进数字图书馆多粒度集成知识服务的发展。
-
参考文献
-
1
文庭孝, 罗贤春, 刘晓英, 等. 知识单元研究述评[J]. 中国图书馆学报, 2011, 37(5): 75-86.
-
2
徐如镜. 开发知识资源,发展知识产业,服务知识经济[J]. 现代图书情报技术, 2002(s1): 6-8.
-
3
马费成. 在数字环境下实现知识的组织和提供[J]. 郑州大学学报(哲学社会科学版), 2005, 38(4): 5-7.
-
4
王子舟, 王碧滢. 知识的基本组分--文献单元和知识单元[J]. 中国图书馆学报, 2003, 29(1): 5-11.
-
5
Berners-Lee T. Linked data[OL]. [2016-05-16]. http://www.w3.org/ Designlssues/ Linked Data.htl.
-
6
游毅, 成全. 试论基于关联数据的馆藏资源聚合模式[J]. 情报理论与实践, 2013(1): 109-114.
-
7
夏翠娟, 刘炜, 赵亮, 等. 关联数据发布技术及其实现——以Drupal为例[J]. 中国图书馆学报, 2012, 38(1): 49-57.
-
8
温有奎. 知识元挖掘[M]. 西安: 西安电子科技大学出版社, 2004: 2.
-
9
原小玲. 基于知识元的知识标引[J]. 图书馆学研究, 2007(6): 45-47.
-
10
姜永常, 杨宏岩, 张丽波. 基于知识元的知识组织及其系统服务功能研究[J]. 情报理论与实践, 2007, 30(1): 37-40.
-
11
Crestani F. Application of spreading activation techniques in information retrieval[J]. Artificial Intelligence Review, 1997, 11(6): 453-482.
-
12
Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003(3): 993-1022.
-
13
Krestel R, Fankhauser P, Nejdl W. Latent dirichlet allocation for tag recommendation[C]// Proceedings of the Third ACM Conference on Recommender Systems. New York: ACM Press, 2009: 61-68.
-
14
石晶, 李万龙. 基于LDA模型的主题词抽取方法[J]. 计算机工程, 2010(19): 81-83.
-
15
尹洪波. 现代汉语疑问句焦点研究[J]. 江汉学术, 2008, 27(1): 92-96.
-
16
许德山, 张智雄, 赵妍. 中文问句与RDF三元组映射方法研究[J]. 图书情报工作, 2011, 55(6): 45-48.
-
17
Garfield E. Citation indexes for science: A new dimension in documentation through association of ideas[J]. Science, 1955, 122(3159): 108-111.
-
18
Hirsch J E. An index to quantify an individual s scientific research output[J]. Proceedings of the National Academy of Sciences of the United States of America, 2005, 102(46): 16569-16572.
-
1
摘要
为将数字图书馆知识服务的单位由文献单元深入到知识单元,并依据知识之间的逻辑关系建立知识单元之间的链接,进而提供多粒度的集成知识服务,本文在多粒度集成知识服务相关理论的指导下,提出了基于关联数据的数字图书馆多粒度集成知识服务方式,主要包括多粒度关联数据创建、多粒度关联数据索引、多粒度关联数据检索等步骤,以实现数字图书馆一站式的“检索即所得”的多粒度集成知识服务,从而提高数字图书馆的易用性,降低用户的认知负担和使用成本。
Abstract
This paper is a study of the multi-granularity integrated knowledge service mode of digital libraries based on linked data. Its aim is to deepen the knowledge service units of digital libraries, turning them from document units into knowledge units; establish links between the knowledge units, according to the logical relationship between them; and then provide a multi-granularity integrated knowledge service based on related theories services. It includes the steps of multi-granularity association data creation, indexing, and retrieval, so as to realize a one-stop multi-granularity integrated knowledge service of “what you retrieve is what you want” in digital libraries, and thus improve the usability of digital libraries and reduce users cognitive burden and use cost.
Keywords
digital library; linked data; knowledge element; indexing; knowledge service