-
1 引 言
命名实体识别是自然语言处理的一项基本任务,其结果广泛应用于语义标注、问答系统、对检索结果的后处理以及知识库的扩展等方面。尽管命名实体识别经过多年理论和实践的发展,目前已经相对成熟,但现有的命名实体识别依然有三个方面可以进一步完善。
一是识别方法的完善。基于规则的方法需要人工编制规则和词典,规则和词典不仅编制费时费力,而且适用面窄、移植性差,需要实现一些自动化技术构建跨领域跨语种的词典以弥补这些不足;基于统计的方法需要依赖由专业人士人工标注的大规模语料库来训练模型,但人工标注难度较大,因而目前可用的语料库相对匮乏,需要能够充分利用互联网中已有的标注数据,发掘新的语料库。
二是结果呈现的完善。现有的命名实体识别结果通常只是简单地呈现文本中包含的命名实体及该实体所属的分类,随着用户需求的不断提升,需要对识别结果进行更详细地解释和描述。
三是将命名实体识别与命名实体消歧有机集合。现有命名实体识别与命名实体消歧是作为两个研究范畴展开的,但是在实际的命名实体识别过程中,对于识别出的每一个命名实体,对该实体的现实身份做出唯一性判断并呈现给用户能够提升命名实体识别的实用性。
关联数据的出现为解决现有命名实体识别的上述不足提供了新的思路。关联数据是W3C(World Wide Web Consortium)推荐的数据规范,用于将网络中的数据发布为机器可读的、具有确切含义的结构化数据。关联数据经过多年的发展,目前已经成为一个丰富的开放知识资源,覆盖了地理、政府、出版、生命科学等多个领域、多个语种,目前关联数据仍在继续发展。
首先,关联数据中包含了大量的命名实体,这些命名实体可以利用现有的技术和工具,转化为命名实体识别所需要的实体词典;其次,关联数据中的命名实体都已经基于本体预先分类,这些经过分类的数据,可以用于训练统计模型;再次,关联数据覆盖领域广,不仅可以满足不同领域对命名实体识别的要求,也可以利用关联数据实现跨领域的命名实体识别;第四,关联数据覆盖语种多,为多语种的命名实体识别的实现提供了新的思路;第五,关联数据不同实体之间基于语义关系相互关联,这种关联能够为命名实体识别过程中的实体消歧提供语义上的支持,使得实体消歧的过程更容易实现,消歧结果也更易于解释;最后,关联数据对实体有着丰富的属性描述,利用这些属性描述能够丰富命名实体识别结果的呈现形式,也为命名实体的后续利用提供了更多的可能。
将关联数据与命名实体识别相结合,利用关联数据作为命名实体识别过程中的背景知识,能够充分发挥关联数据的优势,有效地解决目前已有的命名实体识别方法中存在的问题,同时也能够促进跨领域和多语种命名实体识别更加容易地实现。
-
2 国内外研究现状
通过对国内外相关文献的调研发现,将关联数据与命名实体识别相结合,国外学者已经开展过一定的理论研究,也已经实现了一些原型系统,而国内相关研究目前相对较少。
根据是否对识别过程中出现的实体歧义进行处理,可以将已有研究分为两大类,一类是无消歧的命名实体识别,如X-Lin
k[1] ,对输入文本中的每一个实体指称,X-Link返回与之匹配的所有候选资源,算法本身不对候选资源进行排序或选择;另一类是有消歧的命名实体识别,对文本中的每一个实体指称,获取在关联数据中与之匹配的所有候选资源,通过消歧算法对候选资源进行判别,返回唯一正确的识别结果,多数基于关联数据的命名实体识别都是有消歧的,如DBpedia Spotlight[2] 、NERSO[3] 、AIDA[4] 、AGDISTIS[5] 、FRED[6] 、Zemanta、AlchemyAPI等。根据消歧算法的区别,有消歧的命名实体识别研究可以分为两类,一类是基于相似度的命名实体识别,另一类是基于图的命名实体识别。 -
2.1 基于相似度的命名实体识别
基于相似度的命名实体识别主要利用命名实体指称与候选资源之间的字符串相似度或者上下文相似度对候选资源进行排序,将相似度最高的候选资源作为最终匹配的结果返回。
DBpedia Spotlight是基于DBpedia的命名实体识别系统,系统使用AC自动机算法与关联数据的rdfs:label属性匹配来定位输入文本中的命名实体指称,通过TF-IDF计算候选资源的显著性,利用向量空间模型计算命名实体指称上下文与候选资源之间的主题一致性,进而对候选资源进行综合排序,返回用户需求类型的实体及其对应的URI。经过测试,DBpedia Spotlight识别效果优于Zemanta和Alchemy API等系统。
OBI
E[7] 是基于DBpedia和FreeBase的Twitter命名实体识别算法,算法利用Gate中的ANNIE词典以及抽取自维基百科和DBpedia的词典,基于规则模板,使用模式匹配的方式来定位Tweets中的命名实体指称,利用源自FreeBase API的流行度得分[8] 和基于依存关系树(Dependency Tree)的句法相似度对候选资源进行排序,返回相似度最高的实体及其在DBpedia本体中的分类。通过对BBC新闻、纽约时报和时代周刊三个Twitter账户下115条Tweets在人名、地名和组织名三个类别上进行识别测试,最终结果显示,相比于无消歧的命名实体识别方法,有消歧算法的F值得到了显著提升。Damljanovic
等[9] 利用Gate中的ANNIE和LKB(Large Knowledge Gazetteer)组件定位文本中的命名实体指称,通过rdfs:label和foaf:name属性进行匹配获取实体指称对应的候选资源,通过基于编辑距离(Levenshtein Distance)的字符串相似度、基于实体共现的结构相似度和基于随机索引(Random Indexing)的上下文相似度计算命名实体指称与候选资源之间的相似度,返回相似度最高的候选实体。通过测试发现,ANNIE+LKB+消歧的算法相比于ANNIE和ANNIE+LKB,识别的准确性和F值显著提升,而查全率略有降低。 -
2.2 基于图的命名实体识别
基于图的命名实体识别主要是将命名实体指称对应的候选资源作为节点,基于关联数据之间的相互链接关系构造一张消歧图,利用图的相关算法选择最合适的候选资源作为最终结果输出。
NERSO(Named Entity Recognition Using Semantic Open Data)是基于DBpedia的命名实体识别系统,系统使用滑动窗口的方法将输入文本与实体的rdfs:label、dbont: wikiPageDisambiguates以及dbont:wikiPageRedirects三个属性进行匹配来定位命名实体指称,基于所有命名实体指称对应的所有候选实体之间的关系构建一张有向图,利用中心性得分(Centrality Scoring methods
)[10] 选出每个命名实体指称对应的分值最高的候选资源作为最终结果。通过与DBpedia Spotlight和Zemanta对比,在相同测试集上,NERSO的表现优于其他两个系统。AIDA是基于YAGO的命名实体识别工具,系统使用Stanford NER Tagger定位输入文本中的命名实体指称,不同于其他基于图的算法,AIDA不仅仅是利用候选实体之间的关系构建图,而且把命名实体指称也作为节点纳入图中,具体而言将命名实体指称与相匹配的所有候选资源之间构建“指称-实体”边,将同一命名实体指称对应的候选资源通过共现关系构建“实体-实体”边,以相似度作为边的权重,以节点入链的权重和作为节点的权重,使用贪婪算法不断去掉权重最低的实体节点,直到命名实体指称只存在一条“指称-实体”边,该实体作为该指称的最终对应的结果。
AGDISTIS是一个可以基于不同知识库(关联数据集)进行命名实体识别的系统,使用现成的命名实体识别工具定位命名实体指称,基于rdfs:label属性选取候选实体,基于所有候选资源及其关系构建有向图,使用HITS(Hypertext-Induced Topic Search)计算命名实体指称对应的候选资源的得分,选取分值最高的实体作为最终结果。经过对比测试,基于DBpedia数据集的AGDISTIS相比于DBpedia Spotlight在查全率、查准率和F值三方面表现均更加出色,而基于YAGO的AGDISTIS相比于AIDA略有差距,但是差距很小。
无论是基于相似度的方法还是基于图的方法,目前已有的基于关联数据的命名实体识别研究更多的还是面向英文文本,尽管已有学者对基于关联数据的非英文命名实体识别有所研究,如Nebh
i[11] 将NERSO应用于法语文本,Usbeck等[12] 将AGDISTIS应用于德语、汉语,但总体而言,这方面的研究依然比较少,并且识别效果相比于英文也有所差距。本文希望能在现有研究的基础上更进一步,一方面提升基于关联数据的英文命名实体识别的效果,另一方面对基于关联数据的中文命名实体识别进行一定的探索。 -
3 算法设计与评价
基于关联数据的命名实体识别由于本质上使用的是基于词典的识别方式,因而首先要解决词典的选择问题,即关联数据集的选择问题。截止到目前,LOD项目已有超过1100个关联数据集能够选择和利用,但同时利用如此大规模的数据集,一方面不可避免地存在数据重复,另一方面在数据实时处理上也存在着较大的难度,因而需要基于具体的研究需求选择适当的数据集。
-
3.1 关联数据集选择
已有研究通常使用DBpedia、Yago和FreeBase(若未作特别说明,下文中这三个词汇均代表相应的数据集)作为核心数据集,相比于其他关联数据集,它们具有规模大、领域广、扩展性好的特点。其中DBpedia有其自身的优势:首先,DBpedia会定期更新关联数据,从而能够覆盖越来越多的命名实体;其次DBpedia提供了多语种关联数据的支持,能够满足本文对中英文命名实体识别的需求;最后,DBpedia作为LOD项目的核心数据集,与LOD中的其他关联数据都存在着映射关系,因而DBpedia数据集的扩展性更好。
本文最终选择DBpedia作为核心数据集,采用离线到本地的方式进行组织、存储和利用。由于关联数据集离线文件占用存储空间过大,为了减轻存储和实时查询的负担,本文对DBpedia进行一定地简化处理,对于实体属性描述,仅保留rdfs:label,利用Jena API对实体的中文label和英文label分别进行解析处理,转化为中文和英文命名实体词典;对于命名实体之间的关联关系,全部予以保留,用于后续的命名实体消歧。
为了弥补DBpedia中某些实体与其他实体之间关联关系的缺失,本文使用Yago对DBpedia进行一定的补充和扩展。最终生成的本地数据集中共包含4008340个英文命名实体以及311949个中文命名实体。
-
3.2 算法设计
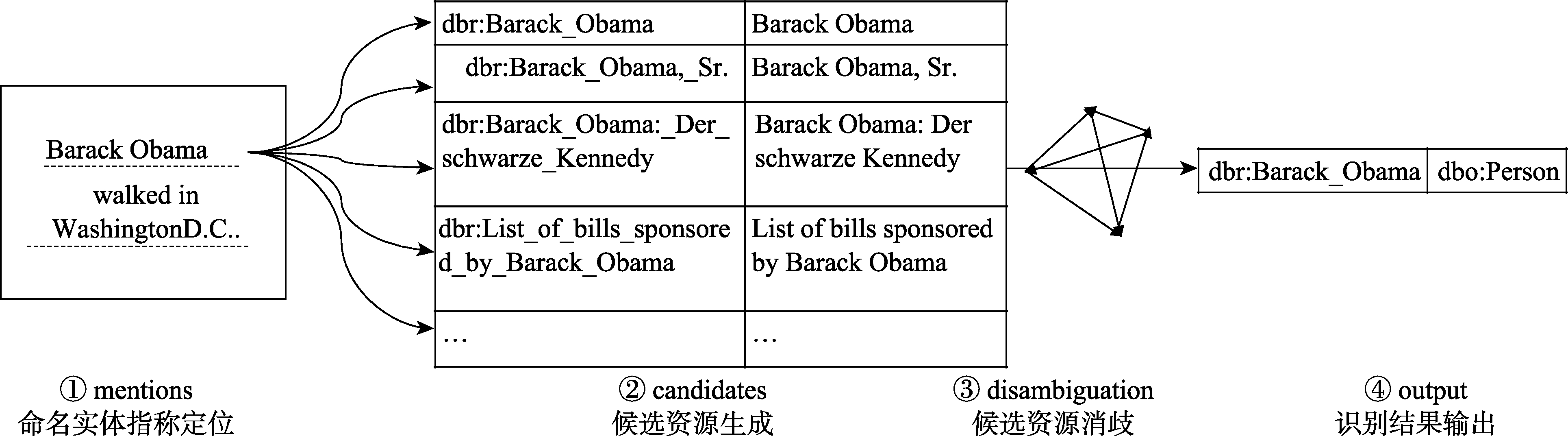
本文的命名实体识别算法分为四步:①定位,识别输入文本中的命名实体指称(mentions);②生成候选资源(candidates),基于rdfs:label属性值生成命名实体指称对应的候选实体;③消歧,对命名实体指称对应的多个候选资源进行判别,选择唯一正确的候选资源;④输出,输出命名实体指称所对应的关联数据实体的URI及其分类。算法执行流程如图1所示。
-
3.2.1 命名实体指称定位与候选资源生成
命名实体指称是指文本中可能代表命名实体的字符串,候选资源是指命名实体指称在关联数据中对应的可能的实体,例如,图1中输入文本里的字符串“Barack Obama”可能代表DBpedia中的dbr:Barack_Obama、dbr:Barack_Obama,_Sr等关联数据实体,因而能够作为命名实体指称,而与其相关联的上述DBpedia实体就是“Barack Obama”的候选资源。
已有研究对于命名实体指称的定位通常使用精确匹配的方式,即将输入文本中的字符串与关联数据中实体的某些属性描述例如rdfs:label、foaf:name等进行精确匹配,获取文本中的命名实体指称,这种方式的优势在于能够确保命名实体指称的准确率,但其最大的问题在于会牺牲命名实体指称及候选资源的召回率,从而影响最终识别结果,例如,给定输入文本为“Barack Obama arrived this afternoon in Washington. President Obama s wife Michelle accompanied him.”,此处命名实体指称“Michelle”如果使用精确匹配的算法在DBpedia中只能匹配到label为“Michelle”的关联数据实体一个候选资源,而无法匹配到“Michelle Obama”等其他候选资源。为了解决精确匹配的不足,本文实现了一种基于滑动窗口的模糊匹配算法定位命名实体指称,在定位命名实体指称的同时直接获取其对应的候选资源的URI和label。算法思路如下。
若输入文本为英文,则利用正则表达式将英文输入文本格式化字符串数组,数组中每一个元素对应一个英文单词。若输入文本为中文,则不对文本进行任何处理,这是由于本文采用了滑动窗口法,该方法采用暴力匹配的方式,即不对文本做任何预处理。
对于处理过的文本,从头到尾依次以每个单词作为首词,取连续N个长度的词组成候选指称与命名实体词典中的实体名进行模糊匹配,若匹配成功,则该候选指称作为一个命名实体指称输出,同时输出DBpedia中与之匹配的所有实体即候选资源的label及URI,并以该候选指称首词的下一个单词作为首词进行下一轮匹配;若匹配失败,则删除当前候选指称中的末尾词,作为新的候选指称重复前面的匹配,直到匹配成功,或者候选指称长度变为0进行下一轮匹配。
其中,N代表命名实体词典中所有命名实体名称的最大长度,在本文使用的DBpedia数据集中,英文实体词典的最大实体长度N为31;中文实体词典的最大实体长度N为12。
由于很多DBpedia实体的label中含有介词、代词或连词,当候选指称仅为单一的这些词时,使用模糊匹配在命名实体词典中会匹配到大量的候选资源,然而大多数时候这些候选资源都是无效的。为了解决这个问题,本文构建一个停用词表,包括那些容易导致无效匹配的词,匹配前对候选指称的首词先进行判断,当首词为停用词时,跳过该候选指称,以下一个单词作为首词进行匹配。
-
3.2.2 候选资源消歧与命名实体识别结果输出
由于很多命名实体指称所对应的候选资源不止一个,因而需要对候选资源进行消歧,即利用特定的算法对候选资源进行判别,选择唯一正确的候选资源作为最终识别结果进行输出。
如前文所述,现有研究主要使用基于相似度的算法和基于图的算法对候选资源进行消歧,相比前者,后者更能发挥关联数据语义链接丰富的优势,因而本文在候选资源消歧中使用基于图的算法。
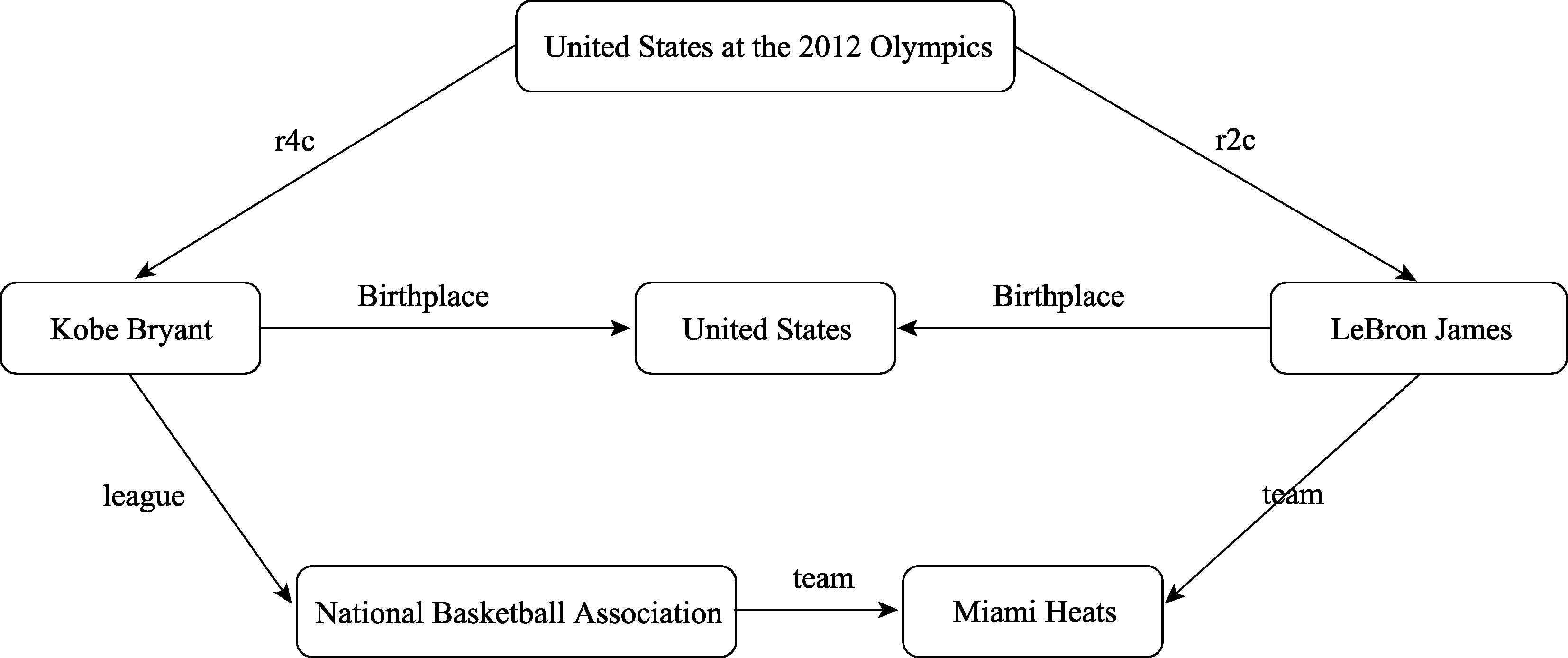
已有研究大多都是仅将所有命名实体指称对应的所有候选资源作为节点,将节点之间的链接关系作为边构造一张有向图,基于节点之间以及节点与边之间的关系计算每一个候选资源节点的权重。这种方法的前提是候选资源之间有足够丰富的链接,但在实际利用DBpedia数据集时发现,如果仅使用候选资源作为节点构造消歧图,很多候选资源并不存在到达其他候选资源的路径,这些节点在消歧图中会成为孤立的节点,最终影响到消歧的效果。而如果在孤立的候选资源节点与其他候选资源节点之间引入新的关联数据实体作为中间节点将其与其他节点连接起来,能在一定程度上解决节点孤立的问题。如图2所示,假设给定输入文本中仅包含两个命名实体指称“Kobe Bryant”和“LeBron James”,这两个实体指称对应的候选资源dbr:Kobe_Bryant和dbr:LeBron_James之间并不存在直接的链接关系,因而无法仅基于这两个节点构造消歧图,此时而如果引入新的关联数据实体dbr:United_States或者是dbr:United_States_at_the_2012_Olympics作为中间节点即可将两个候选资源连接起来。随着中间节点引入数量的不断增加,孤立节点的数量也会越来越少,节点之间的关系也会越来越丰富,如在图2中再引入两个实体dbr:National_Basketball_Association和dbr:Miami_Heats,两个候选资源节点之间的路径变得更加丰富。
基于上述思路,为了将尽可能多的关联数据实体连接起来,减少消歧图中孤立节点的数量,本文将DBpedia中的所有命名实体作为节点纳入消歧图中,基于经过Yago数据集扩展的DBpedia实体关系构造一张命名实体消歧网络。基于关联数据实体网,使用PageRank算法计算每个候选资源的重要性,PageRank算法的优势在于其对于节点重要性的判断不仅依据入链的数量还参考了其质量,能有效降低低质量实体对消歧结果的影响;另一方面,在关联数据一次写入不再修改的情况下,只需使用一次PageRank算法即可获取所有实体的PageRank值,后续消歧过程中可以直接利用已有结果而不需要重新计算节点的PageRank值,因而消歧效率较高。基于PageRank的理念,在关联数据实体网中,越多的关联数据实体链接到某个实体则该实体的重要程度越高,当一个高质量的实体链接到另外一个实体,则被链接到的实体其重要性相应的得到提高。关联数据实体的PageRank值的计算公式为:
式中,PR(T)表示实体
对于PageRank值的求解,本文使用迭代的算法,先赋予每个节点一个随机的非零初值,每迭代一次更新每个节点的PR值,直到节点的PR值稳定即经过迭代后PR值不再发生改变为止。
尽管已经使用Yago对DBpedia中的实体关系进行了补充和扩展,但在实际利用数据集的过程中发现,依然有大量的关联数据实体与其他任何实体之间不存在任何联系,或者仅存在链出关系,而不存在链入关系,基于PageRank算法,这些节点的PageRank值均为0,这会影响到最终的消歧效果。为了解决这个问题,使用编辑距离对算法进行平滑,每个候选资源节点的最终得分由PageRank值和命名实体指称与候选资源的字符串相似度两部分组成,其公式为
式中,
基于节点的最终得分,每个命名实体指称都选择得分最高的候选资源作为其最终结果,输出其URI以及分类。由于对于命名实体指称的定位使用的是模糊匹配的方式,其结果不可避免地存在误匹配的现象,为了在一定程度上缓解这个问题,引入置信度作为判断依据,只有当命名实体指称对应的候选资源的消歧得分超过置信度阈值
-
3.3 算法评价
本文使用DBpedia Spotlight NER Corpus作为测试集对算法进行评价。该测试集由DBpedia Spotlight发布,其测试文本来源于10篇《纽约时报》新闻报道中的60个句子,数据集中共包含249个经过标注的DBpedia命名实体,其中217个实体为有歧义的实体。本文使用查全率(precision)和查准率(recall)以及F值(F-measure)三个指标对算法性能进行评价,并将算法的最优结果与DBpedia Spotlight、Zemanta和NERSO三个成熟的系统进行比较。
首先对置信度阈值
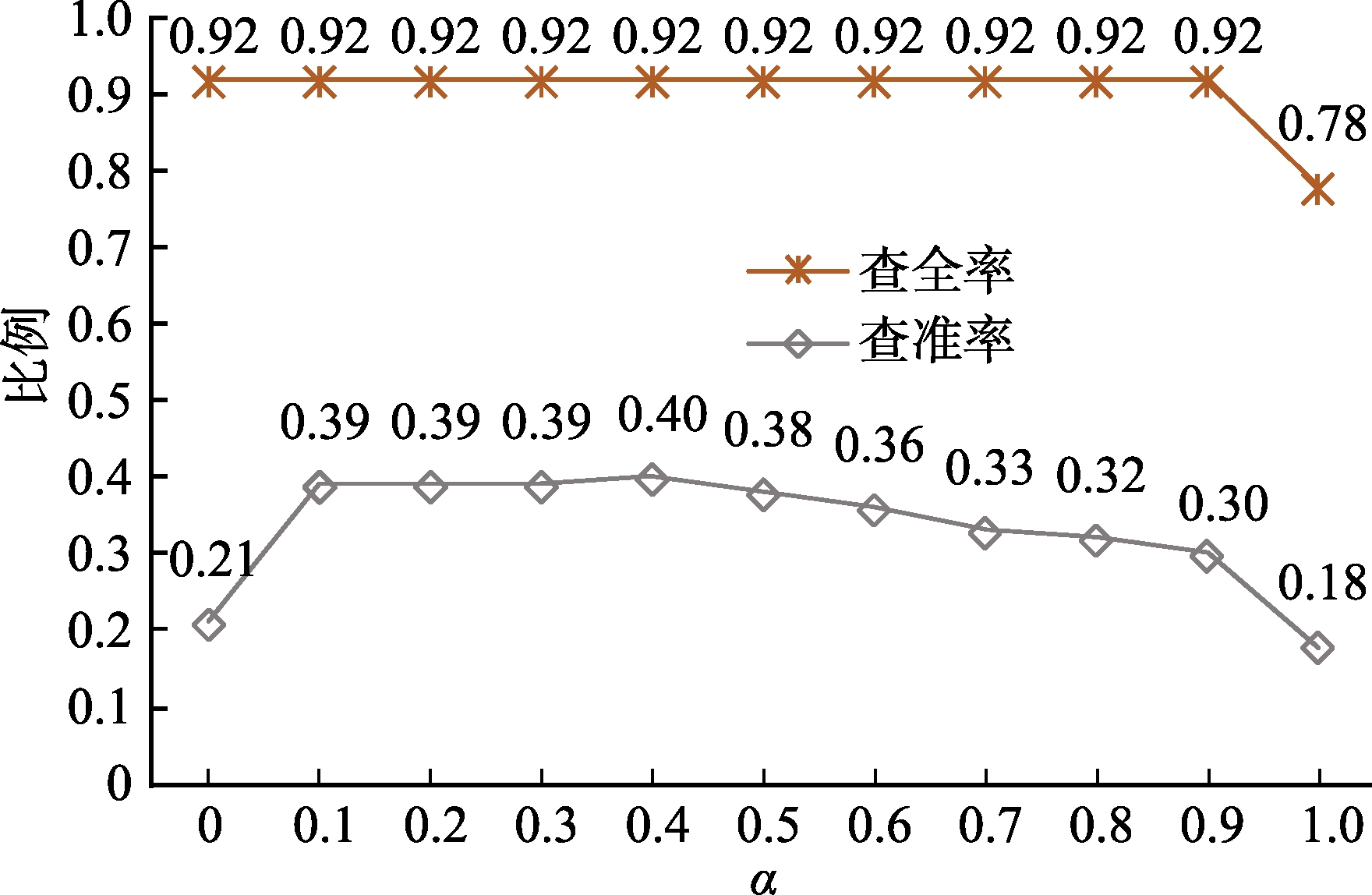
从图3来看,算法在查全率上表现较好,基本维持在0.92,仅当
由于命名实体指称的定位使用模糊匹配的方法,文本中的很多无关字符串会被算法被误判定为命名实体指称,最终影响到算法的查准率。为了平衡查全率和查准率,削弱无效识别的影响,本文在
从图4来看,随着置信阈值
为了进一步对算法效果进行评价,本文选取DBpedia Spotlight和Zemanta以及NERSO三个系统进行比较,已有研
究[2,3] 中已有这三个系统的性能值,并且采用的是同一个测试集。基于同样的测试集,我们得到本文中算法测试的最佳结果,对比结果如表1所示。表1 系统性能比较
系统/算法 查准率 查全率 F值 DBpedia Spotlight默认 0.39 0.45 0.42 DBpedia Spotlight最优 0.80 — 0.56 Zemanta 0.73 0.21 0.33 NERSO 0.42 0.6 0.5 本算法最优 0.51 0.75 0.61 
通过与DBpedia Spotlight、Zemanta和NERSO三个系统的对比发现,本文实现的算法在表现上要更加优秀。在查全率方面,由于使用模糊匹配的算法,表现要优于其他三个系统;在查准率方面,Zemanta和最优配置下的DBpedia Spotlight表现要优于本文的算法,但其高查准率是以牺牲查全率为代价的,Zemanta的查全率在四者中表现最差,仅为0.21。本文算法达到的F值均高于其他三个系统。
-
3.4 总 结
通过对算法的评价发现,本文实现的算法相比已有的基于关联数据的命名实体识别系统,查全率和查准率均有所提升。
在查全率方面,尽管模糊匹配在一定程度上会影响到算法的查准率,但能换来查全率的显著提升。为了降低对查准率的影响,算法一方面通过停用词表的设定在命名实体指称定位阶段排除了部分无效实体指称的干扰,另一方面通过置信度阈值的设定在结果输出阶段限制了可信度较低的结果的返回,最终实现了查全率与查准率之间的平衡。
在查准率方面,利用DBpedia所有实体及实体间的关系构造的命名实体网,能够最大限度地利用实体之间的语义关系,通过中间节点的引入,在实体消歧阶段能够将尽可能多的候选资源连接起来,有效地降低了图中孤立节点的数量,提升了PageRank算法的效果。同时通过引入编辑距离对PageRank算法进行平滑,在PageRank算法失效时通过相似度算法对其补充,最终提升了查准率的表现。
算法评价的不足在于因为目前没有专门用于对基于关联数据的中文命名实体识别进行评价的数据集,因而缺少了对中文命名实体识别性能的评价,后续将通过人工构建评价数据集的方式解决这个不足。而在对英文命名实体识别的评价过程中暴露了算法本身存在两个方面的不足:
一是算法执行速度相比于已有系统存在一定差距。由于对命名实体指称的定位使用的是滑动窗口算法,算法本身的时间复杂度较大,即使对算法已经了进行一定优化,但算法执行速度相较于已有系统而言依然较慢。
二是命名实体指称的匹配机制过于机械。在对算法缺失的匹配结果进行分析时发现,有些命名实体指称与其对应的关联数据实体的label之间存在着较大的差异,例如命名实体指称“gun-possession”对应的关联数据实体为“dbr:Gun_politics”,现有的算法还无法实现这种形式的匹配。
-
4 原型系统设计
现有命名实体识别系统都存在两点不足,一是没有提供可视化的交互手段供用户简单快速地调节系统的运行参数;二是这些系统通常只是简单地输出命名实体识别结果以及实体对应的分类,而缺乏对实体识别结果的详细解释和描述。
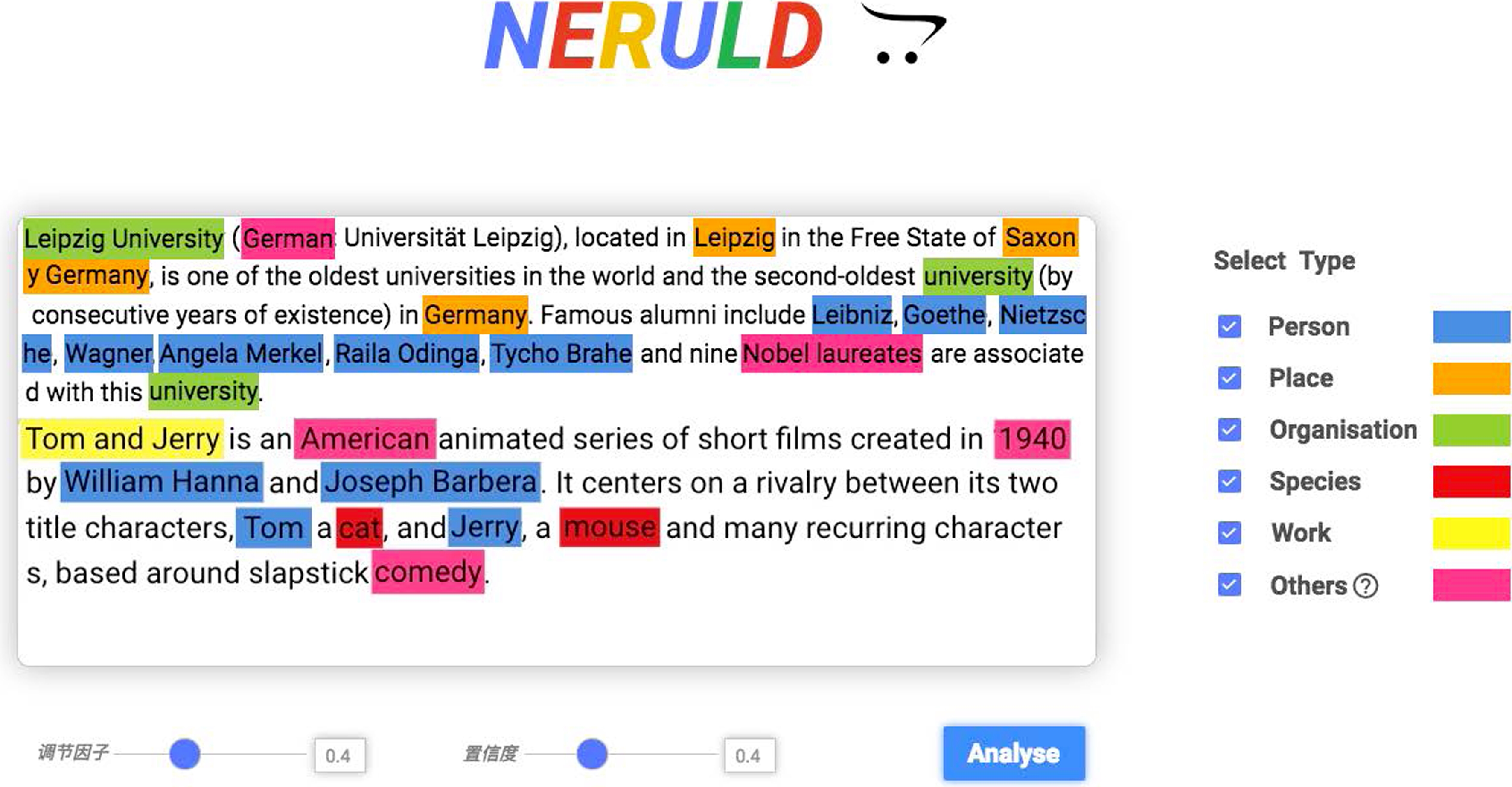
本文基于实现的命名实体识别算法设计了一个可配置的基于关联数据的中英文命名实体识别系统——NERULD,能够在一定程度上弥补现有系统的不足。
首先,利用NERULD提供的两个滑块,用户能够快速配置算法的两个重要参数——调节因子
其次,NERULD不仅能够提供如图5所示的类似现有命名实体识别系统的结果呈现形式,NERULD还能更进一步,通过点击识别结果,基于关联数据对识别结果进行属性描述,如图6中,点击识别结果“梅西”,NERULD目前能够返回其在DBpedia中的URI、label以及英文Abstract,后续将对属性描述进一步完善,对不同类型实体呈现不同类型内容,如Person实体展示其头像、国籍、职业、个人荣誉等信息,Place实体展示其GPS信息及其发生过的事件信息,Organisation实体展示其Logo、所属国家及主要成就等信息。
最后,NERULD不仅能够对识别结果进行描述,还支持对识别结果的扩展。通过点击图6中的“相关实体”选项,NERULD目前能够以图7所示的形式返回与该实体相关的其他4个实体及实体的英文label、英文摘要,后续将调整为用户配置的形式,让用户自定义扩展实体的数量,同时也将丰富对于扩展实体的属性描述。
对于扩展出的实体,点击实体右侧的“detail”选项,能够获取对于实体的属性描述,其结果与图6中对识别结果的描述相同。通过图6与图7之间的反复交互,系统实现了对识别结果的描述以及扩展,有效地弥补了现有命名实体识别系统在结果呈现上的不足。
-
5 总 结
本文实现的基于关联数据的命名实体识别算法和系统,能够充分发挥关联数据的优势,在一定程度上弥补现有命名实体识别的不足。
首先,能够充分发挥关联数据规模大、领域广、语种多的优势。通过对关联数据的解析和处理,将其转化为跨领域、跨语种的命名实体词典,能够节省人工构建实体词典的时间和精力,降低实体词典的构建难度,同时也在一定程度上提升了实体词典的可移植性,有效地弥补了基于规则的命名实体识别方法的不足。
其次,能够发挥关联数据语义链接丰富的优势。利用关联数据实体之间的链接关系构造关联数据实体网络,在命名实体识别的同时能够基于关联数据实体网络对实体的身份进行唯一性判别,能够降低消歧难度,提升消歧结果的解释性,实现命名实体识别与消歧的统一。
最后,能够充分发挥关联数据属性描述丰富的优势。利用关联数据中对实体属性的描述能够对识别结果进行更为详细的解释和描述,够弥补现有命名实体识别结果过于简单和单一的不足。
但是,现有研究依然存在不足需要后续研究中继续进行完善。
首先是对中文关联数据集的完善。尽管DBpedia数据集本身提供了对中文关联数据的支持,但是相较于英文关联数据,中文数据的数量很少、质量较低,后续将引入更多的中文关联数据集例如CN-DBpedia、Zhishi.me等对数据集进一步完善。
其次是对算法的完善。现有算法的执行速度较慢,匹配模式也过于机械,后续将对算法进一步的调整和优化,同时通过引入模式匹配的方式来解决匹配模式机械的不足。
最后是对系统的完善。目前实现的系统仅仅是原型系统,系统中的很多细节现在都只是简单的实现,需要在后续研究工作中不断改进和完善。
-
参考文献
-
1
Fafalios P, Baritakis M, Tzitzikas Y. Configuring named entity extraction through real-time exploitation of linked data[C]// Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics. New York: ACM Press, 2014: Article No. 10.
-
2
Mendes P N, Jakob M, García-Silva A, et al. DBpedia spotlight: shedding light on the web of documents[C]// Proceedings of the 7th International Conference on Semantic Systems. New York: ACM Press, 2011: 1-8.
-
3
Hakimov S, Oto S A, Dogdu E. Named entity recognition and disambiguation using linked data and graph-based centrality scoring[C]// Proceedings of the 4th International Workshop on Semantic Web Information Management. New York: ACM Press, 2012: Article No. 4.
-
4
Yosef M A, Hoffart J, Bordino I, et al. Aida: An online tool for accurate disambiguation of named entities in text and tables[J]. Proceedings of the VLDB Endowment, 2011, 4(12): 1450-1453.
-
5
Usbeck R, Ngomo A C N, Röder M, et al. AGDISTIS-graph-based disambiguation of named entities using linked data[C]// Proceedings of the International Semantic Web Conference. Heidelberg: Springer, 2014: 457-471.
-
6
Gangemi A, Presutti V, Reforgiato Recupero D, et al. Semantic web machine reading with FRED[J]. Semantic Web, 2017, 8(6): 873-893.
-
7
Nebhi K. Ontology-based information extraction from Twitter[C]// Proceedings of the Workshop on Information Extraction and Entity Analytics on Social Media Data, Mumbai, India, 2012: 17-22.
-
8
Maynard D, Peters W, Li Y Y. Evaluating evaluation metrics for ontology-based applications: Infinite reflection[C]// Proceedings of the International Conference on Language Resources and Evaluation, Marrakech, Morocco, 2010: 1045-1050.
-
9
Damljanovic D, Bontcheva K. Named entity disambiguation using linked data[C]// Proceedings of the 9th Extended Semantic Web Conference. 2012: 231-240.
-
10
Sinha R, Mihalcea R. Unsupervised graph-based word sense disambiguation using measures of word semantic similarity[C]//Proceedings of the International Conference on Semantic Computing, 2007, 7: 363-369.
-
11
Nebhi K. Named entity disambiguation using freebase and syntactic parsing[C]// Proceedings of the First International Conference on Linked Data for Information Extraction. Aachen: CEUR-WS, 2013, 1057: 50-55.
-
12
Usbeck R, Ngomo A C N, Luo W C, et al. Multilingual disambiguation of named entities using linked data[C]// Proceedings of the 2014 International Conference on Posters & Demonstrations Track. Aachen: CEUR-WS, 2014, 1272: 101-104.
-
1
摘要
命名实体识别是自然语言处理的基础性任务,其结果具有广泛的应用。关联数据由于具有丰富的语义知识,能够对现有命名实体识别进一步完善。本文实现了一个基于关联数据的可配置的中英文命名实体识别系统,在识别过程中对实体进行消歧并对识别结果进行扩展,为命名实体识别的进一步完善提供了新的思路。具体包括:基于DBpedia构造了跨领域的中英文命名实体词典;设计了一个基于Hive的分布式管理数据存储模型,基于该模型实现了对DBpedia数据集的组织、存储以及扩展;设计了一个基于图的命名实体识别算法,该算法能够充分利用关联数据的语义关系对命名实体进行消歧,并且基于DBpedia Spotlight NER Corpus对算法进行测试,并将算法结果与DBpedia Spotlight、NERSO以及Zwmanta三个系统进行对比评价,结果表明本文实现的算法在查全率、查准率、F值上具有更好的表现。
Abstract
Named Entity Recognition (NER) is a basic task in the field of Natural Language Processing with generalized applications. Because of plentiful semantic knowledge, Linked Data can improve the performance of NER. This paper realizes a configurable NER System called NERULD (Named Entity Recognition Using Linked Data) that can support Chinese and English texts and is based on Linked Data in order to disambiguate the recognized entities and to extend the results of NER, so that a new idea to improve the performance of NER can be provided. This study was conducted as follows. We first built a cross-domain Chinese named entity dictionary and English named entity dictionary using the DBpedia dataset. We then designed a distributed model based on Hive and Hadoop to organize, store, and extend Linked Data. We developed a graph-based algorithm to recognize and disambiguate named entities, which can make full use of the semantic relationships of Linked Data. We also tested our algorithm using the DBpedia Spotlight NER Corpus, and compared our result with DBpedia Spotlight, NERSO, and Zemanta, and found that the algorithm implemented in this paper has better performance in recall, precision, and F value.